Although some features are mixed together in this PR, this PR is not
that large, and these features are all related.
Actually there are more than 70 lines are for a toy "test queue", so
this PR is quite simple.
Major features:
1. Allow site admin to clear a queue (remove all items in a queue)
* Because there is no transaction, the "unique queue" could be corrupted
in rare cases, that's unfixable.
* eg: the item is in the "set" but not in the "list", so the item would
never be able to be pushed into the queue.
* Now site admin could simply clear the queue, then everything becomes
correct, the lost items could be re-pushed into queue by future
operations.
3. Split the "admin/monitor" to separate pages
4. Allow to download diagnosis report
* In history, there were many users reporting that Gitea queue gets
stuck, or Gitea's CPU is 100%
* With diagnosis report, maintainers could know what happens clearly
The diagnosis report sample:
[gitea-diagnosis-20230510-192913.zip](https://github.com/go-gitea/gitea/files/11441346/gitea-diagnosis-20230510-192913.zip)
, use "go tool pprof profile.dat" to view the report.
Screenshots:
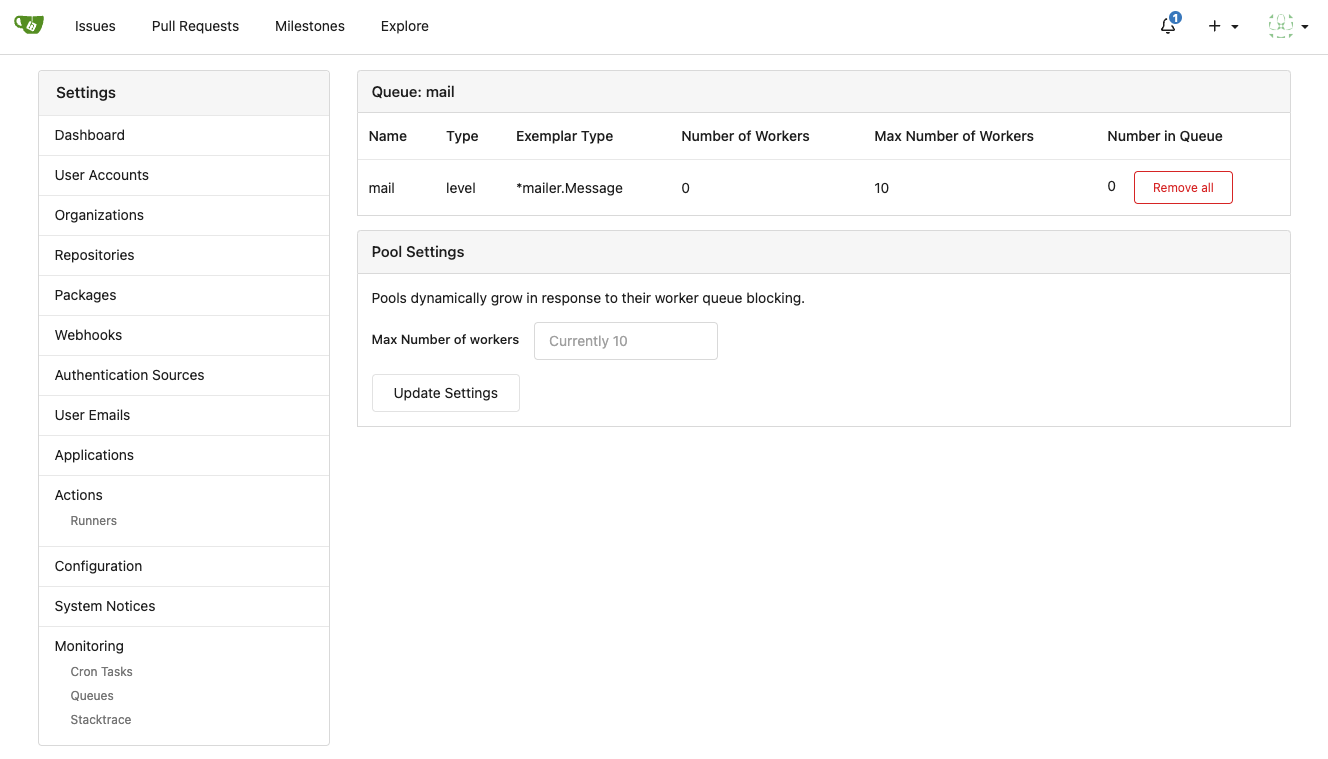
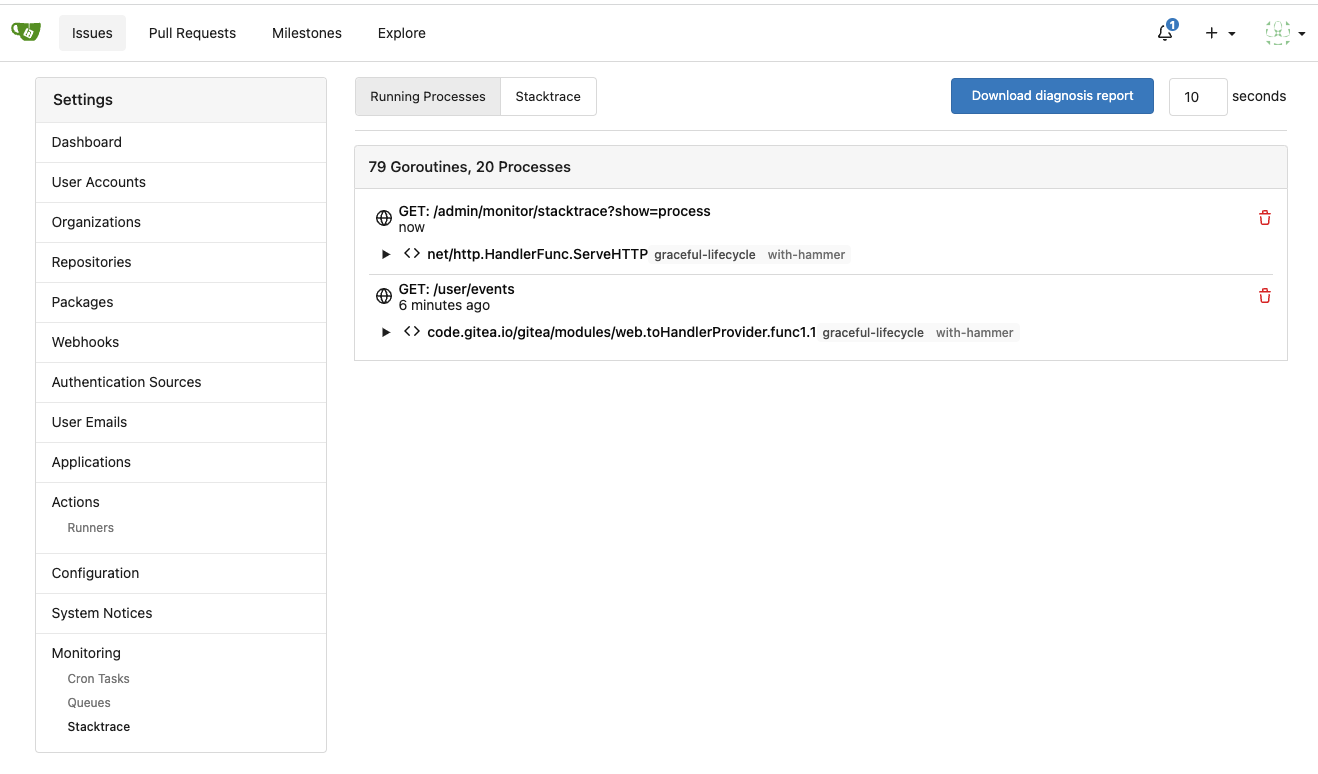

---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: Giteabot <teabot@gitea.io>
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

Change all license headers to comply with REUSE specification.
Fix#16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Add number in queue status to the monitor page so that administrators can
assess how much work is left to be done in the queues.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* Only attempt to flush queue if the underlying worker pool is not finished
There is a possible race whereby a worker pool could be cancelled but yet the
underlying queue is not empty. This will lead to flush-all cycling because it
cannot empty the pool.
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Apply suggestions from code review
Co-authored-by: Gusted <williamzijl7@hotmail.com>
Co-authored-by: Gusted <williamzijl7@hotmail.com>
* Start adding mechanism to return unhandled data
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Create pushback interface
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Add Pausable interface to WorkerPool and Manager
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Implement Pausable and PushBack for the bytefifos
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Implement Pausable and Pushback for ChannelQueues and ChannelUniqueQueues
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Wire in UI for pausing
Signed-off-by: Andrew Thornton <art27@cantab.net>
* add testcases and fix a few issues
Signed-off-by: Andrew Thornton <art27@cantab.net>
* fix build
Signed-off-by: Andrew Thornton <art27@cantab.net>
* prevent "race" in the test
Signed-off-by: Andrew Thornton <art27@cantab.net>
* fix jsoniter mismerge
Signed-off-by: Andrew Thornton <art27@cantab.net>
* fix conflicts
Signed-off-by: Andrew Thornton <art27@cantab.net>
* fix format
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Add warnings for no worker configurations and prevent data-loss with redis/levelqueue
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Use StopTimer
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* Timeout on flush in testing
At the end of each test the queues are flushed. At present there is no limit on the
length of time a flush can take which can lead to long flushes.
However, if the CI task is cancelled we lose the log information as to where the long
flush was taking place.
This PR simply adds a default time limit of 2 minutes - at which point an error will
be produced. This should allow us to more easily find the culprit.
Signed-off-by: Andrew Thornton <art27@cantab.net>
* return better error
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
* move shutdownfns, terminatefns and hammerfns out of separate goroutines
Coalesce the shutdownfns etc into a list of functions that get run at shutdown
rather then have them run at goroutines blocked on selects.
This may help reduce the background select/poll load in certain
configurations.
* The LevelDB queues can actually wait on empty instead of polling
Slight refactor to cause leveldb queues to wait on empty instead of polling.
* Shutdown the shadow level queue once it is empty
* Remove bytefifo additional goroutine for readToChan as it can just be run in run
* Remove additional removeWorkers goroutine for workers
* Simplify the AtShutdown and AtTerminate functions and add Channel Flusher
* Add shutdown flusher to CUQ
* move persistable channel shutdown stuff to Shutdown Fn
* Ensure that UPCQ has the correct config
* handle shutdown during the flushing
* reduce risk of race between zeroBoost and addWorkers
* prevent double shutdown
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Queue manager FlushAll can loop rapidly - add delay
Add delay within FlushAll to prevent rapid loop when workers are busy
Signed-off-by: Andrew Thornton <art27@cantab.net>
* as per lunny
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
The issue is that the TestPatch will reset the PR MergeBase - and it is possible for TestPatch to update the MergeBase whilst a merge is ongoing. The ensuing merge will then complete but it doesn't re-set the MergeBase it used to merge the PR.
Fixes the intermittent error in git test.
Signed-off-by: Andrew Thornton art27@cantab.net
* go function contexting is not what you expect
* Apply suggestions from code review
Co-Authored-By: Lauris BH <lauris@nix.lv>
Co-authored-by: Lauris BH <lauris@nix.lv>
* Make WorkerPools and Queues flushable
Adds Flush methods to Queues and the WorkerPool
Further abstracts the WorkerPool
Adds a final step to Flush the queues in the defer from PrintCurrentTest
Fixes an issue with Settings inheritance in queues
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Change to for loop
* Add IsEmpty and begin just making the queues composed WorkerPools
* subsume workerpool into the queues and create a flushable interface
* Add manager command
* Move flushall to queue.Manager and add to testlogger
* As per @guillep2k
* as per @guillep2k
* Just make queues all implement flushable and clean up the wrapped queue flushes
* cope with no timeout
Co-authored-by: Lauris BH <lauris@nix.lv>
{kind=link}