mirror of
https://github.com/go-gitea/gitea
synced 2024-11-09 03:21:45 +01:00
Before, the `GiteaLocaleNumber.js` was just written as a a drop-in replacement for old `js-pretty-number`. Actually, we can use Golang's `text` package to format. This PR partially completes the TODOs in `GiteaLocaleNumber.js`: > if we have complete backend locale support (eg: Golang "x/text" package), we can drop this component. > tooltip: only 2 usages of this, we can replace it with Golang's "x/text/number" package in the future. This PR also helps #24131 Screenshots: <details> 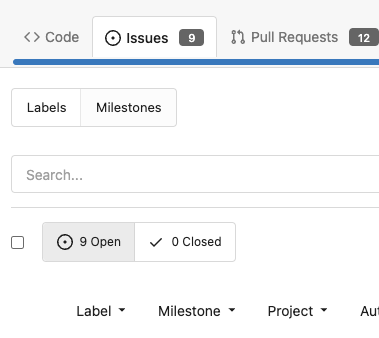 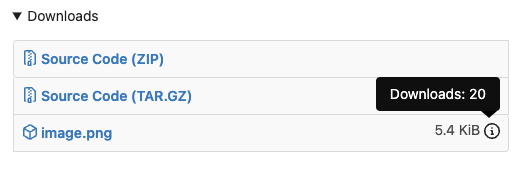 </details>
{kind=link}
{kind=link}
589 lines
15 KiB
Go
589 lines
15 KiB
Go
// Copyright 2021 The Gitea Authors. All rights reserved.
|
|
// SPDX-License-Identifier: MIT
|
|
|
|
package csv
|
|
|
|
import (
|
|
"bytes"
|
|
"encoding/csv"
|
|
"io"
|
|
"strconv"
|
|
"strings"
|
|
"testing"
|
|
|
|
"code.gitea.io/gitea/modules/git"
|
|
"code.gitea.io/gitea/modules/markup"
|
|
"code.gitea.io/gitea/modules/translation"
|
|
|
|
"github.com/stretchr/testify/assert"
|
|
)
|
|
|
|
func TestCreateReader(t *testing.T) {
|
|
rd := CreateReader(bytes.NewReader([]byte{}), ',')
|
|
assert.Equal(t, ',', rd.Comma)
|
|
}
|
|
|
|
func decodeSlashes(t *testing.T, s string) string {
|
|
s = strings.ReplaceAll(s, "\n", "\\n")
|
|
s = strings.ReplaceAll(s, "\"", "\\\"")
|
|
decoded, err := strconv.Unquote(`"` + s + `"`)
|
|
assert.NoError(t, err, "unable to decode string")
|
|
return decoded
|
|
}
|
|
|
|
func TestCreateReaderAndDetermineDelimiter(t *testing.T) {
|
|
cases := []struct {
|
|
csv string
|
|
expectedRows [][]string
|
|
expectedDelimiter rune
|
|
}{
|
|
// case 0 - semicolon delimited
|
|
{
|
|
csv: `a;b;c
|
|
1;2;3
|
|
4;5;6`,
|
|
expectedRows: [][]string{
|
|
{"a", "b", "c"},
|
|
{"1", "2", "3"},
|
|
{"4", "5", "6"},
|
|
},
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 1 - tab delimited with empty fields
|
|
{
|
|
csv: `col1 col2 col3
|
|
a, b c
|
|
e f
|
|
g h i
|
|
j l
|
|
m n,\t
|
|
p q r
|
|
u
|
|
v w x
|
|
y\t\t
|
|
`,
|
|
expectedRows: [][]string{
|
|
{"col1", "col2", "col3"},
|
|
{"a,", "b", "c"},
|
|
{"", "e", "f"},
|
|
{"g", "h", "i"},
|
|
{"j", "", "l"},
|
|
{"m", "n,", ""},
|
|
{"p", "q", "r"},
|
|
{"", "", "u"},
|
|
{"v", "w", "x"},
|
|
{"y", "", ""},
|
|
{"", "", ""},
|
|
},
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 2 - comma delimited with leading spaces
|
|
{
|
|
csv: ` col1,col2,col3
|
|
a, b, c
|
|
d,e,f
|
|
,h, i
|
|
j, ,\x20
|
|
, , `,
|
|
expectedRows: [][]string{
|
|
{"col1", "col2", "col3"},
|
|
{"a", "b", "c"},
|
|
{"d", "e", "f"},
|
|
{"", "h", "i"},
|
|
{"j", "", ""},
|
|
{"", "", ""},
|
|
},
|
|
expectedDelimiter: ',',
|
|
},
|
|
}
|
|
|
|
for n, c := range cases {
|
|
rd, err := CreateReaderAndDetermineDelimiter(nil, strings.NewReader(decodeSlashes(t, c.csv)))
|
|
assert.NoError(t, err, "case %d: should not throw error: %v\n", n, err)
|
|
assert.EqualValues(t, c.expectedDelimiter, rd.Comma, "case %d: delimiter should be '%c', got '%c'", n, c.expectedDelimiter, rd.Comma)
|
|
rows, err := rd.ReadAll()
|
|
assert.NoError(t, err, "case %d: should not throw error: %v\n", n, err)
|
|
assert.EqualValues(t, c.expectedRows, rows, "case %d: rows should be equal", n)
|
|
}
|
|
}
|
|
|
|
type mockReader struct{}
|
|
|
|
func (r *mockReader) Read(buf []byte) (int, error) {
|
|
return 0, io.ErrShortBuffer
|
|
}
|
|
|
|
func TestDetermineDelimiterShortBufferError(t *testing.T) {
|
|
rd, err := CreateReaderAndDetermineDelimiter(nil, &mockReader{})
|
|
assert.Error(t, err, "CreateReaderAndDetermineDelimiter() should throw an error")
|
|
assert.ErrorIs(t, err, io.ErrShortBuffer)
|
|
assert.Nil(t, rd, "CSV reader should be mnil")
|
|
}
|
|
|
|
func TestDetermineDelimiterReadAllError(t *testing.T) {
|
|
rd, err := CreateReaderAndDetermineDelimiter(nil, strings.NewReader(`col1,col2
|
|
a;b
|
|
c@e
|
|
f g
|
|
h|i
|
|
jkl`))
|
|
assert.NoError(t, err, "CreateReaderAndDetermineDelimiter() shouldn't throw error")
|
|
assert.NotNil(t, rd, "CSV reader should not be mnil")
|
|
rows, err := rd.ReadAll()
|
|
assert.Error(t, err, "RaadAll() should throw error")
|
|
assert.ErrorIs(t, err, csv.ErrFieldCount)
|
|
assert.Empty(t, rows, "rows should be empty")
|
|
}
|
|
|
|
func TestDetermineDelimiter(t *testing.T) {
|
|
cases := []struct {
|
|
csv string
|
|
filename string
|
|
expectedDelimiter rune
|
|
}{
|
|
// case 0 - semicolon delmited
|
|
{
|
|
csv: "a",
|
|
filename: "test.csv",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 1 - single column/row CSV
|
|
{
|
|
csv: "a",
|
|
filename: "",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 2 - single column, single row CSV w/ tsv file extension (so is tabbed delimited)
|
|
{
|
|
csv: "1,2",
|
|
filename: "test.tsv",
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 3 - two column, single row CSV w/ no filename, so will guess comma as delimiter
|
|
{
|
|
csv: "1,2",
|
|
filename: "",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 4 - semi-colon delimited with csv extension
|
|
{
|
|
csv: "1;2",
|
|
filename: "test.csv",
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 5 - tabbed delimited with tsv extension
|
|
{
|
|
csv: "1\t2",
|
|
filename: "test.tsv",
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 6 - tabbed delimited without any filename
|
|
{
|
|
csv: "1\t2",
|
|
filename: "",
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 7 - tabs won't work, only commas as every row has same amount of commas
|
|
{
|
|
csv: "col1,col2\nfirst\tval,seconed\tval",
|
|
filename: "",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 8 - While looks like comma delimited, has psv extension
|
|
{
|
|
csv: "1,2",
|
|
filename: "test.psv",
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 9 - pipe delmiited with no extension
|
|
{
|
|
csv: "1|2",
|
|
filename: "",
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 10 - semi-colon delimited with commas in values
|
|
{
|
|
csv: "1,2,3;4,5,6;7,8,9\na;b;c",
|
|
filename: "",
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 11 - semi-colon delimited with newline in content
|
|
{
|
|
csv: `"1,2,3,4";"a
|
|
b";%
|
|
c;d;#`,
|
|
filename: "",
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 12 - HTML as single value
|
|
{
|
|
csv: "<br/>",
|
|
filename: "",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 13 - tab delimited with commas in values
|
|
{
|
|
csv: `name email note
|
|
John Doe john@doe.com This,note,had,a,lot,of,commas,to,test,delimiters`,
|
|
filename: "",
|
|
expectedDelimiter: '\t',
|
|
},
|
|
}
|
|
|
|
for n, c := range cases {
|
|
delimiter := determineDelimiter(&markup.RenderContext{
|
|
Ctx: git.DefaultContext,
|
|
RelativePath: c.filename,
|
|
}, []byte(decodeSlashes(t, c.csv)))
|
|
assert.EqualValues(t, c.expectedDelimiter, delimiter, "case %d: delimiter should be equal, expected '%c' got '%c'", n, c.expectedDelimiter, delimiter)
|
|
}
|
|
}
|
|
|
|
func TestRemoveQuotedString(t *testing.T) {
|
|
cases := []struct {
|
|
text string
|
|
expectedText string
|
|
}{
|
|
// case 0 - quoted text with escaped quotes in 1st column
|
|
{
|
|
text: `col1,col2,col3
|
|
"quoted ""text"" with
|
|
new lines
|
|
in first column",b,c`,
|
|
expectedText: `col1,col2,col3
|
|
,b,c`,
|
|
},
|
|
// case 1 - quoted text with escaped quotes in 2nd column
|
|
{
|
|
text: `col1,col2,col3
|
|
a,"quoted ""text"" with
|
|
new lines
|
|
in second column",c`,
|
|
expectedText: `col1,col2,col3
|
|
a,,c`,
|
|
},
|
|
// case 2 - quoted text with escaped quotes in last column
|
|
{
|
|
text: `col1,col2,col3
|
|
a,b,"quoted ""text"" with
|
|
new lines
|
|
in last column"`,
|
|
expectedText: `col1,col2,col3
|
|
a,b,`,
|
|
},
|
|
// case 3 - csv with lots of quotes
|
|
{
|
|
text: `a,"b",c,d,"e
|
|
e
|
|
e",f
|
|
a,bb,c,d,ee ,"f
|
|
f"
|
|
a,b,"c ""
|
|
c",d,e,f`,
|
|
expectedText: `a,,c,d,,f
|
|
a,bb,c,d,ee ,
|
|
a,b,,d,e,f`,
|
|
},
|
|
// case 4 - csv with pipes and quotes
|
|
{
|
|
text: `Col1 | Col2 | Col3
|
|
abc | "Hello
|
|
World"|123
|
|
"de
|
|
|
|
f" | 4.56 | 789`,
|
|
expectedText: `Col1 | Col2 | Col3
|
|
abc | |123
|
|
| 4.56 | 789`,
|
|
},
|
|
}
|
|
|
|
for n, c := range cases {
|
|
modifiedText := removeQuotedString(decodeSlashes(t, c.text))
|
|
assert.EqualValues(t, c.expectedText, modifiedText, "case %d: modified text should be equal", n)
|
|
}
|
|
}
|
|
|
|
func TestGuessDelimiter(t *testing.T) {
|
|
cases := []struct {
|
|
csv string
|
|
expectedDelimiter rune
|
|
}{
|
|
// case 0 - single cell, comma delmited
|
|
{
|
|
csv: "a",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 1 - two cells, comma delimited
|
|
{
|
|
csv: "1,2",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 2 - semicolon delimited
|
|
{
|
|
csv: "1;2",
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 3 - tab delimited
|
|
{
|
|
csv: "1\t2",
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 4 - pipe delimited
|
|
{
|
|
csv: "1|2",
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 5 - semicolon delimited with commas in text
|
|
{
|
|
csv: `1,2,3;4,5,6;7,8,9
|
|
a;b;c`,
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 6 - semicolon delmited with commas in quoted text
|
|
{
|
|
csv: `"1,2,3,4";"a
|
|
b"
|
|
c;d`,
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 7 - HTML
|
|
{
|
|
csv: "<br/>",
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 8 - tab delimited with commas in value
|
|
{
|
|
csv: `name email note
|
|
John Doe john@doe.com This,note,had,a,lot,of,commas,to,test,delimiters`,
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 9 - tab delimited with new lines in values, commas in values
|
|
{
|
|
csv: `1 "some,""more
|
|
""
|
|
quoted,
|
|
text," a
|
|
2 "some,
|
|
quoted,\t
|
|
text," b
|
|
3 "some,
|
|
quoted,
|
|
text" c
|
|
4 "some,
|
|
quoted,
|
|
text," d`,
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 10 - semicolon delmited with quotes and semicolon in value
|
|
{
|
|
csv: `col1;col2
|
|
"this has a literal "" in the text";"and an ; in the text"`,
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 11 - pipe delimited with quotes
|
|
{
|
|
csv: `Col1 | Col2 | Col3
|
|
abc | "Hello
|
|
World"|123
|
|
"de
|
|
|
|
|
f" | 4.56 | 789`,
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 12 - a tab delimited 6 column CSV, but the values are not quoted and have lots of commas.
|
|
// In the previous bestScore algorithm, this would have picked comma as the delimiter, but now it should guess tab
|
|
{
|
|
csv: `c1 c2 c3 c4 c5 c6
|
|
v,k,x,v ym,f,oa,qn,uqijh,n,s,wvygpo uj,kt,j,w,i,fvv,tm,f,ddt,b,mwt,e,t,teq,rd,p,a e,wfuae,t,h,q,im,ix,y h,mrlu,l,dz,ff,zi,af,emh ,gov,bmfelvb,axp,f,u,i,cni,x,z,v,sh,w,jo,,m,h
|
|
k,ohf,pgr,tde,m,s te,ek,,v,,ic,kqc,dv,w,oi,j,w,gojjr,ug,,l,j,zl g,qziq,bcajx,zfow,ka,j,re,ohbc k,nzm,qm,ts,auf th,elb,lx,l,q,e,qf asbr,z,k,y,tltobga
|
|
g,m,bu,el h,l,jwi,o,wge,fy,rure,c,g,lcxu,fxte,uns,cl,s,o,t,h,rsoy,f bq,s,uov,z,ikkhgyg,,sabs,c,hzue mc,b,,j,t,n sp,mn,,m,t,dysi,eq,pigb,rfa,z w,rfli,sg,,o,wjjjf,f,wxdzfk,x,t,p,zy,p,mg,r,l,h
|
|
e,ewbkc,nugd,jj,sf,ih,i,n,jo,b,poem,kw,q,i,x,t,e,uug,k j,xm,sch,ux,h,,fb,f,pq,,mh,,f,v,,oba,w,h,v,eiz,yzd,o,a,c,e,dhp,q a,pbef,epc,k,rdpuw,cw k,j,e,d xf,dz,sviv,w,sqnzew,t,b v,yg,f,cq,ti,g,m,ta,hm,ym,ii,hxy,p,z,r,e,ga,sfs,r,p,l,aar,w,kox,j
|
|
l,d,v,pp,q,j,bxip,w,i,im,qa,o e,o h,w,a,a,qzj,nt,qfn,ut,fvhu,ts hu,q,g,p,q,ofpje,fsqa,frp,p,vih,j,w,k,jx, ln,th,ka,l,b,vgk,rv,hkx rj,v,y,cwm,rao,e,l,wvr,ptc,lm,yg,u,k,i,b,zk,b,gv,fls
|
|
velxtnhlyuysbnlchosqlhkozkdapjaueexjwrndwb nglvnv kqiv pbshwlmcexdzipopxjyrxhvjalwp pydvipwlkkpdvbtepahskwuornbsb qwbacgq
|
|
l,y,u,bf,y,m,eals,n,cop,h,g,vs,jga,opt x,b,zwmn,hh,b,n,pdj,t,d px yn,vtd,u,y,b,ps,yo,qqnem,mxg,m,al,rd,c,k,d,q,f ilxdxa,m,y,,p,p,y,prgmg,q,n,etj,k,ns b,pl,z,jq,hk
|
|
p,gc jn,mzr,bw sb,e,r,dy,ur,wzy,r,c,n,yglr,jbdu,r,pqk,k q,d,,,p,l,euhl,dc,rwh,t,tq,z,h,p,s,t,x,fugr,h wi,zxb,jcig,o,t,k mfh,ym,h,e,p,cnvx,uv,zx,x,pq,blt,v,r,u,tr,g,g,xt
|
|
nri,p,,t,if,,y,ptlqq a,i w,ovli,um,w,f,re,k,sb,w,jy,zf i,g,p,q,mii,nr,jm,cc i,szl,k,eg,l,d ,ah,w,b,vh
|
|
,,sh,wx,mn,xm,u,d,yy,u,t,m,j,s,b ogadq,g,y,y,i,h,ln,jda,g,cz,s,rv,r,s,s,le,r, y,nu,f,nagj o,h,,adfy,o,nf,ns,gvsvnub,k,b,xyz v,h,g,ef,y,gb c,x,cw,x,go,h,t,x,cu,u,qgrqzrcmn,kq,cd,g,rejp,zcq
|
|
skxg,t,vay,d,wug,d,xg,sexc rt g,ag,mjq,fjnyji,iwa,m,ml,b,ua,b,qjxeoc be,s,sh,n,jbzxs,g,n,i,h,y,r,be,mfo,u,p cw,r,,u,zn,eg,r,yac,m,l,edkr,ha,x,g,b,c,tg,c j,ye,u,ejd,maj,ea,bm,u,iy`,
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 13 - a CSV with more than 10 lines and since we only use the first 10 lines, it should still get the delimiter as semicolon
|
|
{
|
|
csv: `col1;col2;col3
|
|
1;1;1
|
|
2;2;2
|
|
3;3;3
|
|
4;4;4
|
|
5;5;5
|
|
6;6;6
|
|
7;7;7
|
|
8;8;8
|
|
9;9;9
|
|
10;10;10
|
|
11 11 11
|
|
12|12|12`,
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 14 - a really long single line (over 10k) that will get truncated, but since it has commas and semicolons (but more semicolons) it will pick semicolon
|
|
{
|
|
csv: strings.Repeat("a;b,c;", 1700),
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 15 - 2 lines that are well over 10k, but since the 2nd line is where this CSV will be truncated (10k sample), it will only use the first line, so semicolon will be picked
|
|
{
|
|
csv: "col1@col2@col3\na@b@" + strings.Repeat("c", 6000) + "\nd,e," + strings.Repeat("f", 4000),
|
|
expectedDelimiter: '@',
|
|
},
|
|
// case 16 - has all delimiters so should return comma
|
|
{
|
|
csv: `col1,col2;col3@col4|col5 col6
|
|
a b|c@d;e,f`,
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 16 - nothing works (bad csv) so returns comma by default
|
|
{
|
|
csv: `col1,col2
|
|
a;b
|
|
c@e
|
|
f g
|
|
h|i
|
|
jkl`,
|
|
expectedDelimiter: ',',
|
|
},
|
|
}
|
|
|
|
for n, c := range cases {
|
|
delimiter := guessDelimiter([]byte(decodeSlashes(t, c.csv)))
|
|
assert.EqualValues(t, c.expectedDelimiter, delimiter, "case %d: delimiter should be equal, expected '%c' got '%c'", n, c.expectedDelimiter, delimiter)
|
|
}
|
|
}
|
|
|
|
func TestGuessFromBeforeAfterQuotes(t *testing.T) {
|
|
cases := []struct {
|
|
csv string
|
|
expectedDelimiter rune
|
|
}{
|
|
// case 0 - tab delimited with new lines in values, commas in values
|
|
{
|
|
csv: `1 "some,""more
|
|
""
|
|
quoted,
|
|
text," a
|
|
2 "some,
|
|
quoted,\t
|
|
text," b
|
|
3 "some,
|
|
quoted,
|
|
text" c
|
|
4 "some,
|
|
quoted,
|
|
text," d`,
|
|
expectedDelimiter: '\t',
|
|
},
|
|
// case 1 - semicolon delmited with quotes and semicolon in value
|
|
{
|
|
csv: `col1;col2
|
|
"this has a literal "" in the text";"and an ; in the text"`,
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 2 - pipe delimited with quotes
|
|
{
|
|
csv: `Col1 | Col2 | Col3
|
|
abc | "Hello
|
|
World"|123
|
|
"de
|
|
|
|
|
f" | 4.56 | 789`,
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 3 - a complicated quoted CSV that is semicolon delmiited
|
|
{
|
|
csv: `he; she
|
|
"he said, ""hey!"""; "she said, ""hey back!"""
|
|
but; "be"`,
|
|
expectedDelimiter: ';',
|
|
},
|
|
// case 4 - no delimiter should be found
|
|
{
|
|
csv: `a,b`,
|
|
expectedDelimiter: 0,
|
|
},
|
|
// case 5 - no limiter should be found
|
|
{
|
|
csv: `col1
|
|
"he said, ""here I am"""`,
|
|
expectedDelimiter: 0,
|
|
},
|
|
// case 6 - delimiter before double quoted string with space
|
|
{
|
|
csv: `col1|col2
|
|
a| "he said, ""here I am"""`,
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 7 - delimiter before double quoted string without space
|
|
{
|
|
csv: `col1|col2
|
|
a|"he said, ""here I am"""`,
|
|
expectedDelimiter: '|',
|
|
},
|
|
// case 8 - delimiter after double quoted string with space
|
|
{
|
|
csv: `col1, col2
|
|
"abc\n
|
|
|
|
", def`,
|
|
expectedDelimiter: ',',
|
|
},
|
|
// case 9 - delimiter after double quoted string without space
|
|
{
|
|
csv: `col1,col2
|
|
"abc\n
|
|
|
|
",def`,
|
|
expectedDelimiter: ',',
|
|
},
|
|
}
|
|
|
|
for n, c := range cases {
|
|
delimiter := guessFromBeforeAfterQuotes([]byte(decodeSlashes(t, c.csv)))
|
|
assert.EqualValues(t, c.expectedDelimiter, delimiter, "case %d: delimiter should be equal, expected '%c' got '%c'", n, c.expectedDelimiter, delimiter)
|
|
}
|
|
}
|
|
|
|
func TestFormatError(t *testing.T) {
|
|
cases := []struct {
|
|
err error
|
|
expectedMessage string
|
|
expectsError bool
|
|
}{
|
|
{
|
|
err: &csv.ParseError{
|
|
Err: csv.ErrFieldCount,
|
|
},
|
|
expectedMessage: "repo.error.csv.invalid_field_count",
|
|
expectsError: false,
|
|
},
|
|
{
|
|
err: &csv.ParseError{
|
|
Err: csv.ErrBareQuote,
|
|
},
|
|
expectedMessage: "repo.error.csv.unexpected",
|
|
expectsError: false,
|
|
},
|
|
{
|
|
err: bytes.ErrTooLarge,
|
|
expectsError: true,
|
|
},
|
|
}
|
|
|
|
for n, c := range cases {
|
|
message, err := FormatError(c.err, &translation.MockLocale{})
|
|
if c.expectsError {
|
|
assert.Error(t, err, "case %d: expected an error to be returned", n)
|
|
} else {
|
|
assert.NoError(t, err, "case %d: no error was expected, got error: %v", n, err)
|
|
assert.EqualValues(t, c.expectedMessage, message, "case %d: messages should be equal, expected '%s' got '%s'", n, c.expectedMessage, message)
|
|
}
|
|
}
|
|
}
|