- Follow up for: #540, #802
- Add API routes for user blocking from user and organization
perspective.
- The new routes have integration testing.
- The new model functions have unit tests.
- Actually quite boring to write and to read this pull request.
(cherry picked from commit f3afaf15c7)
(cherry picked from commit 6d754db3e5)
(cherry picked from commit d0fc8bc9d3)
(cherry picked from commit 9a53b0d1a0)
(cherry picked from commit 44a2a4fd48)
(cherry picked from commit 182025db9c)
(cherry picked from commit 558a35963e)
- Resolves#476
- Follow up for: #540
- Ensure that the doer and blocked person cannot follow each other.
- Ensure that the block person cannot watch doer's repositories.
- Add unblock button to the blocked user list.
- Add blocked since information to the blocked user list.
- Add extra testing to moderation code.
- Blocked user will unwatch doer's owned repository upon blocking.
- Add flash messages to let the user know the block/unblock action was successful.
- Add "You haven't blocked any users" message.
- Add organization blocking a user.
Co-authored-by: Gusted <postmaster@gusted.xyz>
Reviewed-on: https://codeberg.org/forgejo/forgejo/pulls/802
(cherry picked from commit 0505a10421)
(cherry picked from commit 37b4e6ef9b)
(cherry picked from commit 217475385a)
(cherry picked from commit f2c38ce5c2)
(cherry picked from commit 1edfb68137)
(cherry picked from commit 2cbc12dc74)
(cherry picked from commit 79ff020f18)
- Add the ability to block a user via their profile page.
- This will unstar their repositories and visa versa.
- Blocked users cannot create issues or pull requests on your the doer's repositories (mind that this is not the case for organizations).
- Blocked users cannot comment on the doer's opened issues or pull requests.
- Blocked users cannot add reactions to doer's comments.
- Blocked users cannot cause a notification trough mentioning the doer.
Reviewed-on: https://codeberg.org/forgejo/forgejo/pulls/540
(cherry picked from commit 687d852480)
(cherry picked from commit 0c32a4fde5)
(cherry picked from commit 1791130e3c)
(cherry picked from commit 00f411819f)
(cherry picked from commit e0c039b0e8)
(cherry picked from commit b5a058ef00)
(cherry picked from commit 5ff5460d28)
(cherry picked from commit 97bc6e619d)
(cherry picked from commit 20b5669269)
(cherry picked from commit 1574643a6a)
Update semantic version according to specification
(cherry picked from commit 22510f4130)
Mise à jour de 'Makefile'
(cherry picked from commit c3d85d8409)
(cherry picked from commit 5ea2309851)
(cherry picked from commit ec5217b9d1)
(cherry picked from commit 14f08e364b)
(cherry picked from commit b4465c67b8)
[API] [SEMVER] replace number with version
(cherry picked from commit fba48e6497)
(cherry picked from commit 532ec5d878)
[API] [SEMVER] [v1.20] less is replaced by css
(cherry picked from commit 01ca3a4f42)
(cherry picked from commit 1d928c3ab2)
(cherry picked from commit a39dc804cd)
Conflicts:
webpack.config.js
(cherry picked from commit adc68578b3)
(cherry picked from commit 9b8d98475f)
(cherry picked from commit 2516103974)
(cherry picked from commit 18e6287963)
(cherry picked from commit e9694e67ab)
(cherry picked from commit a9763edaf0)
(cherry picked from commit e2b550f4fb)
(cherry picked from commit 2edac36701)
[API] Forgejo API /api/forgejo/v1 (squash)
Update semver as v1.20 is entering release candidate mode
(cherry picked from commit 4995098ec3)
(cherry picked from commit 3dd6f2862e)
(cherry picked from commit e8192737ef)
(cherry picked from commit 7b1245cc70)
(cherry picked from commit 4d7cd59703)
(cherry picked from commit 7a7a293dbd)
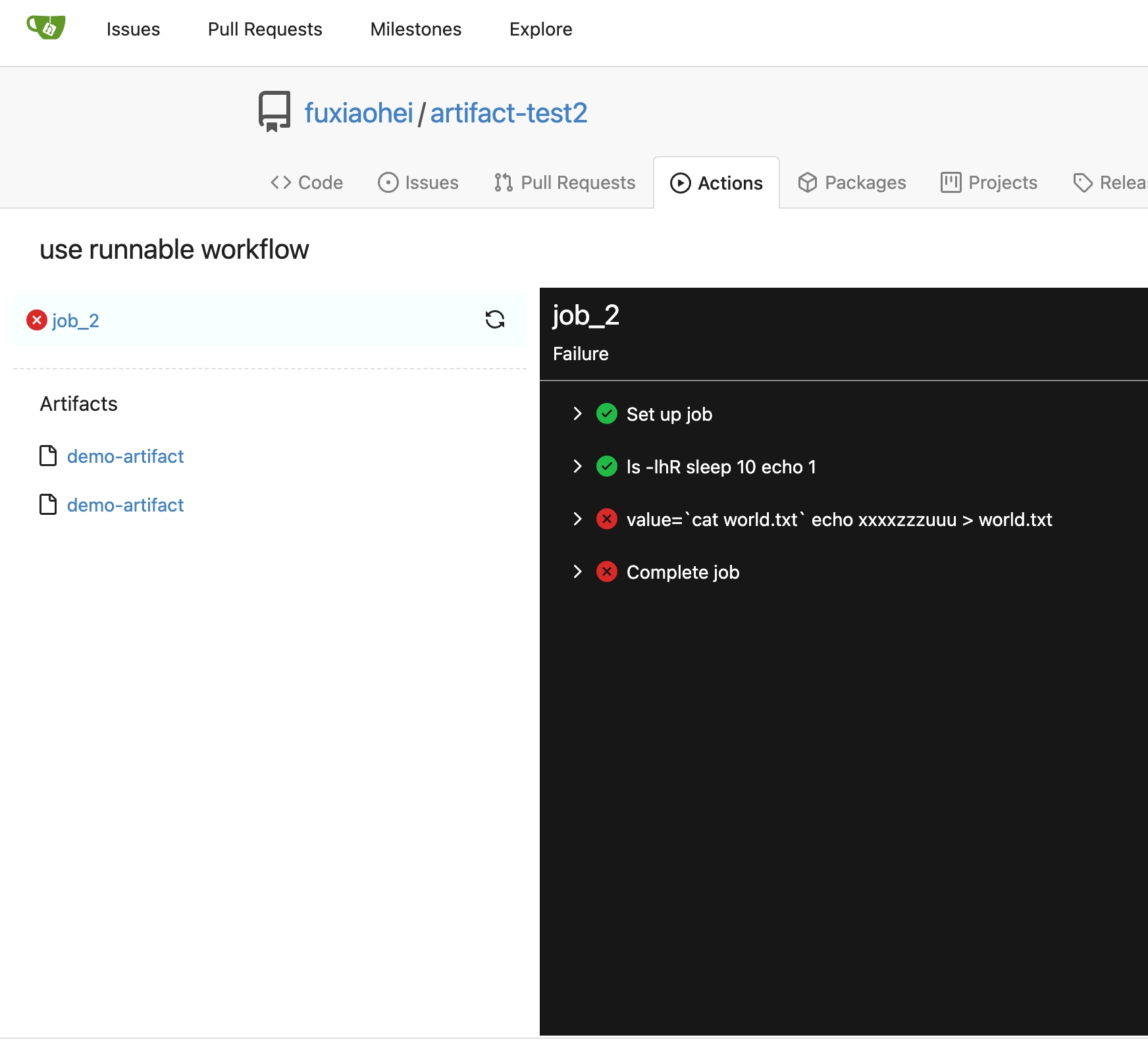
Backport #25701 by @CaiCandong
we refactored `userIDFromToken` for the token parsing part into a new
function `parseToken`. `parseToken` returns the string `token` from
request, and a boolean `ok` representing whether the token exists or
not. So we can distinguish between token non-existence and token
inconsistency in the `verfity` function, thus solving the problem of no
proper error message when the token is inconsistent.
close#24439
related #22119
Co-authored-by: caicandong <50507092+CaiCandong@users.noreply.github.com>
Co-authored-by: Jason Song <i@wolfogre.com>
Backport #25707 by @KN4CK3R
Fixes (?) #25538
Fixes https://codeberg.org/forgejo/forgejo/issues/972
Regression #23879#23879 introduced a change which prevents read access to packages if a
user is not a member of an organization.
That PR also contained a change which disallows package access if the
team unit is configured with "no access" for packages. I don't think
this change makes sense (at the moment). It may be relevant for private
orgs. But for public or limited orgs that's useless because an
unauthorized user would have more access rights than the team member.
This PR restores the old behaviour "If a user has read access for an
owner, they can read packages".
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Backport #22759 by @KN4CK3R
related #16865
This PR adds an accessibility check before mounting container blobs.
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Co-authored-by: silverwind <me@silverwind.io>
Backport #25278 by @Zettat123
Fix#21072

Username Attribute is not a required item when creating an
authentication source. If Username Attribute is empty, the username
value of LDAP user cannot be read, so all users from LDAP will be marked
as inactive by mistake when synchronizing external users.
This PR improves the sync logic, if username is empty, the email address
will be used to find user.
Co-authored-by: Zettat123 <zettat123@gmail.com>
## Changes
- Adds the following high level access scopes, each with `read` and
`write` levels:
- `activitypub`
- `admin` (hidden if user is not a site admin)
- `misc`
- `notification`
- `organization`
- `package`
- `issue`
- `repository`
- `user`
- Adds new middleware function `tokenRequiresScopes()` in addition to
`reqToken()`
- `tokenRequiresScopes()` is used for each high-level api section
- _if_ a scoped token is present, checks that the required scope is
included based on the section and HTTP method
- `reqToken()` is used for individual routes
- checks that required authentication is present (but does not check
scope levels as this will already have been handled by
`tokenRequiresScopes()`
- Adds migration to convert old scoped access tokens to the new set of
scopes
- Updates the user interface for scope selection
### User interface example
<img width="903" alt="Screen Shot 2023-05-31 at 1 56 55 PM"
src="https://github.com/go-gitea/gitea/assets/23248839/654766ec-2143-4f59-9037-3b51600e32f3">
<img width="917" alt="Screen Shot 2023-05-31 at 1 56 43 PM"
src="https://github.com/go-gitea/gitea/assets/23248839/1ad64081-012c-4a73-b393-66b30352654c">
## tokenRequiresScopes Design Decision
- `tokenRequiresScopes()` was added to more reliably cover api routes.
For an incoming request, this function uses the given scope category
(say `AccessTokenScopeCategoryOrganization`) and the HTTP method (say
`DELETE`) and verifies that any scoped tokens in use include
`delete:organization`.
- `reqToken()` is used to enforce auth for individual routes that
require it. If a scoped token is not present for a request,
`tokenRequiresScopes()` will not return an error
## TODO
- [x] Alphabetize scope categories
- [x] Change 'public repos only' to a radio button (private vs public).
Also expand this to organizations
- [X] Disable token creation if no scopes selected. Alternatively, show
warning
- [x] `reqToken()` is missing from many `POST/DELETE` routes in the api.
`tokenRequiresScopes()` only checks that a given token has the correct
scope, `reqToken()` must be used to check that a token (or some other
auth) is present.
- _This should be addressed in this PR_
- [x] The migration should be reviewed very carefully in order to
minimize access changes to existing user tokens.
- _This should be addressed in this PR_
- [x] Link to api to swagger documentation, clarify what
read/write/delete levels correspond to
- [x] Review cases where more than one scope is needed as this directly
deviates from the api definition.
- _This should be addressed in this PR_
- For example:
```go
m.Group("/users/{username}/orgs", func() {
m.Get("", reqToken(), org.ListUserOrgs)
m.Get("/{org}/permissions", reqToken(), org.GetUserOrgsPermissions)
}, tokenRequiresScopes(auth_model.AccessTokenScopeCategoryUser,
auth_model.AccessTokenScopeCategoryOrganization),
context_service.UserAssignmentAPI())
```
## Future improvements
- [ ] Add required scopes to swagger documentation
- [ ] Redesign `reqToken()` to be opt-out rather than opt-in
- [ ] Subdivide scopes like `repository`
- [ ] Once a token is created, if it has no scopes, we should display
text instead of an empty bullet point
- [ ] If the 'public repos only' option is selected, should read
categories be selected by default
Closes#24501Closes#24799
Co-authored-by: Jonathan Tran <jon@allspice.io>
Co-authored-by: Kyle D <kdumontnu@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
The PKCE flow according to [RFC
7636](https://datatracker.ietf.org/doc/html/rfc7636) allows for secure
authorization without the requirement to provide a client secret for the
OAuth app.
It is implemented in Gitea since #5378 (v1.8.0), however without being
able to omit client secret.
Since #21316 Gitea supports setting client type at OAuth app
registration.
As public clients are already forced to use PKCE since #21316, in this
PR the client secret check is being skipped if a public client is
detected. As Gitea seems to implement PKCE authorization correctly
according to the spec, this would allow for PKCE flow without providing
a client secret.
Also add some docs for it, please check language as I'm not a native
English speaker.
Closes#17107Closes#25047
The admin config page has been broken for many many times, a little
refactoring would make this page panic.
So, add a test for it, and add another test to cover the 500 error page.
Co-authored-by: Giteabot <teabot@gitea.io>
This PR creates an API endpoint for creating/updating/deleting multiple
files in one API call similar to the solution provided by
[GitLab](https://docs.gitlab.com/ee/api/commits.html#create-a-commit-with-multiple-files-and-actions).
To archive this, the CreateOrUpdateRepoFile and DeleteRepoFIle functions
in files service are unified into one function supporting multiple files
and actions.
Resolves#14619
This adds the ability to pin important Issues and Pull Requests. You can
also move pinned Issues around to change their Position. Resolves#2175.
## Screenshots
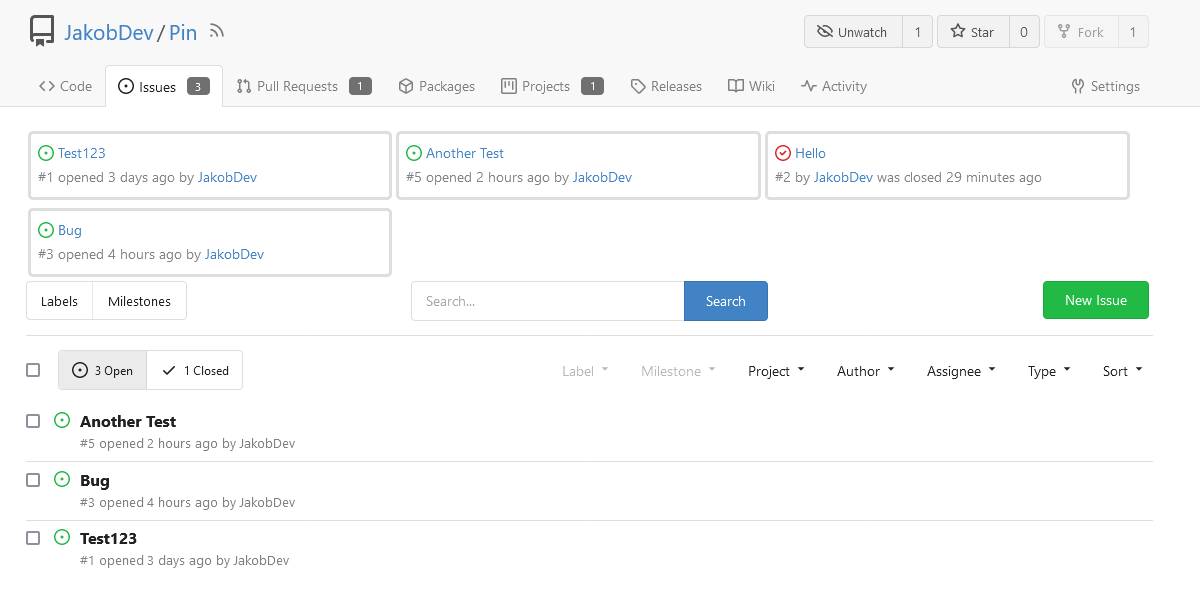
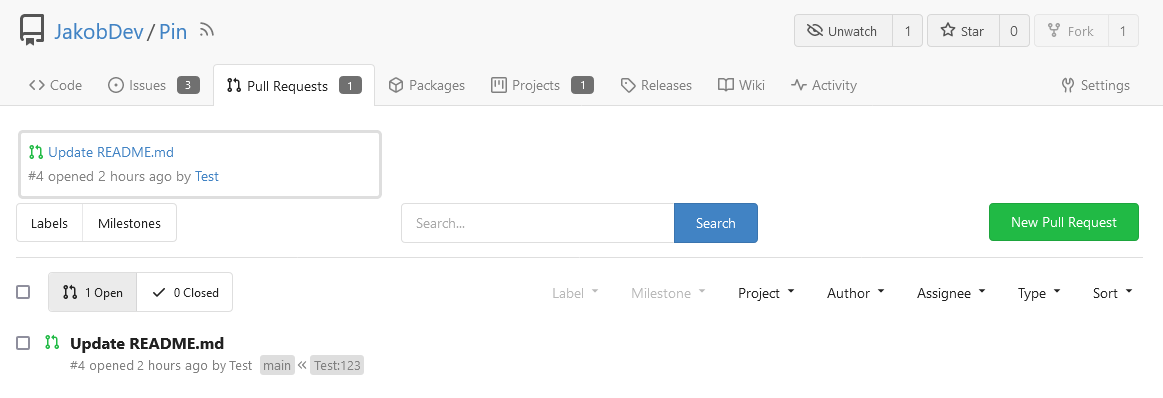
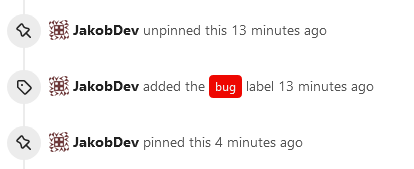
The Design was mostly copied from the Projects Board.
## Implementation
This uses a new `pin_order` Column in the `issue` table. If the value is
set to 0, the Issue is not pinned. If it's set to a bigger value, the
value is the Position. 1 means it's the first pinned Issue, 2 means it's
the second one etc. This is dived into Issues and Pull requests for each
Repo.
## TODO
- [x] You can currently pin as many Issues as you want. Maybe we should
add a Limit, which is configurable. GitHub uses 3, but I prefer 6, as
this is better for bigger Projects, but I'm open for suggestions.
- [x] Pin and Unpin events need to be added to the Issue history.
- [x] Tests
- [x] Migration
**The feature itself is currently fully working, so tester who may find
weird edge cases are very welcome!**
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
## ⚠️ Breaking
The `log.<mode>.<logger>` style config has been dropped. If you used it,
please check the new config manual & app.example.ini to make your
instance output logs as expected.
Although many legacy options still work, it's encouraged to upgrade to
the new options.
The SMTP logger is deleted because SMTP is not suitable to collect logs.
If you have manually configured Gitea log options, please confirm the
logger system works as expected after upgrading.
## Description
Close#12082 and maybe more log-related issues, resolve some related
FIXMEs in old code (which seems unfixable before)
Just like rewriting queue #24505 : make code maintainable, clear legacy
bugs, and add the ability to support more writers (eg: JSON, structured
log)
There is a new document (with examples): `logging-config.en-us.md`
This PR is safer than the queue rewriting, because it's just for
logging, it won't break other logic.
## The old problems
The logging system is quite old and difficult to maintain:
* Unclear concepts: Logger, NamedLogger, MultiChannelledLogger,
SubLogger, EventLogger, WriterLogger etc
* Some code is diffuclt to konw whether it is right:
`log.DelNamedLogger("console")` vs `log.DelNamedLogger(log.DEFAULT)` vs
`log.DelLogger("console")`
* The old system heavily depends on ini config system, it's difficult to
create new logger for different purpose, and it's very fragile.
* The "color" trick is difficult to use and read, many colors are
unnecessary, and in the future structured log could help
* It's difficult to add other log formats, eg: JSON format
* The log outputer doesn't have full control of its goroutine, it's
difficult to make outputer have advanced behaviors
* The logs could be lost in some cases: eg: no Fatal error when using
CLI.
* Config options are passed by JSON, which is quite fragile.
* INI package makes the KEY in `[log]` section visible in `[log.sub1]`
and `[log.sub1.subA]`, this behavior is quite fragile and would cause
more unclear problems, and there is no strong requirement to support
`log.<mode>.<logger>` syntax.
## The new design
See `logger.go` for documents.
## Screenshot
<details>



</details>
## TODO
* [x] add some new tests
* [x] fix some tests
* [x] test some sub-commands (manually ....)
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Giteabot <teabot@gitea.io>
This PR is a refactor at the beginning. And now it did 4 things.
- [x] Move renaming organizaiton and user logics into services layer and
merged as one function
- [x] Support rename a user capitalization only. For example, rename the
user from `Lunny` to `lunny`. We just need to change one table `user`
and others should not be touched.
- [x] Before this PR, some renaming were missed like `agit`
- [x] Fix bug the API reutrned from `http.StatusNoContent` to `http.StatusOK`
fix#12192 Support SSH for go get
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Giteabot <teabot@gitea.io>
Co-authored-by: mfk <mfk@hengwei.com.cn>
Co-authored-by: silverwind <me@silverwind.io>
Fixes#24145
To solve the bug, I added a "computed" `TargetBehind` field to the
`Release` model, which indicates the target branch of a release.
This is particularly useful if the target branch was deleted in the
meantime (or is empty).
I also did a micro-optimization in `calReleaseNumCommitsBehind`. Instead
of checking that a branch exists and then call `GetBranchCommit`, I
immediately call `GetBranchCommit` and handle the `git.ErrNotExist`
error.
This optimization is covered by the added unit test.
The `GetAllCommits` endpoint can be pretty slow, especially in repos
with a lot of commits. The issue is that it spends a lot of time
calculating information that may not be useful/needed by the user.
The `stat` param was previously added in #21337 to address this, by
allowing the user to disable the calculating stats for each commit. But
this has two issues:
1. The name `stat` is rather misleading, because disabling `stat`
disables the Stat **and** Files. This should be separated out into two
different params, because getting a list of affected files is much less
expensive than calculating the stats
2. There's still other costly information provided that the user may not
need, such as `Verification`
This PR, adds two parameters to the endpoint, `files` and `verification`
to allow the user to explicitly disable this information when listing
commits. The default behavior is true.
This fixes up https://github.com/go-gitea/gitea/pull/10446; in that, the
*expected* timezone was changed to the local timezone, but the computed
timezone was left in UTC.
The result was this failure, when run on a non-UTC system:
```
Diff:
--- Expected
+++ Actual
@@ -5,3 +5,3 @@
commitMsg: (string) (len=12) "init project",
- commitTime: (string) (len=29) "Wed, 14 Jun 2017 09:54:21 EDT"
+ commitTime: (string) (len=29) "Wed, 14 Jun 2017 13:54:21 UTC"
},
@@ -11,3 +11,3 @@
commitMsg: (string) (len=12) "init project",
- commitTime: (string) (len=29) "Wed, 14 Jun 2017 09:54:21 EDT"
+ commitTime: (string) (len=29) "Wed, 14 Jun 2017 13:54:21 UTC"
}
Test: TestViewRepo2
```
I assume this was probably missed since the CI servers all run in UTC?
The Format() string "Mon, 02 Jan 2006 15:04:05 UTC" was incorrect: 'UTC'
isn't recognized as a variable placeholder, but was just being copied
verbatim. It should use 'MST' in order to command Format() to output the
attached timezone, which is what `time.RFC1123` has.
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

Due to #24409 , we can now specify '--not' when getting all commits from
a repo to exclude commits from a different branch.
When I wrote that PR, I forgot to also update the code that counts the
number of commits in the repo. So now, if the --not option is used, it
may return too many commits, which can indicate that another page of
data is available when it is not.
This PR passes --not to the commands that count the number of commits in
a repo
This gives more "freshness" to the explore page. So it's not just the
same X users on the explore page by default, now it matches the same
sort as the repos on the explore page.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}