[ConvNets/TF2] EfficientNet release
This commit is contained in:
parent
2bdf2775e3
commit
4a66a008c4
98
TensorFlow2/Classification/ConvNets/efficientnet/.gitignore
vendored
Normal file
98
TensorFlow2/Classification/ConvNets/efficientnet/.gitignore
vendored
Normal file
|
|
@ -0,0 +1,98 @@
|
|||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
env/
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*,cover
|
||||
.hypothesis/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# IPython Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# mypy
|
||||
.mypy_cache
|
||||
|
||||
# celery beat schedule file
|
||||
celerybeat-schedule
|
||||
|
||||
# dotenv
|
||||
.env
|
||||
|
||||
# virtualenv
|
||||
venv/
|
||||
ENV/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# PyCharm
|
||||
.idea/
|
||||
|
||||
# For mac
|
||||
.DS_Store
|
||||
30
TensorFlow2/Classification/ConvNets/efficientnet/Dockerfile
Normal file
30
TensorFlow2/Classification/ConvNets/efficientnet/Dockerfile
Normal file
|
|
@ -0,0 +1,30 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
ARG FROM_IMAGE_NAME=nvcr.io/nvidia/tensorflow:21.02-tf2-py3
|
||||
FROM ${FROM_IMAGE_NAME}
|
||||
|
||||
RUN echo ${FROM_IMAGE_NAME}
|
||||
|
||||
LABEL Effnet_tf by subhankarg
|
||||
|
||||
RUN rm -rf /workspace && mkdir -p /workspace
|
||||
ADD . /workspace
|
||||
WORKDIR /workspace
|
||||
COPY . .
|
||||
|
||||
RUN python -m pip install --upgrade pip && \
|
||||
pip --no-cache-dir --no-cache install --user -r requirements.txt
|
||||
|
||||
RUN pip install git+https://github.com/NVIDIA/dllogger
|
||||
204
TensorFlow2/Classification/ConvNets/efficientnet/LICENSE
Normal file
204
TensorFlow2/Classification/ConvNets/efficientnet/LICENSE
Normal file
|
|
@ -0,0 +1,204 @@
|
|||
Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
Copyright 2016 The TensorFlow Authors. All rights reserved.
|
||||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright 2016, The Authors.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
693
TensorFlow2/Classification/ConvNets/efficientnet/README.md
Normal file
693
TensorFlow2/Classification/ConvNets/efficientnet/README.md
Normal file
|
|
@ -0,0 +1,693 @@
|
|||
# EfficientNet For TensorFlow 2.4
|
||||
|
||||
This repository provides a script and recipe to train the EfficientNet model to achieve state-of-the-art accuracy.
|
||||
The content of the repository is tested and maintained by NVIDIA.
|
||||
|
||||
## Table Of Contents
|
||||
|
||||
- [Model overview](#model-overview)
|
||||
* [Model architecture](#model-architecture)
|
||||
* [Default configuration](#default-configuration)
|
||||
* [Feature support matrix](#feature-support-matrix)
|
||||
* [Features](#features)
|
||||
* [Mixed precision training](#mixed-precision-training)
|
||||
* [Enabling mixed precision](#enabling-mixed-precision)
|
||||
* [Enabling TF32](#enabling-tf32)
|
||||
|
||||
- [Setup](#setup)
|
||||
* [Requirements](#requirements)
|
||||
- [Quick Start Guide](#quick-start-guide)
|
||||
- [Advanced](#advanced)
|
||||
* [Scripts and sample code](#scripts-and-sample-code)
|
||||
* [Parameters](#parameters)
|
||||
* [Command-line options](#command-line-options)
|
||||
* [Getting the data](#getting-the-data)
|
||||
|
||||
* [Training process](#training-process)
|
||||
*[Multi-node](#multi-node)
|
||||
* [Inference process](#inference-process)
|
||||
- [Performance](#performance)
|
||||
* [Benchmarking](#benchmarking)
|
||||
* [Training performance benchmark](#training-performance-benchmark)
|
||||
* [Inference performance benchmark](#inference-performance-benchmark)
|
||||
* [Results](#results)
|
||||
* [Training accuracy results for EfficientNet-B0](#training-accuracy-results-for-efficientnet-b0)
|
||||
* [Training accuracy: NVIDIA DGX A100 (8x A100 80GB)](#training-accuracy-nvidia-dgx-a100-8x-a100-80gb)
|
||||
* [Training accuracy: NVIDIA DGX-1 (8x V100 16GB)](#training-accuracy-nvidia-dgx-1-8x-v100-16gb)
|
||||
* [Training accuracy results for EfficientNet-B4](#training-accuracy-results-for-efficientnet-b4)
|
||||
* [Training accuracy: NVIDIA DGX A100 (8x A100 80GB)](#training-accuracy-nvidia-dgx-a100-8x-a100-80gb-1)
|
||||
* [Training accuracy: NVIDIA DGX-1 (8x V100 32GB)](#training-accuracy-nvidia-dgx-1-8x-v100-32gb)
|
||||
* [Training performance results for EfficientNet-B0](#training-performance-results-for-efficientnet-b0)
|
||||
* [Training performance: NVIDIA DGX A100 (8x A100 80GB)](#training-performance-nvidia-dgx-a100-8x-a100-80gb)
|
||||
* [Training performance: NVIDIA DGX-1 (8x V100 16GB)](#training-performance-nvidia-dgx-1-8x-v100-16gb)
|
||||
* [Training performance results for EfficientNet-B4](#training-performance-results-for-efficientnet-b4)
|
||||
* [Training performance: NVIDIA DGX A100 (8x A100 80GB)](#training-performance-nvidia-dgx-a100-8x-a100-80gb-1)
|
||||
* [Training performance: NVIDIA DGX-1 (8x V100 32GB)](#training-performance-nvidia-dgx-1-8x-v100-32gb)
|
||||
* [Inference performance results for EfficientNet-B0](#inference-performance-results-for-efficientnet-b0)
|
||||
* [Inference performance: NVIDIA DGX A100 (1x A100 80GB)](#inference-performance-nvidia-dgx-a100-1x-a100-80gb)
|
||||
* [Inference performance: NVIDIA DGX-1 (1x V100 16GB)](#inference-performance-nvidia-dgx-1-1x-v100-16gb)
|
||||
* [Inference performance results for EfficientNet-B4](#inference-performance-results-for-efficientnet-b4)
|
||||
* [Inference performance: NVIDIA DGX A100 (1x A100 80GB)](#inference-performance-nvidia-dgx-a100-1x-a100-80gb-1)
|
||||
* [Inference performance: NVIDIA DGX-1 (1x V100 32GB)](#inference-performance-nvidia-dgx-1-1x-v100-32gb)
|
||||
- [Release notes](#release-notes)
|
||||
* [Changelog](#changelog)
|
||||
* [Known issues](#known-issues)
|
||||
|
||||
|
||||
|
||||
## Model overview
|
||||
|
||||
EfficientNet TensorFlow 2 is a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
|
||||
This model is based on [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946).
|
||||
NVIDIA's implementation of EfficientNet TensorFlow 2 is an optimized version of [TensorFlow Model Garden](https://github.com/tensorflow/models/tree/master/official/vision/image_classification) implementation,
|
||||
leveraging mixed precision arithmetic on Volta, Turing, and the NVIDIA Ampere GPU architectures for faster training times while maintaining target accuracy.
|
||||
|
||||
The major differences between the original implementation of the paper and this version of EfficientNet are as follows:
|
||||
- Automatic mixed precision (AMP) training support
|
||||
- Cosine LR decay for better accuracy
|
||||
- Weight initialization using `fan_out` for better accuracy
|
||||
- Multi-node training support
|
||||
- XLA enabled for better performance
|
||||
- Lightweight logging using [dllogger](https://github.com/NVIDIA/dllogger)
|
||||
|
||||
Other publicly available implementations of EfficientNet include:
|
||||
|
||||
- [Tensorflow Model Garden](https://github.com/tensorflow/models/tree/master/official/vision/image_classification)
|
||||
- [Pytorch version](https://github.com/rwightman/pytorch-image-models)
|
||||
- [Google's implementation for TPU](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet)
|
||||
|
||||
This model is trained with mixed precision Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. It provides a push-button solution to pretraining on a corpus of choice.
|
||||
As a result, researchers can get results 1.5x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly released container to ensure consistent accuracy and performance over time.
|
||||
|
||||
|
||||
### Model architecture
|
||||
|
||||
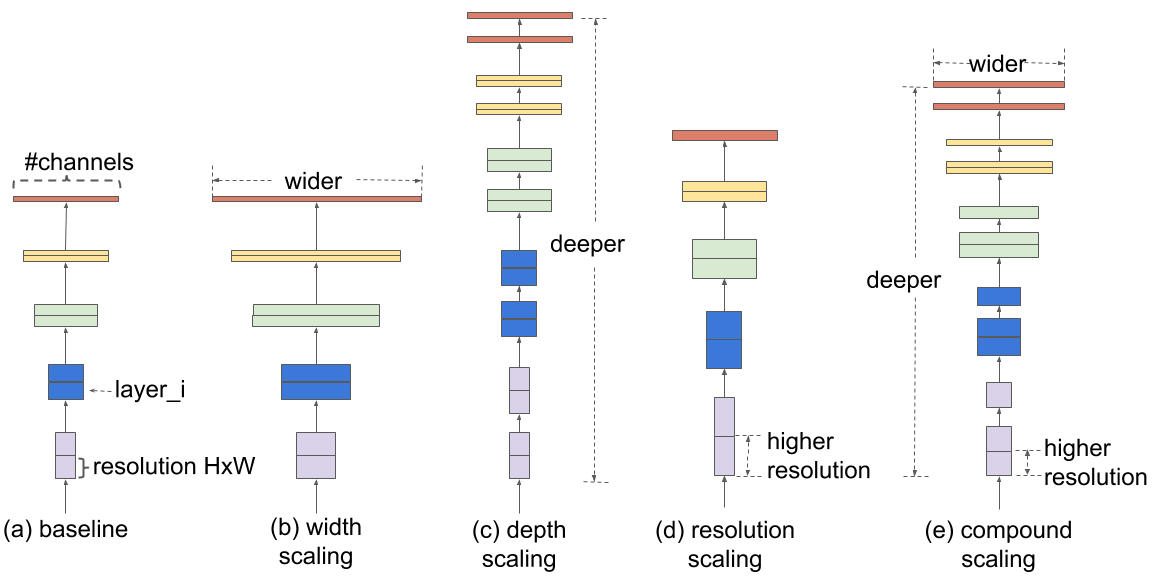
EfficientNets are developed based on AutoML and Compound Scaling. In particular,
|
||||
a mobile-size baseline network called EfficientNet-B0 is developed from AutoML MNAS Mobile
|
||||
framework, the building block is mobile inverted bottleneck MBConv with squeeze-and-excitation optimization.
|
||||
Then, through a compound scaling method, this baseline is scaled up to obtain EfficientNet-B1
|
||||
to B7.
|
||||
|
||||
|
||||
|
||||
### Default configuration
|
||||
|
||||
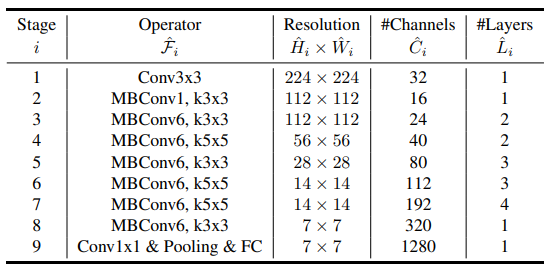
Here is the Baseline EfficientNet-B0 structure.
|
||||
|
||||
|
||||
The following features were implemented in this model:
|
||||
- General:
|
||||
- XLA support
|
||||
- Mixed precision support
|
||||
- Multi-GPU support using Horovod
|
||||
- Multi-node support using Horovod
|
||||
- Cosine LR Decay
|
||||
|
||||
- Inference:
|
||||
- Support for inference on single image is included
|
||||
- Support for inference on batch of images is included
|
||||
|
||||
### Feature support matrix
|
||||
|
||||
The following features are supported by this model:
|
||||
|
||||
| Feature | EfficientNet
|
||||
|-----------------------|-------------------------- |
|
||||
|Horovod Multi-GPU training (NCCL) | Yes |
|
||||
|Multi-node training | Yes |
|
||||
|Automatic mixed precision (AMP) | Yes |
|
||||
|XLA | Yes |
|
||||
|
||||
|
||||
#### Features
|
||||
|
||||
|
||||
|
||||
**Multi-GPU training with Horovod**
|
||||
|
||||
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the [TensorFlow tutorial](https://github.com/horovod/horovod/#usage).
|
||||
|
||||
|
||||
**Multi-node training with Horovod**
|
||||
|
||||
Our model also uses Horovod to implement efficient multi-node training.
|
||||
|
||||
|
||||
|
||||
**Automatic Mixed Precision (AMP)**
|
||||
|
||||
Computation graphs can be modified by TensorFlow on runtime to support mixed precision training. Detailed explanation of mixed precision can be found in the next section.
|
||||
|
||||
|
||||
### Mixed precision training
|
||||
|
||||
Mixed precision is the combined use of different numerical precisions in a computational method. [Mixed precision](https://arxiv.org/abs/1710.03740) training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of [Tensor Cores](https://developer.nvidia.com/tensor-cores) in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using [mixed precision training](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html) previously required two steps:
|
||||
1. Porting the model to use the FP16 data type where appropriate.
|
||||
2. Adding loss scaling to preserve small gradient values.
|
||||
|
||||
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full [mixed precision methodology](https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html#tensorflow) in your existing TensorFlow model code. AMP enables mixed precision training on Volta, Turing, and NVIDIA Ampere GPU architectures automatically. The TensorFlow framework code makes all necessary model changes internally.
|
||||
|
||||
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
|
||||
|
||||
For information about:
|
||||
- How to train using mixed precision, see the [Mixed Precision Training](https://arxiv.org/abs/1710.03740) paper and [Training With Mixed Precision](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html) documentation.
|
||||
- Techniques used for mixed precision training, see the [Mixed-Precision Training of Deep Neural Networks](https://devblogs.nvidia.com/mixed-precision-training-deep-neural-networks/) blog.
|
||||
- How to access and enable AMP for TensorFlow, see [Using TF-AMP](https://docs.nvidia.com/deeplearning/dgx/tensorflow-user-guide/index.html#tfamp) from the TensorFlow User Guide.
|
||||
|
||||
#### Enabling mixed precision
|
||||
|
||||
Mixed precision is enabled in TensorFlow by using the Automatic Mixed Precision (TF-AMP) extension which casts variables to half-precision upon retrieval, while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a [loss scaling](https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html#lossscaling) step must be included when applying gradients. In TensorFlow, loss scaling can be applied statically by using simple multiplication of loss by a constant value or automatically, by TF-AMP. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
|
||||
|
||||
To enable mixed precision, you can simply add the `--use_amp` to the command-line used to run the model. This will enable the following code:
|
||||
|
||||
```
|
||||
if params.use_amp:
|
||||
policy = tf.keras.mixed_precision.experimental.Policy('mixed_float16', loss_scale='dynamic')
|
||||
tf.keras.mixed_precision.experimental.set_policy(policy)
|
||||
```
|
||||
|
||||
|
||||
#### Enabling TF32
|
||||
|
||||
TensorFloat-32 (TF32) is the new math mode in [NVIDIA A100](https://www.nvidia.com/en-us/data-center/a100/) GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
|
||||
|
||||
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
|
||||
|
||||
For more information, refer to the [TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) blog post.
|
||||
|
||||
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
|
||||
|
||||
|
||||
|
||||
## Setup
|
||||
|
||||
The following section lists the requirements that you need to meet in order to start training the EfficientNet model.
|
||||
|
||||
### Requirements
|
||||
|
||||
This repository contains Dockerfile which extends the TensorFlow NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
|
||||
- [NVIDIA Docker](https://github.com/NVIDIA/nvidia-docker)
|
||||
- [TensorFlow 20.08-py3] NGC container or later
|
||||
- Supported GPUs:
|
||||
- [NVIDIA Volta architecture](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/)
|
||||
- [NVIDIA Turing architecture](https://www.nvidia.com/en-us/geforce/turing/)
|
||||
- [NVIDIA Ampere architecture](https://www.nvidia.com/en-us/data-center/nvidia-ampere-gpu-architecture/)
|
||||
|
||||
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
|
||||
- [Getting Started Using NVIDIA GPU Cloud](https://docs.nvidia.com/ngc/ngc-getting-started-guide/index.html)
|
||||
- [Accessing And Pulling From The NGC Container Registry](https://docs.nvidia.com/deeplearning/frameworks/user-guide/index.html#accessing_registry)
|
||||
- [Running TensorFlow](https://docs.nvidia.com/deeplearning/frameworks/tensorflow-release-notes/running.html#running)
|
||||
|
||||
As an alternative to the use of the Tensorflow2 NGC container, to set up the required environment or create your own container, see the versioned [NVIDIA Container Support Matrix](https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html).
|
||||
|
||||
For multi-node, the sample provided in this repository requires [Enroot](https://github.com/NVIDIA/enroot) and [Pyxis](https://github.com/NVIDIA/pyxis) set up on a [SLURM](https://slurm.schedmd.com) cluster.
|
||||
|
||||
## Quick Start Guide
|
||||
|
||||
To train your model using mixed or TF32 precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the EfficientNet model on the ImageNet dataset. For the specifics concerning training and inference, see the [Advanced](#advanced) section.
|
||||
|
||||
1. Clone the repository.
|
||||
|
||||
```
|
||||
git clone https://github.com/NVIDIA/DeepLearningExamples.git
|
||||
|
||||
cd DeepLearningExamples/TensorFlow2/Classification/ConvNets/efficientnet
|
||||
```
|
||||
|
||||
2. Download and prepare the dataset.
|
||||
`Runner.py` supports ImageNet with [TensorFlow Datasets (TFDS)](https://www.tensorflow.org/datasets/overview). Refer to the [TFDS ImageNet readme](https://github.com/tensorflow/datasets/blob/master/docs/catalog/imagenet2012.md) for manual download instructions.
|
||||
|
||||
3. Build EfficientNet on top of the NGC container.
|
||||
`bash ./scripts/docker/build.sh`
|
||||
|
||||
4. Start an interactive session in the NGC container to run training/inference.
|
||||
`bash ./scripts/docker/launch.sh`
|
||||
|
||||
5. Start training.
|
||||
|
||||
To run training for a standard configuration (DGX A100/DGX-1 V100, AMP/TF32/FP32, 500 Epochs, efficientnet-b0/efficientnet-b4),
|
||||
run one of the scripts in the `./scripts/{B0, B4}/training` directory called `./scripts/{B0, B4}/training/{AMP, TF32, FP32}/convergence_8x{A100-80G, V100-16G, V100-32G}.sh`.
|
||||
Ensure ImageNet is mounted in the `/data` directory.
|
||||
For example:
|
||||
`bash ./scripts/B0/AMP/convergence_8xA100-80G.sh`
|
||||
|
||||
6. Start validation/evaluation.
|
||||
|
||||
To run validation/evaluation for a standard configuration (DGX A100/DGX-1 V100, AMP/TF32/FP32, efficientnet-b0/efficientnet-b4),
|
||||
run one of the scripts in the `./scripts/{B0, B4}/evaluation` directory called `./scripts/{B0, B4}/evaluation/evaluation_{AMP, FP32, TF32}_8x{A100-80G, V100-16G, V100-32G}.sh`.
|
||||
Ensure ImageNet is mounted in the `/data` directory.
|
||||
(Optional) Place the checkpoint in the `--model_dir` location to evaluate on a checkpoint.
|
||||
For example:
|
||||
`bash ./scripts/B0/evaluation/evaluation_AMP_8xA100-80G.sh`
|
||||
|
||||
7. Start inference/predictions.
|
||||
|
||||
To run inference for a standard configuration (DGX A100/DGX-1 V100, AMP/TF32/FP32, efficientnet-b0/efficientnet-b4, batch size 8),
|
||||
run one of the scripts in the `./scripts/{B0, B4}/inference` directory called `./scripts/{B0, B4}/inference/inference_{AMP, FP32, TF32}.sh`.
|
||||
Ensure your JPEG images to be ran inference on are mounted in the `/infer_data` directory with this folder structure :
|
||||
```
|
||||
infer_data
|
||||
| ├── images
|
||||
| | ├── image1.JPEG
|
||||
| | ├── image2.JPEG
|
||||
```
|
||||
(Optional) Place the checkpoint in the `--model_dir` location to evaluate on a checkpoint.
|
||||
For example:
|
||||
`bash ./scripts/B0/inference/inference_{AMP, FP32}.sh`
|
||||
|
||||
Now that you have your model trained and evaluated, you can choose to compare your training results with our [Training accuracy results](#training-accuracy-results). You can also choose to benchmark yours performance to [Training performance benchmark](#training-performance-results), or [Inference performance benchmark](#inference-performance-results). Following the steps in these sections will ensure that you achieve the same accuracy and performance results as stated in the [Results](#results) section.
|
||||
|
||||
## Advanced
|
||||
|
||||
The following sections provide greater details of the dataset, running training and inference, and the training results.
|
||||
|
||||
### Scripts and sample code
|
||||
|
||||
The following lists the content for each folder:
|
||||
- `scripts/` - shell scripts to build and launch EfficientNet container on top of NGC container,
|
||||
and scripts to launch training, evaluation and inference
|
||||
- `model/` - building blocks and EfficientNet model definitions
|
||||
- `runtime/` - detailed procedure for each running mode
|
||||
- `utils/` - support util functions for `runner.py`
|
||||
|
||||
### Parameters
|
||||
|
||||
Important parameters for training are listed below with default values.
|
||||
|
||||
- `mode` (`train_and_eval`,`train`,`eval`,`prediction`) - the default is `train_and_eval`.
|
||||
- `arch` - the default is `efficientnet-b0`
|
||||
- `model_dir` - The folder where model checkpoints are saved (the default is `/workspace/output`)
|
||||
- `data_dir` - The folder where data resides (the default is `/data/`)
|
||||
- `augmenter_name` - Type of Augmentation (the default is `autoaugment`)
|
||||
- `max_epochs` - The number of training epochs (the default is `300`)
|
||||
- `warmup_epochs` - The number of epochs of warmup (the default is `5`)
|
||||
- `train_batch_size` - The training batch size per GPU (the default is `32`)
|
||||
- `eval_batch_size` - The evaluation batch size per GPU (the default is `32`)
|
||||
- `lr_init` - The learning rate for a batch size of 128, effective learning rate will be automatically scaled according to the global training batch size (the default is `0.008`)
|
||||
|
||||
The main script `main.py` specific parameters are:
|
||||
```
|
||||
--model_dir MODEL_DIR
|
||||
The directory where the model and training/evaluation
|
||||
summariesare stored.
|
||||
--save_checkpoint_freq SAVE_CHECKPOINT_FREQ
|
||||
Number of epochs to save checkpoint.
|
||||
--data_dir DATA_DIR The location of the input data. Files should be named
|
||||
`train-*` and `validation-*`.
|
||||
--mode MODE Mode to run: `train`, `eval`, `train_and_eval`, `predict` or
|
||||
`export`.
|
||||
--arch ARCH The type of the model, e.g. EfficientNet, etc.
|
||||
--dataset DATASET The name of the dataset, e.g. ImageNet, etc.
|
||||
--log_steps LOG_STEPS
|
||||
The interval of steps between logging of batch level
|
||||
stats.
|
||||
--use_xla Set to True to enable XLA
|
||||
--use_amp Set to True to enable AMP
|
||||
--num_classes NUM_CLASSES
|
||||
Number of classes to train on.
|
||||
--batch_norm BATCH_NORM
|
||||
Type of Batch norm used.
|
||||
--activation ACTIVATION
|
||||
Type of activation to be used.
|
||||
--optimizer OPTIMIZER
|
||||
Optimizer to be used.
|
||||
--moving_average_decay MOVING_AVERAGE_DECAY
|
||||
The value of moving average.
|
||||
--label_smoothing LABEL_SMOOTHING
|
||||
The value of label smoothing.
|
||||
--max_epochs MAX_EPOCHS
|
||||
Number of epochs to train.
|
||||
--num_epochs_between_eval NUM_EPOCHS_BETWEEN_EVAL
|
||||
Eval after how many steps of training.
|
||||
--steps_per_epoch STEPS_PER_EPOCH
|
||||
Number of steps of training.
|
||||
--warmup_epochs WARMUP_EPOCHS
|
||||
Number of steps considered as warmup and not taken
|
||||
into account for performance measurements.
|
||||
--lr_init LR_INIT Initial value for the learning rate.
|
||||
--lr_decay LR_DECAY Type of LR Decay.
|
||||
--lr_decay_rate LR_DECAY_RATE
|
||||
LR Decay rate.
|
||||
--lr_decay_epochs LR_DECAY_EPOCHS
|
||||
LR Decay epoch.
|
||||
--weight_decay WEIGHT_DECAY
|
||||
Weight Decay scale factor.
|
||||
--weight_init {fan_in,fan_out}
|
||||
Model weight initialization method.
|
||||
--train_batch_size TRAIN_BATCH_SIZE
|
||||
Training batch size per GPU.
|
||||
--augmenter_name AUGMENTER_NAME
|
||||
Type of Augmentation during preprocessing only during
|
||||
training.
|
||||
--eval_batch_size EVAL_BATCH_SIZE
|
||||
Evaluation batch size per GPU.
|
||||
--resume_checkpoint Resume from a checkpoint in the model_dir.
|
||||
--use_dali Use dali for data loading and preprocessing of train
|
||||
dataset.
|
||||
--use_dali_eval Use dali for data loading and preprocessing of eval
|
||||
dataset.
|
||||
--dtype DTYPE Only permitted
|
||||
`float32`,`bfloat16`,`float16`,`fp32`,`bf16`
|
||||
```
|
||||
|
||||
### Command-line options
|
||||
|
||||
To see the full list of available options and their descriptions, use the `-h` or `--help` command-line option, for example:
|
||||
`python main.py --help`
|
||||
|
||||
|
||||
### Getting the data
|
||||
|
||||
Refer to the [TFDS ImageNet readme](https://github.com/tensorflow/datasets/blob/master/docs/catalog/imagenet2012.md) for manual download instructions.
|
||||
To train on ImageNet dataset, pass `$path_to_ImageNet_tfrecords` to `$data_dir` in the command-line.
|
||||
|
||||
Name the TFRecords in the following scheme:
|
||||
|
||||
- Training images - `/data/train-*`
|
||||
- Validation images - `/data/validation-*`
|
||||
|
||||
### Training process
|
||||
|
||||
The training process can start from scratch, or resume from a checkpoint.
|
||||
|
||||
By default, bash script `scripts/{B0, B4}/training/{AMP, FP32, TF32}/convergence_8x{A100-80G, V100-16G, V100-32G}.sh` will start the training process from scratch with the following settings.
|
||||
- Use 8 GPUs by Horovod
|
||||
- Has XLA enabled
|
||||
- Saves checkpoints after every 5 epochs to `/workspace/output/` folder
|
||||
- AMP or FP32 or TF32 based on the folder `scripts/{B0, B4}/training/{AMP, FP32, TF32}`
|
||||
|
||||
To resume from a checkpoint, include `--resume_checkpoint` in the command-line and place the checkpoint into `--model_dir`.
|
||||
|
||||
#### Multi-node
|
||||
|
||||
Multi-node runs can be launched on a Pyxis/enroot Slurm cluster (see [Requirements](#requirements)) with the `run_{B0, B4}_multinode.sub` script with the following command for a 4-node NVIDIA DGX A100 example:
|
||||
|
||||
```
|
||||
PARTITION=<partition_name> sbatch N 4 --ntasks-per-node=8 run_B0_multinode.sub
|
||||
PARTITION=<partition_name> sbatch N 4 --ntasks-per-node=8 run_B4_multinode.sub
|
||||
```
|
||||
|
||||
Checkpoint after `--save_checkpoint_freq` epochs will be saved in `checkpointdir`. The checkpoint will be automatically picked up to resume training in case it needs to be resumed. Cluster partition name has to be provided `<partition_name>`.
|
||||
|
||||
Note that the `run_{B0, B4}_multinode.sub` script is a starting point that has to be adapted depending on the environment. In particular, variables such as `--container-image` handle the container image to train using and `--datadir` handle the location of the ImageNet data.
|
||||
|
||||
Refer to the files contents to see the full list of variables to adjust for your system.
|
||||
|
||||
### Inference process
|
||||
|
||||
Validation is done every epoch and can be also run separately on a checkpointed model.
|
||||
|
||||
`bash ./scripts/{B0, B4}/evaluation/evaluation_{AMP, FP32, TF32}_8x{A100-80G, V100-16G, V100-32G}.sh`
|
||||
|
||||
Metrics gathered through this process are as follows:
|
||||
|
||||
```
|
||||
- eval_loss
|
||||
- eval_accuracy_top_1
|
||||
- eval_accuracy_top_5
|
||||
- avg_exp_per_second_eval
|
||||
- avg_exp_per_second_eval_per_GPU
|
||||
- avg_time_per_exp_eval : Average Latency
|
||||
- latency_90pct : 90% Latency
|
||||
- latency_95pct : 95% Latency
|
||||
- latency_99pct : 99% Latency
|
||||
```
|
||||
|
||||
To run inference on a JPEG image, you have to first store the checkpoint in the `--model_dir` and store the JPEG images in the following directory structure:
|
||||
|
||||
```
|
||||
infer_data
|
||||
| ├── images
|
||||
| | ├── image1.JPEG
|
||||
| | ├── image2.JPEG
|
||||
```
|
||||
|
||||
Run:
|
||||
`bash ./scripts/{B0, B4}/inference/inference_{AMP, FP32, TF32}.sh`
|
||||
|
||||
## Performance
|
||||
|
||||
### Benchmarking
|
||||
|
||||
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
|
||||
|
||||
#### Training performance benchmark
|
||||
|
||||
Training benchmark for EfficientNet-B0 was run on NVIDIA DGX A100 80GB and NVIDIA DGX-1 V100 16GB.
|
||||
|
||||
To benchmark training performance with other parameters, run:
|
||||
|
||||
`bash ./scripts/B0/training/{AMP, FP32, TF32}/train_benchmark_8x{A100-80G, V100-16G}.sh`
|
||||
|
||||
Training benchmark for EfficientNet-B4 was run on NVIDIA DGX A100- 80GB and NVIDIA DGX-1 V100 32GB.
|
||||
|
||||
`bash ./scripts/B4/training/{AMP, FP32, TF32}/train_benchmark_8x{A100-80G, V100-16G}.sh`
|
||||
|
||||
#### Inference performance benchmark
|
||||
|
||||
Inference benchmark for EfficientNet-B0 was run on NVIDIA DGX A100- 80GB and NVIDIA DGX-1 V100 16GB.
|
||||
|
||||
Inference benchmark for EfficientNet-B4 was run on NVIDIA DGX A100- 80GB and NVIDIA DGX-1 V100 32GB.
|
||||
|
||||
### Results
|
||||
|
||||
The following sections provide details on how we achieved our performance and accuracy in training and inference.
|
||||
|
||||
#### Training accuracy results for EfficientNet-B0
|
||||
|
||||
|
||||
##### Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
|
||||
|
||||
Our results were obtained by running the training scripts in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs.
|
||||
|
||||
| GPUs | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|
||||
|-------------------|-----------------------|-------------|-------|-------------------|---------------------------------------|
|
||||
| 8 | 77.38 | 77.43 | 19 | 10.5 | 1.8 |
|
||||
| 16 | 77.46 | 77.62 | 10 | 5.5 | 1.81 |
|
||||
|
||||
|
||||
##### Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
|
||||
|
||||
Our results were obtained by running the training scripts in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
|
||||
|
||||
| GPUs | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|
||||
|-------------------|-----------------------|-------------|-------|-------------------|---------------------------------------|
|
||||
| 8 | 77.54 | 77.51 | 11.48 | 11.44 | 1.003 |
|
||||
| 32 | 77.38 | 77.62 | 48 | 44 | 1.09 |
|
||||
|
||||
|
||||
#### Training accuracy results for EfficientNet-B4
|
||||
|
||||
|
||||
##### Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
|
||||
|
||||
Our results were obtained by running the training scripts in the tensorflow:21.02-tf2-py3 NGC container on multi-node NVIDIA DGX A100 (8x A100 80GB) GPUs.
|
||||
|
||||
| GPUs | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|
||||
|-------------------|-----------------------|-------------|-------|-------------------|---------------------------------------|
|
||||
| 32 | 82.69 | 82.69 | 38 | 17.5 | 2.17 |
|
||||
| 64 | 82.75 | 82.78 | 18 | 8.5 | 2.11 |
|
||||
|
||||
|
||||
##### Training accuracy: NVIDIA DGX-1 (8x V100 32GB)
|
||||
|
||||
Our results were obtained by running the training scripts in the tensorflow:21.02-tf2-py3 NGC container on multi-node NVIDIA DGX-1 (8x V100 32GB) GPUs.
|
||||
|
||||
| GPUs | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|
||||
|-------------------|-----------------------|-------------|-------|-------------------|---------------------------------------|
|
||||
| 32 | 82.78 | 82.78 | 95 | 39.5 | 2.40 |
|
||||
| 64 | 82.74 | 82.74 | 53 | 19 | 2.78 |
|
||||
|
||||
#### Training performance results for EfficientNet-B0
|
||||
|
||||
|
||||
##### Training performance: NVIDIA DGX A100 (8x A100 80GB)
|
||||
|
||||
Our results were obtained by running the training benchmark script in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs. Performance numbers (in items/images per second) were averaged over 5 entire training epoch.
|
||||
|
||||
| GPUs | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|
||||
|-----|-----|-----|-----|------|-------|
|
||||
| 1 | 1206 | 2549 | 2.11 | 1 | 1 |
|
||||
| 8 | 9365 | 16336 | 1.74 | 7.76 | 6.41 |
|
||||
| 16 | 18361 | 33000 | 1.79 | 15.223 | 12.95 |
|
||||
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
|
||||
##### Training performance: NVIDIA DGX-1 (8x V100 16GB)
|
||||
|
||||
Our results were obtained by running the training benchmark script in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs. Performance numbers (in items/images per second) were averaged over an entire training epoch.
|
||||
|
||||
|
||||
| GPUs | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|
||||
|-----|-----|-----|-----|------|-------|
|
||||
| 1 | 629 | 712 | 1.13 | 1 | 1 |
|
||||
| 8 | 4012 | 4065 | 1.01 | 6.38 | 5.71 |
|
||||
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
#### Training performance results for EfficientNet-B4
|
||||
|
||||
|
||||
##### Training performance: NVIDIA DGX A100 (8x A100 80GB)
|
||||
|
||||
Our results were obtained by running the training benchmark script in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs. Performance numbers (in items/images per second) were averaged over 5 entire training epoch.
|
||||
|
||||
| GPUs | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|
||||
|-----|-----|-----|-----|------|-------|
|
||||
| 1 | 167 | 394 | 2.34 | 1 | 1 |
|
||||
| 8 | 1280 | 2984 | 2.33 | 7.66 | 7.57 |
|
||||
| 32 | 5023 | 11034 | 2.19 | 30.07 | 28.01 |
|
||||
| 64 | 9838 | 21844 | 2.22 | 58.91 | 55.44 |
|
||||
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
|
||||
##### Training performance: NVIDIA DGX-1 (8x V100 32GB)
|
||||
|
||||
Our results were obtained by running the training benchmark script in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs. Performance numbers (in items/images per second) were averaged over an entire training epoch.
|
||||
|
||||
|
||||
| GPUs | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|
||||
|-----|-----|-----|-----|------|-------|
|
||||
| 1 | 89 | 193 | 2.16 | 1 | 1 |
|
||||
| 8 | 643 | 1298 | 2.00 | 7.28 | 6.73 |
|
||||
| 32 | 2095 | 4892 | 2.33 | 23.54 | 25.35 |
|
||||
| 64 | 4109 | 9666 | 2.35 | 46.17 | 50.08 |
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
|
||||
|
||||
#### Inference performance results for EfficientNet-B0
|
||||
|
||||
##### Inference performance: NVIDIA DGX A100 (1x A100 80GB)
|
||||
|
||||
Our results were obtained by running the inferencing benchmarking script in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX A100 (1x A100 80GB) GPU.
|
||||
|
||||
FP16 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) |Latency 95% (ms) |Latency 99% (ms) |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 224x224 | 111 | 8.97 | 8.88 | 8.92 | 8.96 |
|
||||
| 2 | 224x224 | 233 | 4.28 | 4.22 | 4.25 | 4.27 |
|
||||
| 4 | 224x224 | 432 | 2.31 | 2.28 | 2.29 | 2.30 |
|
||||
| 8 | 224x224 | 771 | 1.29 | 1.27 | 1.28 | 1.28 |
|
||||
| 1024 | 224x224 | 10269 | 0.10 | 0.10 | 0.10 | 0.10 |
|
||||
|
||||
TF32 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) | Latency 95% (ms) | Latency 99% (ms) |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 224x224 | 101 | 9.87 | 9.78 | 9.82 | 9.86 |
|
||||
| 2 | 224x224 | 204 | 4.89 | 4.83 | 4.85 | 4.88 |
|
||||
| 4 | 224x224 | 381 | 2.62 | 2.59 | 2.60 | 2.61 |
|
||||
| 8 | 224x224 | 584 | 1.71 | 1.69 | 1.70 | 1.71 |
|
||||
| 512 | 224x224 | 5480 | 0.18 | 0.18 | 0.18 | 0.18 |
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
|
||||
##### Inference performance: NVIDIA DGX-1 (1x V100 16GB)
|
||||
|
||||
Our results were obtained by running the `inference-script-name.sh` inferencing benchmarking script in the TensorFlow NGC container on NVIDIA DGX-1 (1x V100 16GB) GPU.
|
||||
|
||||
FP16 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg | Latency 90% |Latency 95% |Latency 99% |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 224x224 | 98.8 | 10.12 | 10.03 | 10.06 | 10.10 |
|
||||
| 2 | 224x224 | 199.3 | 5.01 | 4.95 | 4.97 | 5.00 |
|
||||
| 4 | 224x224 | 382.5 | 2.61 | 2.57 | 2.59 | 2.60 |
|
||||
| 8 | 224x224 | 681.2 | 1.46 | 1.44 | 1.45 | 1.46 |
|
||||
| 256 | 224x224 | 5271 | 0.19 | 0.18 | 0.18 | 0.19 |
|
||||
|
||||
FP32 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 224x224 | 68.39 | 14.62 | 14.45 | 14.51 | 14.56 |
|
||||
| 2 | 224x224 | 125.62 | 7.96 | 7.89 | 7.91 | 7.94 |
|
||||
| 4 | 224x224 | 216.41 | 4.62 | 4.56 | 4.60 | 4.61 |
|
||||
| 8 | 224x224 | 401.60 | 2.49 | 2.45 | 2.47 | 2.48 |
|
||||
| 128 | 224x224 | 2713 | 0.37 | 0.36 | 0.36 | 0.37 |
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
#### Inference performance results for EfficientNet-B4
|
||||
|
||||
##### Inference performance: NVIDIA DGX A100 (1x A100 80GB)
|
||||
|
||||
Our results were obtained by running the inferencing benchmarking script in the tensorflow:21.02-tf2-py3 NGC container on NVIDIA DGX A100 (1x A100 80GB) GPU.
|
||||
|
||||
FP16 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) |Latency 95% (ms) |Latency 99% (ms) |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 380x380 | 57.54 | 17.37 | 17.24 | 17.30 | 17.35 |
|
||||
| 2 | 380x380 | 112.06 | 8.92 | 8.85 | 8.88 | 8.91 |
|
||||
| 4 | 380x380 | 219.71 | 4.55 | 4.52 | 4.53 | 4.54 |
|
||||
| 8 | 380x380 | 383.39 | 2.60 | 2.58 | 2.59 | 2.60 |
|
||||
| 128 | 380x380 | 1470 | 0.68 | 0.67 | 0.67 | 0.68 |
|
||||
|
||||
TF32 Inference Latency
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) | Latency 95% (ms) | Latency 99% (ms) |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 380x380 | 52.68 | 18.98 | 18.86 | 18.91 | 18.96 |
|
||||
| 2 | 380x380 | 95.32 | 10.49 | 10.42 | 10.45 | 10.48 |
|
||||
| 4 | 380x380 | 182.14 | 5.49 | 5.46 | 5.47 | 5.48 |
|
||||
| 8 | 380x380 | 325.72 | 3.07 | 3.05 | 3.05 | 3.06 |
|
||||
| 64 | 380x380 | 694 | 1.43 | 1.42 | 1.43 | 1.43 |
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
|
||||
|
||||
##### Inference performance: NVIDIA DGX-1 (1x V100 32GB)
|
||||
|
||||
Our results were obtained by running the `inference-script-name.sh` inferencing benchmarking script in the TensorFlow NGC container on NVIDIA DGX-1 (1x V100 16GB) GPU.
|
||||
|
||||
FP16 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 380x380 | 54.27 | 18.35 | 18.20 | 18.25 | 18.32 |
|
||||
| 2 | 380x380 | 104.27 | 9.59 | 9.51 | 9.54 | 9.58 |
|
||||
| 4 | 380x380 | 182.61 | 5.47 | 5.41 | 5.43 | 5.46 |
|
||||
| 8 | 380x380 | 234.06 | 4.27 | 4.24 | 4.25 | 4.26 |
|
||||
| 64 | 380x380 | 782.47 | 1.28 | 1.25 | 1.26 | 1.27 |
|
||||
|
||||
|
||||
FP32 Inference Latency
|
||||
|
||||
| Batch size | Resolution | Throughput Avg | Latency Avg | Latency 90% |Latency 95% |Latency 99% |
|
||||
|------------|-----------------|-----|-----|-----|-----|-----|
|
||||
| 1 | 380x380 | 30.48 | 32.80 | 32.86 | 31.83 | 32.60 |
|
||||
| 2 | 380x380 | 58.59 | 17.06 | 15.96 | 16.51 | 16.95 |
|
||||
| 4 | 380x380 | 111.35 | 8.98 | 8.75 | 8.78 | 8.92 |
|
||||
| 8 | 380x380 | 199.00 | 5.03 | 4.84 | 4.88 | 5.00 |
|
||||
| 32 | 380x380 | 307.04 | 3.25 | 3.25 | 3.25 | 3.25 |
|
||||
|
||||
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
||||
|
||||
## Release notes
|
||||
|
||||
### Changelog
|
||||
|
||||
March 2021
|
||||
- Initial release
|
||||
|
||||
### Known issues
|
||||
|
||||
- EfficientNet-B0 does not improve training speed by using AMP as compared to FP32, because of the CPU bound Auto-augmentation.
|
||||
|
||||
|
||||
73
TensorFlow2/Classification/ConvNets/efficientnet/main.py
Normal file
73
TensorFlow2/Classification/ConvNets/efficientnet/main.py
Normal file
|
|
@ -0,0 +1,73 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
|
||||
import warnings
|
||||
warnings.simplefilter("ignore")
|
||||
import tensorflow as tf
|
||||
import horovod.tensorflow as hvd
|
||||
from dllogger import StdOutBackend, JSONStreamBackend, Verbosity
|
||||
import dllogger as DLLogger
|
||||
from utils import hvd_utils
|
||||
|
||||
from utils.setup import set_flags
|
||||
from runtime import Runner
|
||||
from utils.cmdline_helper import parse_cmdline
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
hvd.init()
|
||||
FLAGS = parse_cmdline()
|
||||
set_flags(FLAGS)
|
||||
|
||||
backends = []
|
||||
if not hvd_utils.is_using_hvd() or hvd.rank() == 0:
|
||||
# Prepare Model Dir
|
||||
log_path = os.path.join(FLAGS.model_dir, FLAGS.log_filename)
|
||||
os.makedirs(FLAGS.model_dir, exist_ok=True)
|
||||
# Setup dlLogger
|
||||
backends+=[
|
||||
JSONStreamBackend(verbosity=Verbosity.VERBOSE, filename=log_path),
|
||||
StdOutBackend(verbosity=Verbosity.DEFAULT)
|
||||
]
|
||||
DLLogger.init(backends=backends)
|
||||
DLLogger.log(data=vars(FLAGS), step='PARAMETER')
|
||||
|
||||
runner = Runner(FLAGS, DLLogger)
|
||||
|
||||
if FLAGS.mode in ["train", "train_and_eval", "training_benchmark"]:
|
||||
runner.train()
|
||||
|
||||
if FLAGS.mode in ['eval', 'evaluate', 'inference_benchmark']:
|
||||
if FLAGS.mode == 'inference_benchmark' and hvd_utils.is_using_hvd():
|
||||
raise NotImplementedError("Only single GPU inference is implemented.")
|
||||
elif not hvd_utils.is_using_hvd() or hvd.rank() == 0:
|
||||
runner.evaluate()
|
||||
|
||||
if FLAGS.mode == 'predict':
|
||||
if FLAGS.to_predict is None:
|
||||
raise ValueError("No data to predict on.")
|
||||
|
||||
if not os.path.isdir(FLAGS.to_predict):
|
||||
raise ValueError("Provide directory with images to infer!")
|
||||
|
||||
if hvd_utils.is_using_hvd():
|
||||
raise NotImplementedError("Only single GPU inference is implemented.")
|
||||
|
||||
elif not hvd_utils.is_using_hvd() or hvd.rank() == 0:
|
||||
runner.predict(FLAGS.to_predict, FLAGS.inference_checkpoint)
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from model.blocks.conv2d_block import conv2d_block
|
||||
from model.blocks.mb_conv_block import mb_conv_block
|
||||
|
||||
__all__ = ['conv2d_block', 'mb_conv_block']
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import tensorflow as tf
|
||||
from typing import Any, Dict, Optional, Text, Tuple
|
||||
|
||||
from model.layers import get_batch_norm
|
||||
|
||||
__all__ = ['conv2d_block']
|
||||
|
||||
CONV_KERNEL_INITIALIZER = {
|
||||
'class_name': 'VarianceScaling',
|
||||
'config': {
|
||||
'scale': 2.0,
|
||||
'mode': 'fan_in',
|
||||
# Note: this is a truncated normal distribution
|
||||
'distribution': 'normal'
|
||||
}
|
||||
}
|
||||
|
||||
def conv2d_block(inputs: tf.Tensor,
|
||||
conv_filters: Optional[int],
|
||||
config: dict,
|
||||
kernel_size: Any = (1, 1),
|
||||
strides: Any = (1, 1),
|
||||
use_batch_norm: bool = True,
|
||||
use_bias: bool = False,
|
||||
activation: Any = None,
|
||||
depthwise: bool = False,
|
||||
name: Text = None):
|
||||
"""A conv2d followed by batch norm and an activation."""
|
||||
batch_norm = get_batch_norm(config['batch_norm'])
|
||||
bn_momentum = config['bn_momentum']
|
||||
bn_epsilon = config['bn_epsilon']
|
||||
data_format = tf.keras.backend.image_data_format()
|
||||
weight_decay = config['weight_decay']
|
||||
|
||||
name = name or ''
|
||||
|
||||
# Collect args based on what kind of conv2d block is desired
|
||||
init_kwargs = {
|
||||
'kernel_size': kernel_size,
|
||||
'strides': strides,
|
||||
'use_bias': use_bias,
|
||||
'padding': 'same',
|
||||
'name': name + '_conv2d',
|
||||
'kernel_regularizer': tf.keras.regularizers.l2(weight_decay),
|
||||
'bias_regularizer': tf.keras.regularizers.l2(weight_decay),
|
||||
}
|
||||
CONV_KERNEL_INITIALIZER['config']['mode'] = config['weight_init']
|
||||
|
||||
if depthwise:
|
||||
conv2d = tf.keras.layers.DepthwiseConv2D
|
||||
init_kwargs.update({'depthwise_initializer': CONV_KERNEL_INITIALIZER})
|
||||
else:
|
||||
conv2d = tf.keras.layers.Conv2D
|
||||
init_kwargs.update({'filters': conv_filters,
|
||||
'kernel_initializer': CONV_KERNEL_INITIALIZER})
|
||||
|
||||
x = conv2d(**init_kwargs)(inputs)
|
||||
|
||||
if use_batch_norm:
|
||||
bn_axis = 1 if data_format == 'channels_first' else -1
|
||||
x = batch_norm(axis=bn_axis,
|
||||
momentum=bn_momentum,
|
||||
epsilon=bn_epsilon,
|
||||
name=name + '_bn')(x)
|
||||
|
||||
if activation is not None:
|
||||
x = tf.keras.layers.Activation(activation,
|
||||
name=name + '_activation')(x)
|
||||
return x
|
||||
|
|
@ -0,0 +1,138 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import tensorflow as tf
|
||||
from typing import Any, Dict, Optional, Text, Tuple
|
||||
|
||||
from model.layers import get_activation
|
||||
from model.blocks import conv2d_block
|
||||
|
||||
__all__ = ['mb_conv_block']
|
||||
|
||||
def mb_conv_block(inputs: tf.Tensor,
|
||||
block: dict,
|
||||
config: dict,
|
||||
prefix: Text = None):
|
||||
"""Mobile Inverted Residual Bottleneck.
|
||||
|
||||
Args:
|
||||
inputs: the Keras input to the block
|
||||
block: BlockConfig, arguments to create a Block
|
||||
config: ModelConfig, a set of model parameters
|
||||
prefix: prefix for naming all layers
|
||||
|
||||
Returns:
|
||||
the output of the block
|
||||
"""
|
||||
use_se = config['use_se']
|
||||
activation = get_activation(config['activation'])
|
||||
drop_connect_rate = config['drop_connect_rate']
|
||||
data_format = tf.keras.backend.image_data_format()
|
||||
use_depthwise = block['conv_type'] != 'no_depthwise'
|
||||
prefix = prefix or ''
|
||||
|
||||
filters = block['input_filters'] * block['expand_ratio']
|
||||
|
||||
x = inputs
|
||||
|
||||
if block['fused_conv']:
|
||||
# If we use fused mbconv, skip expansion and use regular conv.
|
||||
x = conv2d_block(x,
|
||||
filters,
|
||||
config,
|
||||
kernel_size=block['kernel_size'],
|
||||
strides=block['strides'],
|
||||
activation=activation,
|
||||
name=prefix + 'fused')
|
||||
else:
|
||||
if block['expand_ratio'] != 1:
|
||||
# Expansion phase
|
||||
kernel_size = (1, 1) if use_depthwise else (3, 3)
|
||||
x = conv2d_block(x,
|
||||
filters,
|
||||
config,
|
||||
kernel_size=kernel_size,
|
||||
activation=activation,
|
||||
name=prefix + 'expand')
|
||||
|
||||
# Depthwise Convolution
|
||||
if use_depthwise:
|
||||
x = conv2d_block(x,
|
||||
conv_filters=None,
|
||||
config=config,
|
||||
kernel_size=block['kernel_size'],
|
||||
strides=block['strides'],
|
||||
activation=activation,
|
||||
depthwise=True,
|
||||
name=prefix + 'depthwise')
|
||||
|
||||
# Squeeze and Excitation phase
|
||||
if use_se:
|
||||
assert block['se_ratio'] is not None
|
||||
assert 0 < block['se_ratio'] <= 1
|
||||
num_reduced_filters = max(1, int(
|
||||
block['input_filters'] * block['se_ratio']
|
||||
))
|
||||
|
||||
if data_format == 'channels_first':
|
||||
se_shape = (filters, 1, 1)
|
||||
else:
|
||||
se_shape = (1, 1, filters)
|
||||
|
||||
se = tf.keras.layers.GlobalAveragePooling2D(name=prefix + 'se_squeeze')(x)
|
||||
se = tf.keras.layers.Reshape(se_shape, name=prefix + 'se_reshape')(se)
|
||||
|
||||
se = conv2d_block(se,
|
||||
num_reduced_filters,
|
||||
config,
|
||||
use_bias=True,
|
||||
use_batch_norm=False,
|
||||
activation=activation,
|
||||
name=prefix + 'se_reduce')
|
||||
se = conv2d_block(se,
|
||||
filters,
|
||||
config,
|
||||
use_bias=True,
|
||||
use_batch_norm=False,
|
||||
activation='sigmoid',
|
||||
name=prefix + 'se_expand')
|
||||
x = tf.keras.layers.multiply([x, se], name=prefix + 'se_excite')
|
||||
|
||||
# Output phase
|
||||
x = conv2d_block(x,
|
||||
block['output_filters'],
|
||||
config,
|
||||
activation=None,
|
||||
name=prefix + 'project')
|
||||
|
||||
# Add identity so that quantization-aware training can insert quantization
|
||||
# ops correctly.
|
||||
x = tf.keras.layers.Activation(get_activation('identity'),
|
||||
name=prefix + 'id')(x)
|
||||
|
||||
if (block['id_skip']
|
||||
and all(s == 1 for s in block['strides'])
|
||||
and block['input_filters'] == block['output_filters']):
|
||||
if drop_connect_rate and drop_connect_rate > 0:
|
||||
# Apply dropconnect
|
||||
# The only difference between dropout and dropconnect in TF is scaling by
|
||||
# drop_connect_rate during training. See:
|
||||
# https://github.com/keras-team/keras/pull/9898#issuecomment-380577612
|
||||
x = tf.keras.layers.Dropout(drop_connect_rate,
|
||||
noise_shape=(None, 1, 1, 1),
|
||||
name=prefix + 'drop')(x)
|
||||
|
||||
x = tf.keras.layers.add([x, inputs], name=prefix + 'add')
|
||||
|
||||
return x
|
||||
|
|
@ -0,0 +1,77 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Common modeling utilities."""
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import numpy as np
|
||||
import math
|
||||
import tensorflow as tf
|
||||
from typing import Text, Optional
|
||||
|
||||
__all__ = ['count_params', 'load_weights', 'round_filters', 'round_repeats']
|
||||
|
||||
|
||||
def count_params(model, trainable_only=True):
|
||||
"""Returns the count of all model parameters, or just trainable ones."""
|
||||
if not trainable_only:
|
||||
return model.count_params()
|
||||
else:
|
||||
return int(np.sum([tf.keras.backend.count_params(p)
|
||||
for p in model.trainable_weights]))
|
||||
|
||||
|
||||
def load_weights(model: tf.keras.Model,
|
||||
model_weights_path: Text,
|
||||
weights_format: Text = 'saved_model'):
|
||||
"""Load model weights from the given file path.
|
||||
|
||||
Args:
|
||||
model: the model to load weights into
|
||||
model_weights_path: the path of the model weights
|
||||
weights_format: the model weights format. One of 'saved_model', 'h5',
|
||||
or 'checkpoint'.
|
||||
"""
|
||||
if weights_format == 'saved_model':
|
||||
loaded_model = tf.keras.models.load_model(model_weights_path)
|
||||
model.set_weights(loaded_model.get_weights())
|
||||
else:
|
||||
model.load_weights(model_weights_path)
|
||||
|
||||
def round_filters(filters: int,
|
||||
config: dict) -> int:
|
||||
"""Round number of filters based on width coefficient."""
|
||||
width_coefficient = config['width_coefficient']
|
||||
min_depth = config['min_depth']
|
||||
divisor = config['depth_divisor']
|
||||
orig_filters = filters
|
||||
|
||||
if not width_coefficient:
|
||||
return filters
|
||||
|
||||
filters *= width_coefficient
|
||||
min_depth = min_depth or divisor
|
||||
new_filters = max(min_depth, int(filters + divisor / 2) // divisor * divisor)
|
||||
# Make sure that round down does not go down by more than 10%.
|
||||
if new_filters < 0.9 * filters:
|
||||
new_filters += divisor
|
||||
return int(new_filters)
|
||||
|
||||
|
||||
def round_repeats(repeats: int, depth_coefficient: float) -> int:
|
||||
"""Round number of repeats based on depth coefficient."""
|
||||
return int(math.ceil(depth_coefficient * repeats))
|
||||
|
|
@ -0,0 +1,323 @@
|
|||
# Lint as: python3
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Contains definitions for EfficientNet model.
|
||||
|
||||
[1] Mingxing Tan, Quoc V. Le
|
||||
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.
|
||||
ICML'19, https://arxiv.org/abs/1905.11946
|
||||
"""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import math
|
||||
import os
|
||||
from typing import Any, Dict, Optional, List, Text, Tuple
|
||||
import copy
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from model.layers import simple_swish, hard_swish, identity, gelu, get_activation
|
||||
from model.blocks import conv2d_block, mb_conv_block
|
||||
from model.common_modules import round_filters, round_repeats, load_weights
|
||||
from utils import preprocessing
|
||||
|
||||
|
||||
def build_dict(name, args=None):
|
||||
if name == "ModelConfig":
|
||||
return_dict = copy.deepcopy(ModelConfig)
|
||||
elif name == "BlockConfig":
|
||||
return_dict = copy.deepcopy(BlockConfig)
|
||||
else:
|
||||
raise ValueError("Name of requested dictionary not found!")
|
||||
if args is None:
|
||||
return return_dict
|
||||
if isinstance(args, dict):
|
||||
return_dict.update(args)
|
||||
elif isinstance(args, tuple):
|
||||
return_dict.update( {a: p for a, p in zip(list(return_dict.keys()), args)} )
|
||||
else:
|
||||
raise ValueError("Expected tuple or dict!")
|
||||
return return_dict
|
||||
|
||||
# Config for a single MB Conv Block.
|
||||
BlockConfig = {
|
||||
'input_filters': 0,
|
||||
'output_filters': 0,
|
||||
'kernel_size': 3,
|
||||
'num_repeat': 1,
|
||||
'expand_ratio': 1,
|
||||
'strides': (1, 1),
|
||||
'se_ratio': None,
|
||||
'id_skip': True,
|
||||
'fused_conv': False,
|
||||
'conv_type': 'depthwise'
|
||||
}
|
||||
|
||||
# Default Config for Efficientnet-B0.
|
||||
ModelConfig = {
|
||||
'width_coefficient': 1.0,
|
||||
'depth_coefficient': 1.0,
|
||||
'resolution': 224,
|
||||
'dropout_rate': 0.2,
|
||||
'blocks': (
|
||||
# (input_filters, output_filters, kernel_size, num_repeat,
|
||||
# expand_ratio, strides, se_ratio)
|
||||
# pylint: disable=bad-whitespace
|
||||
build_dict(name="BlockConfig", args=(32, 16, 3, 1, 1, (1, 1), 0.25)),
|
||||
build_dict(name="BlockConfig", args=(16, 24, 3, 2, 6, (2, 2), 0.25)),
|
||||
build_dict(name="BlockConfig", args=(24, 40, 5, 2, 6, (2, 2), 0.25)),
|
||||
build_dict(name="BlockConfig", args=(40, 80, 3, 3, 6, (2, 2), 0.25)),
|
||||
build_dict(name="BlockConfig", args=(80, 112, 5, 3, 6, (1, 1), 0.25)),
|
||||
build_dict(name="BlockConfig", args=(112, 192, 5, 4, 6, (2, 2), 0.25)),
|
||||
build_dict(name="BlockConfig", args=(192, 320, 3, 1, 6, (1, 1), 0.25)),
|
||||
# pylint: enable=bad-whitespace
|
||||
),
|
||||
'stem_base_filters': 32,
|
||||
'top_base_filters': 1280,
|
||||
'activation': 'simple_swish',
|
||||
'batch_norm': 'default',
|
||||
'bn_momentum': 0.99,
|
||||
'bn_epsilon': 1e-3,
|
||||
# While the original implementation used a weight decay of 1e-5,
|
||||
# tf.nn.l2_loss divides it by 2, so we halve this to compensate in Keras
|
||||
'weight_decay': 5e-6,
|
||||
'drop_connect_rate': 0.2,
|
||||
'depth_divisor': 8,
|
||||
'min_depth': None,
|
||||
'use_se': True,
|
||||
'input_channels': 3,
|
||||
'num_classes': 1000,
|
||||
'model_name': 'efficientnet',
|
||||
'rescale_input': True,
|
||||
'data_format': 'channels_last',
|
||||
'dtype': 'float32',
|
||||
'weight_init': 'fan_in',
|
||||
}
|
||||
|
||||
MODEL_CONFIGS = {
|
||||
# (width, depth, resolution, dropout)
|
||||
'efficientnet-b0': build_dict(name="ModelConfig", args=(1.0, 1.0, 224, 0.2)),
|
||||
'efficientnet-b1': build_dict(name="ModelConfig", args=(1.0, 1.1, 240, 0.2)),
|
||||
'efficientnet-b2': build_dict(name="ModelConfig", args=(1.1, 1.2, 260, 0.3)),
|
||||
'efficientnet-b3': build_dict(name="ModelConfig", args=(1.2, 1.4, 300, 0.3)),
|
||||
'efficientnet-b4': build_dict(name="ModelConfig", args=(1.4, 1.8, 380, 0.4)),
|
||||
'efficientnet-b5': build_dict(name="ModelConfig", args=(1.6, 2.2, 456, 0.4)),
|
||||
'efficientnet-b6': build_dict(name="ModelConfig", args=(1.8, 2.6, 528, 0.5)),
|
||||
'efficientnet-b7': build_dict(name="ModelConfig", args=(2.0, 3.1, 600, 0.5)),
|
||||
'efficientnet-b8': build_dict(name="ModelConfig", args=(2.2, 3.6, 672, 0.5)),
|
||||
'efficientnet-l2': build_dict(name="ModelConfig", args=(4.3, 5.3, 800, 0.5)),
|
||||
}
|
||||
|
||||
DENSE_KERNEL_INITIALIZER = {
|
||||
'class_name': 'VarianceScaling',
|
||||
'config': {
|
||||
'scale': 1 / 3.0,
|
||||
'mode': 'fan_in',
|
||||
'distribution': 'uniform'
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
def efficientnet(input: List[tf.keras.layers.Input],
|
||||
config: dict):
|
||||
"""Creates an EfficientNet graph given the model parameters.
|
||||
|
||||
This function is wrapped by the `EfficientNet` class to make a tf.keras.Model.
|
||||
|
||||
Args:
|
||||
image_input: the input batch of images
|
||||
config: the model config
|
||||
|
||||
Returns:
|
||||
the output of efficientnet
|
||||
"""
|
||||
depth_coefficient = config['depth_coefficient']
|
||||
blocks = config['blocks']
|
||||
stem_base_filters = config['stem_base_filters']
|
||||
top_base_filters = config['top_base_filters']
|
||||
activation = get_activation(config['activation'])
|
||||
dropout_rate = config['dropout_rate']
|
||||
drop_connect_rate = config['drop_connect_rate']
|
||||
num_classes = config['num_classes']
|
||||
input_channels = config['input_channels']
|
||||
rescale_input = config['rescale_input']
|
||||
data_format = tf.keras.backend.image_data_format()
|
||||
dtype = config['dtype']
|
||||
weight_decay = config['weight_decay']
|
||||
weight_init = config['weight_init']
|
||||
|
||||
# Move the mixup of images to device
|
||||
images = input[0]
|
||||
if len(input) > 1:
|
||||
mix_weight = input[1]
|
||||
x = (images * mix_weight + images[::-1] * (1. - mix_weight))
|
||||
else:
|
||||
x = images
|
||||
|
||||
if data_format == 'channels_first':
|
||||
# Happens on GPU/TPU if available.
|
||||
x = tf.keras.layers.Permute((3, 1, 2))(x)
|
||||
if rescale_input:
|
||||
x = preprocessing.normalize_images(x,
|
||||
num_channels=input_channels,
|
||||
dtype=dtype,
|
||||
data_format=data_format)
|
||||
|
||||
# Build stem
|
||||
x = conv2d_block(x,
|
||||
round_filters(stem_base_filters, config),
|
||||
config,
|
||||
kernel_size=[3, 3],
|
||||
strides=[2, 2],
|
||||
activation=activation,
|
||||
name='stem')
|
||||
|
||||
# Build blocks
|
||||
num_blocks_total = sum(
|
||||
round_repeats(block['num_repeat'], depth_coefficient) for block in blocks)
|
||||
block_num = 0
|
||||
|
||||
for stack_idx, block in enumerate(blocks):
|
||||
assert block['num_repeat'] > 0
|
||||
# Update block input and output filters based on depth multiplier
|
||||
block.update({
|
||||
'input_filters':round_filters(block['input_filters'], config),
|
||||
'output_filters':round_filters(block['output_filters'], config),
|
||||
'num_repeat':round_repeats(block['num_repeat'], depth_coefficient)})
|
||||
|
||||
# The first block needs to take care of stride and filter size increase
|
||||
drop_rate = drop_connect_rate * float(block_num) / num_blocks_total
|
||||
config.update({'drop_connect_rate': drop_rate}) # TODO(Sugh) replace
|
||||
block_prefix = 'stack_{}/block_0/'.format(stack_idx)
|
||||
x = mb_conv_block(x, block, config, block_prefix)
|
||||
block_num += 1
|
||||
if block['num_repeat'] > 1:
|
||||
block.update({
|
||||
'input_filters':block['output_filters'],
|
||||
'strides':(1, 1)
|
||||
})
|
||||
|
||||
for block_idx in range(block['num_repeat'] - 1):
|
||||
drop_rate = drop_connect_rate * float(block_num) / num_blocks_total
|
||||
config.update({'drop_connect_rate': drop_rate})
|
||||
block_prefix = 'stack_{}/block_{}/'.format(stack_idx, block_idx + 1)
|
||||
x = mb_conv_block(x, block, config, prefix=block_prefix)
|
||||
block_num += 1
|
||||
|
||||
# Build top
|
||||
x = conv2d_block(x,
|
||||
round_filters(top_base_filters, config),
|
||||
config,
|
||||
activation=activation,
|
||||
name='top')
|
||||
|
||||
# Build classifier
|
||||
DENSE_KERNEL_INITIALIZER['config']['mode'] = weight_init
|
||||
x = tf.keras.layers.GlobalAveragePooling2D(name='top_pool')(x)
|
||||
if dropout_rate and dropout_rate > 0:
|
||||
x = tf.keras.layers.Dropout(dropout_rate, name='top_dropout')(x)
|
||||
x = tf.keras.layers.Dense(
|
||||
num_classes,
|
||||
kernel_initializer=DENSE_KERNEL_INITIALIZER,
|
||||
kernel_regularizer=tf.keras.regularizers.l2(weight_decay),
|
||||
bias_regularizer=tf.keras.regularizers.l2(weight_decay),
|
||||
name='logits')(x)
|
||||
x = tf.keras.layers.Activation('softmax', name='probs', dtype=tf.float32)(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Vision')
|
||||
class EfficientNet(tf.keras.Model):
|
||||
"""Wrapper class for an EfficientNet Keras model.
|
||||
|
||||
Contains helper methods to build, manage, and save metadata about the model.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
config: Dict[Text, Any] = None,
|
||||
overrides: Dict[Text, Any] = None):
|
||||
"""Create an EfficientNet model.
|
||||
|
||||
Args:
|
||||
config: (optional) the main model parameters to create the model
|
||||
overrides: (optional) a dict containing keys that can override
|
||||
config
|
||||
"""
|
||||
overrides = overrides or {}
|
||||
is_training = overrides.pop('is_training', False)
|
||||
config = config or build_dict(name="ModelConfig")
|
||||
self.config = config
|
||||
self.config.update(overrides)
|
||||
|
||||
|
||||
input_channels = self.config['input_channels']
|
||||
model_name = self.config['model_name']
|
||||
input_shape = (None, None, input_channels) # Should handle any size image
|
||||
image_input = tf.keras.layers.Input(shape=input_shape)
|
||||
if is_training:
|
||||
beta_input = tf.keras.layers.Input(shape=(1, 1, 1))
|
||||
inputs = (image_input, beta_input)
|
||||
output = efficientnet(inputs, self.config)
|
||||
else:
|
||||
inputs = [image_input]
|
||||
output = efficientnet(inputs, self.config)
|
||||
|
||||
# Cast to float32 in case we have a different model dtype
|
||||
output = tf.cast(output, tf.float32)
|
||||
|
||||
super(EfficientNet, self).__init__(
|
||||
inputs=inputs, outputs=output, name=model_name)
|
||||
|
||||
@classmethod
|
||||
def from_name(cls,
|
||||
model_name: Text,
|
||||
model_weights_path: Text = None,
|
||||
weights_format: Text = 'saved_model',
|
||||
overrides: Dict[Text, Any] = None):
|
||||
"""Construct an EfficientNet model from a predefined model name.
|
||||
|
||||
E.g., `EfficientNet.from_name('efficientnet-b0')`.
|
||||
|
||||
Args:
|
||||
model_name: the predefined model name
|
||||
model_weights_path: the path to the weights (h5 file or saved model dir)
|
||||
weights_format: the model weights format. One of 'saved_model', 'h5',
|
||||
or 'checkpoint'.
|
||||
overrides: (optional) a dict containing keys that can override config
|
||||
|
||||
Returns:
|
||||
A constructed EfficientNet instance.
|
||||
"""
|
||||
model_configs = dict(MODEL_CONFIGS)
|
||||
overrides = dict(overrides) if overrides else {}
|
||||
|
||||
# One can define their own custom models if necessary
|
||||
model_configs.update(overrides.pop('model_config', {}))
|
||||
|
||||
if model_name not in model_configs:
|
||||
raise ValueError('Unknown model name {}'.format(model_name))
|
||||
|
||||
config = model_configs[model_name]
|
||||
|
||||
model = cls(config=config, overrides=overrides)
|
||||
|
||||
if model_weights_path:
|
||||
load_weights(model, model_weights_path, weights_format=weights_format)
|
||||
|
||||
return model
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from model.layers.activations import simple_swish, hard_swish, identity, gelu, get_activation
|
||||
from model.layers.normalization import get_batch_norm
|
||||
|
||||
__all__ = ['simple_swish', 'hard_swish', 'identity', 'gelu', 'get_activation', 'get_batch_norm']
|
||||
|
|
@ -0,0 +1,122 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Customized Swish activation."""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import six
|
||||
import math
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
__all__ = ['simple_swish', 'hard_swish', 'identity', 'gelu', 'get_activation']
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Text')
|
||||
def simple_swish(features):
|
||||
"""Computes the Swish activation function.
|
||||
|
||||
The tf.nn.swish operation uses a custom gradient to reduce memory usage.
|
||||
Since saving custom gradients in SavedModel is currently not supported, and
|
||||
one would not be able to use an exported TF-Hub module for fine-tuning, we
|
||||
provide this wrapper that can allow to select whether to use the native
|
||||
TensorFlow swish operation, or whether to use a customized operation that
|
||||
has uses default TensorFlow gradient computation.
|
||||
|
||||
Args:
|
||||
features: A `Tensor` representing preactivation values.
|
||||
|
||||
Returns:
|
||||
The activation value.
|
||||
"""
|
||||
features = tf.convert_to_tensor(features)
|
||||
return features * tf.nn.sigmoid(features)
|
||||
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Text')
|
||||
def hard_swish(features):
|
||||
"""Computes a hard version of the swish function.
|
||||
|
||||
This operation can be used to reduce computational cost and improve
|
||||
quantization for edge devices.
|
||||
|
||||
Args:
|
||||
features: A `Tensor` representing preactivation values.
|
||||
|
||||
Returns:
|
||||
The activation value.
|
||||
"""
|
||||
features = tf.convert_to_tensor(features)
|
||||
return features * tf.nn.relu6(features + tf.constant(3.)) * (1. / 6.)
|
||||
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Text')
|
||||
def identity(features):
|
||||
"""Computes the identity function.
|
||||
|
||||
Useful for helping in quantization.
|
||||
|
||||
Args:
|
||||
features: A `Tensor` representing preactivation values.
|
||||
|
||||
Returns:
|
||||
The activation value.
|
||||
"""
|
||||
features = tf.convert_to_tensor(features)
|
||||
return tf.identity(features)
|
||||
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Text')
|
||||
def gelu(x):
|
||||
"""Gaussian Error Linear Unit.
|
||||
|
||||
This is a smoother version of the RELU.
|
||||
Original paper: https://arxiv.org/abs/1606.08415
|
||||
Args:
|
||||
x: float Tensor to perform activation.
|
||||
|
||||
Returns:
|
||||
`x` with the GELU activation applied.
|
||||
"""
|
||||
cdf = 0.5 * (1.0 + tf.tanh(
|
||||
(math.sqrt(2 / math.pi) * (x + 0.044715 * tf.pow(x, 3)))))
|
||||
return x * cdf
|
||||
|
||||
# TODO(hongkuny): consider moving custom string-map lookup to keras api.
|
||||
def get_activation(identifier):
|
||||
"""Maps a identifier to a Python function, e.g., "relu" => `tf.nn.relu`.
|
||||
|
||||
It checks string first and if it is one of customized activation not in TF,
|
||||
the corresponding activation will be returned. For non-customized activation
|
||||
names and callable identifiers, always fallback to tf.keras.activations.get.
|
||||
|
||||
Args:
|
||||
identifier: String name of the activation function or callable.
|
||||
|
||||
Returns:
|
||||
A Python function corresponding to the activation function.
|
||||
"""
|
||||
if isinstance(identifier, six.string_types):
|
||||
name_to_fn = {
|
||||
"gelu": gelu,
|
||||
"simple_swish": simple_swish,
|
||||
"hard_swish": hard_swish,
|
||||
"identity": identity,
|
||||
}
|
||||
identifier = str(identifier).lower()
|
||||
if identifier in name_to_fn:
|
||||
return tf.keras.activations.get(name_to_fn[identifier])
|
||||
return tf.keras.activations.get(identifier)
|
||||
|
|
@ -0,0 +1,127 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Common modeling utilities."""
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import numpy as np
|
||||
import tensorflow as tf
|
||||
import tensorflow.compat.v1 as tf1
|
||||
from typing import Text, Optional
|
||||
|
||||
from tensorflow.python.tpu import tpu_function
|
||||
|
||||
__all__ = ['get_batch_norm']
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Vision')
|
||||
class TpuBatchNormalization(tf.keras.layers.BatchNormalization):
|
||||
"""Cross replica batch normalization."""
|
||||
|
||||
def __init__(self, fused: Optional[bool] = False, **kwargs):
|
||||
if fused in (True, None):
|
||||
raise ValueError('TpuBatchNormalization does not support fused=True.')
|
||||
super(TpuBatchNormalization, self).__init__(fused=fused, **kwargs)
|
||||
|
||||
def _cross_replica_average(self, t: tf.Tensor, num_shards_per_group: int):
|
||||
"""Calculates the average value of input tensor across TPU replicas."""
|
||||
num_shards = tpu_function.get_tpu_context().number_of_shards
|
||||
group_assignment = None
|
||||
if num_shards_per_group > 1:
|
||||
if num_shards % num_shards_per_group != 0:
|
||||
raise ValueError(
|
||||
'num_shards: %d mod shards_per_group: %d, should be 0' %
|
||||
(num_shards, num_shards_per_group))
|
||||
num_groups = num_shards // num_shards_per_group
|
||||
group_assignment = [[
|
||||
x for x in range(num_shards) if x // num_shards_per_group == y
|
||||
] for y in range(num_groups)]
|
||||
return tf1.tpu.cross_replica_sum(t, group_assignment) / tf.cast(
|
||||
num_shards_per_group, t.dtype)
|
||||
|
||||
def _moments(self, inputs: tf.Tensor, reduction_axes: int, keep_dims: int):
|
||||
"""Compute the mean and variance: it overrides the original _moments."""
|
||||
shard_mean, shard_variance = super(TpuBatchNormalization, self)._moments(
|
||||
inputs, reduction_axes, keep_dims=keep_dims)
|
||||
|
||||
num_shards = tpu_function.get_tpu_context().number_of_shards or 1
|
||||
if num_shards <= 8: # Skip cross_replica for 2x2 or smaller slices.
|
||||
num_shards_per_group = 1
|
||||
else:
|
||||
num_shards_per_group = max(8, num_shards // 8)
|
||||
if num_shards_per_group > 1:
|
||||
# Compute variance using: Var[X]= E[X^2] - E[X]^2.
|
||||
shard_square_of_mean = tf.math.square(shard_mean)
|
||||
shard_mean_of_square = shard_variance + shard_square_of_mean
|
||||
group_mean = self._cross_replica_average(shard_mean, num_shards_per_group)
|
||||
group_mean_of_square = self._cross_replica_average(
|
||||
shard_mean_of_square, num_shards_per_group)
|
||||
group_variance = group_mean_of_square - tf.math.square(group_mean)
|
||||
return (group_mean, group_variance)
|
||||
else:
|
||||
return (shard_mean, shard_variance)
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Vision')
|
||||
class SyncBatchNormalization(tf.keras.layers.BatchNormalization):
|
||||
"""Cross replica batch normalization."""
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
if not kwargs.get('name', None):
|
||||
kwargs['name'] = 'tpu_batch_normalization'
|
||||
super(SyncBatchNormalization, self).__init__(**kwargs)
|
||||
|
||||
def _moments(self, inputs, reduction_axes, keep_dims):
|
||||
"""Compute the mean and variance: it overrides the original _moments."""
|
||||
import horovod.tensorflow as hvd # pylint: disable=g-import-not-at-top
|
||||
shard_mean, shard_variance = super(SyncBatchNormalization, self)._moments(
|
||||
inputs, reduction_axes, keep_dims=keep_dims)
|
||||
|
||||
num_shards = hvd.size()
|
||||
if num_shards > 1:
|
||||
# Compute variance using: Var[X]= E[X^2] - E[X]^2.
|
||||
shard_square_of_mean = tf.math.square(shard_mean)
|
||||
shard_mean_of_square = shard_variance + shard_square_of_mean
|
||||
shard_stack = tf.stack([shard_mean, shard_mean_of_square])
|
||||
group_mean, group_mean_of_square = tf.unstack(hvd.allreduce(shard_stack))
|
||||
group_variance = group_mean_of_square - tf.math.square(group_mean)
|
||||
return (group_mean, group_variance)
|
||||
else:
|
||||
return (shard_mean, shard_variance)
|
||||
|
||||
def call(self, *args, **kwargs):
|
||||
outputs = super(SyncBatchNormalization, self).call(*args, **kwargs)
|
||||
# A temporary hack for tf1 compatibility with keras batch norm.
|
||||
# for u in self.updates:
|
||||
# tf.add_to_collection(tf.GraphKeys.UPDATE_OPS, u)
|
||||
return outputs
|
||||
|
||||
|
||||
def get_batch_norm(batch_norm_type: Text) -> tf.keras.layers.BatchNormalization:
|
||||
"""A helper to create a batch normalization getter.
|
||||
|
||||
Args:
|
||||
batch_norm_type: The type of batch normalization layer implementation. `tpu`
|
||||
will use `TpuBatchNormalization`.
|
||||
|
||||
Returns:
|
||||
An instance of `tf.keras.layers.BatchNormalization`.
|
||||
"""
|
||||
if batch_norm_type == 'tpu':
|
||||
return TpuBatchNormalization
|
||||
if batch_norm_type == 'syncbn':
|
||||
return SyncBatchNormalization
|
||||
|
||||
return tf.keras.layers.BatchNormalization
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
six
|
||||
google-api-python-client>=1.6.7
|
||||
google-cloud-bigquery>=0.31.0
|
||||
kaggle>=1.3.9
|
||||
numpy>=1.15.4
|
||||
oauth2client>=4.1.2
|
||||
pandas>=0.22.0
|
||||
psutil>=5.4.3
|
||||
py-cpuinfo>=3.3.0
|
||||
scipy>=0.19.1
|
||||
tensorflow-hub>=0.6.0
|
||||
tensorflow-model-optimization>=0.2.1
|
||||
tensorflow-datasets
|
||||
tensorflow-addons
|
||||
dataclasses
|
||||
gin-config
|
||||
tf_slim>=1.1.0
|
||||
typing
|
||||
sentencepiece
|
||||
Cython
|
||||
matplotlib
|
||||
opencv-python-headless
|
||||
pyyaml
|
||||
Pillow
|
||||
-e git+https://github.com/cocodataset/cocoapi#egg=pycocotools&subdirectory=PythonAPI
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
#!/bin/bash
|
||||
###SBATCH -t 8:00:00 # wall time
|
||||
#SBATCH --ntasks-per-node=8 # tasks per node
|
||||
#SBATCH --exclusive # exclusive node access
|
||||
#SBATCH --mem=0 # all mem avail
|
||||
#SBATCH --mail-type=FAIL # only send email on failure
|
||||
#SBATCH --overcommit # Needed for pytorch
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# Data dir
|
||||
readonly datadir="/datasets/imagenet/train-val-tfrecord"
|
||||
# Path to where trained checkpoints will be saved on the system
|
||||
readonly checkpointdir="$PWD/B0_mulitnode_AMP/"
|
||||
|
||||
CREATE_FOLDER_CMD="if [ ! -d ${checkpointdir} ]; then mkdir -p ${checkpointdir} ; fi && nvidia-smi"
|
||||
|
||||
srun --ntasks="${SLURM_JOB_NUM_NODES}" --ntasks-per-node=1 sh -c "${CREATE_FOLDER_CMD}"
|
||||
|
||||
OUTFILE="${checkpointdir}/slurm-%j.out"
|
||||
ERRFILE="${checkpointdir}/error-%j.out"
|
||||
|
||||
readonly mounts="${datadir}:/data,${checkpointdir}:/model"
|
||||
|
||||
srun -p ${PARTITION} -l -o $OUTFILE -e $ERRFILE --container-image nvcr.io/nvidia/efficientnet-tf2:21.02-tf2-py3 --container-mounts ${mounts} --mpi=pmix bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py --mode train_and_eval --arch efficientnet-b0 --model_dir /model --data_dir /data --use_amp --use_xla --lr_decay cosine --weight_init fan_out --max_epochs 500 --log_steps 100 --save_checkpoint_freq 3 --train_batch_size 1024 --eval_batch_size 1024 --lr_init 0.005 --batch_norm syncbn --resume_checkpoint --augmenter_name autoaugment --mixup_alpha 0.0 --weight_decay 5e-6 --epsilon 0.001
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
#!/bin/bash
|
||||
###SBATCH -t 8:00:00 # wall time
|
||||
#SBATCH --ntasks-per-node=8 # tasks per node
|
||||
#SBATCH --exclusive # exclusive node access
|
||||
#SBATCH --mem=0 # all mem avail
|
||||
#SBATCH --mail-type=FAIL # only send email on failure
|
||||
#SBATCH --overcommit # Needed for pytorch
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# Data dir
|
||||
readonly datadir="/datasets/imagenet/train-val-tfrecord"
|
||||
# Path to where trained checkpoints will be saved on the system
|
||||
readonly checkpointdir="$PWD/B4_mulitnode_AMP/"
|
||||
|
||||
CREATE_FOLDER_CMD="if [ ! -d ${checkpointdir} ]; then mkdir -p ${checkpointdir} ; fi && nvidia-smi"
|
||||
|
||||
srun --ntasks="${SLURM_JOB_NUM_NODES}" --ntasks-per-node=1 sh -c "${CREATE_FOLDER_CMD}"
|
||||
|
||||
OUTFILE="${checkpointdir}/slurm-%j.out"
|
||||
ERRFILE="${checkpointdir}/error-%j.out"
|
||||
|
||||
readonly mounts="${datadir}:/data,${checkpointdir}:/model"
|
||||
|
||||
srun -p ${PARTITION} -l -o $OUTFILE -e $ERRFILE --container-image nvcr.io/nvidia/efficientnet-tf2:21.02-tf2-py3 --container-mounts ${mounts} --mpi=pmix bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py --mode train_and_eval --arch efficientnet-b4 --model_dir /model --data_dir /data --use_amp --use_xla --lr_decay cosine --weight_init fan_out --max_epochs 500 --log_steps 100 --save_checkpoint_freq 3 --train_batch_size 128 --eval_batch_size 128 --lr_init 0.005 --batch_norm syncbn --resume_checkpoint --augmenter_name autoaugment --mixup_alpha 0.2 --weight_decay 5e-6 --epsilon 0.001
|
||||
|
|
@ -0,0 +1,15 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from runtime.runner import Runner
|
||||
|
|
@ -0,0 +1,296 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import multiprocessing
|
||||
import warnings
|
||||
import yaml
|
||||
import time
|
||||
|
||||
import tensorflow as tf
|
||||
import numpy as np
|
||||
|
||||
import horovod.tensorflow.keras as hvd
|
||||
|
||||
from utils import hvd_utils, optimizer_factory
|
||||
from utils import callbacks as custom_callbacks
|
||||
|
||||
from runtime.runner_utils import get_optimizer_params, get_metrics, get_learning_rate_params, \
|
||||
build_model_params, get_models, get_dataset_builders, build_stats, \
|
||||
parse_inference_input, preprocess_image_files
|
||||
|
||||
__all__ = [
|
||||
'Runner',
|
||||
]
|
||||
|
||||
DTYPE_MAP = {
|
||||
'float32': tf.float32,
|
||||
'bfloat16': tf.bfloat16,
|
||||
'float16': tf.float16,
|
||||
'fp32': tf.float32,
|
||||
'bf16': tf.bfloat16,
|
||||
}
|
||||
|
||||
class Runner(object):
|
||||
|
||||
def __init__(self, flags, logger):
|
||||
|
||||
self.params = flags
|
||||
self.logger = logger
|
||||
|
||||
if hvd.rank() == 0:
|
||||
self.serialize_config(model_dir=self.params.model_dir)
|
||||
|
||||
# =================================================
|
||||
# Define Datasets
|
||||
# =================================================
|
||||
label_smoothing = flags.label_smoothing
|
||||
self.one_hot = label_smoothing and label_smoothing > 0
|
||||
|
||||
builders = get_dataset_builders(self.params, self.one_hot)
|
||||
datasets = [builder.build() if builder else None for builder in builders]
|
||||
|
||||
self.train_dataset, self.validation_dataset = datasets
|
||||
self.train_builder, self.validation_builder = builders
|
||||
|
||||
self.initialize()
|
||||
|
||||
# =================================================
|
||||
# Define Model
|
||||
# =================================================
|
||||
model_params = build_model_params(model_name=self.params.arch,
|
||||
is_training="predict" not in self.params.mode,
|
||||
batch_norm=self.params.batch_norm,
|
||||
num_classes=self.params.num_classes,
|
||||
activation=self.params.activation,
|
||||
dtype=DTYPE_MAP[self.params.dtype],
|
||||
weight_decay=self.params.weight_decay,
|
||||
weight_init=self.params.weight_init
|
||||
)
|
||||
models_dict = get_models()
|
||||
self.model = [model for model_name, model in models_dict.items() if model_name in self.params.arch][0](**model_params)
|
||||
|
||||
self.metrics = ['accuracy', 'top_5']
|
||||
|
||||
if self.params.dataset == 'ImageNet':
|
||||
self.train_num_examples = 1281167
|
||||
self.eval_num_examples = 50000
|
||||
|
||||
def initialize(self):
|
||||
"""Initializes backend related initializations."""
|
||||
if tf.config.list_physical_devices('GPU'):
|
||||
data_format = 'channels_first'
|
||||
else:
|
||||
data_format = 'channels_last'
|
||||
tf.keras.backend.set_image_data_format(data_format)
|
||||
if self.params.run_eagerly:
|
||||
# Enable eager execution to allow step-by-step debugging
|
||||
tf.config.experimental_run_functions_eagerly(True)
|
||||
|
||||
|
||||
def load_model_weights(self, model_dir):
|
||||
latest_checkpoint = tf.train.latest_checkpoint(model_dir)
|
||||
if not latest_checkpoint:
|
||||
return 0
|
||||
|
||||
self.model.load_weights(latest_checkpoint)
|
||||
return self.model.optimizer.iterations
|
||||
|
||||
def resume_from_checkpoint(self,
|
||||
model_dir: str,
|
||||
train_steps: int) -> int:
|
||||
"""Resumes from the latest checkpoint, if possible.
|
||||
|
||||
Loads the model weights and optimizer settings from a checkpoint.
|
||||
This function should be used in case of preemption recovery.
|
||||
|
||||
Args:
|
||||
model: The model whose weights should be restored.
|
||||
model_dir: The directory where model weights were saved.
|
||||
train_steps: The number of steps to train.
|
||||
|
||||
Returns:
|
||||
The epoch of the latest checkpoint, or 0 if not restoring.
|
||||
|
||||
"""
|
||||
last_iteration = self.load_model_weights(model_dir)
|
||||
initial_epoch = last_iteration // train_steps
|
||||
return int(initial_epoch)
|
||||
|
||||
|
||||
def serialize_config(self, model_dir: str):
|
||||
"""Serializes and saves the experiment config."""
|
||||
params_save_path = os.path.join(model_dir, 'params.yaml')
|
||||
with open(params_save_path, 'w') as outfile:
|
||||
yaml.dump(vars(self.params), outfile, default_flow_style=False)
|
||||
|
||||
|
||||
def train(self):
|
||||
train_epochs = self.params.max_epochs
|
||||
train_steps = self.params.steps_per_epoch if self.params.steps_per_epoch is not None else self.train_num_examples // self.train_builder.global_batch_size
|
||||
if self.validation_builder is not None:
|
||||
validation_steps = self.eval_num_examples // self.validation_builder.global_batch_size
|
||||
else:
|
||||
validation_steps = None
|
||||
|
||||
learning_rate = optimizer_factory.build_learning_rate(
|
||||
params=get_learning_rate_params(name=self.params.lr_decay,
|
||||
initial_lr=self.params.lr_init,
|
||||
decay_epochs=self.params.lr_decay_epochs,
|
||||
decay_rate=self.params.lr_decay_rate,
|
||||
warmup_epochs=self.params.lr_warmup_epochs),
|
||||
batch_size=self.train_builder.global_batch_size,
|
||||
train_steps=train_steps,
|
||||
max_epochs=train_epochs)
|
||||
optimizer = optimizer_factory.build_optimizer(
|
||||
optimizer_name=self.params.optimizer,
|
||||
base_learning_rate=learning_rate,
|
||||
params=get_optimizer_params(name=self.params.optimizer,
|
||||
decay=self.params.decay,
|
||||
epsilon=self.params.epsilon,
|
||||
momentum=self.params.momentum,
|
||||
moving_average_decay=self.params.moving_average_decay,
|
||||
nesterov=self.params.nesterov,
|
||||
beta_1=self.params.beta_1,
|
||||
beta_2=self.params.beta_2)
|
||||
)
|
||||
|
||||
metrics_map = get_metrics(self.one_hot)
|
||||
metrics = [metrics_map[metric] for metric in self.metrics]
|
||||
|
||||
optimizer = hvd.DistributedOptimizer(optimizer, compression=hvd.Compression.fp16)
|
||||
|
||||
if self.one_hot:
|
||||
loss_obj = tf.keras.losses.CategoricalCrossentropy(
|
||||
label_smoothing=self.params.label_smoothing)
|
||||
else:
|
||||
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy()
|
||||
|
||||
# Training
|
||||
self.model.compile(optimizer=optimizer,
|
||||
loss=loss_obj,
|
||||
metrics=metrics,
|
||||
experimental_run_tf_function=False)
|
||||
|
||||
initial_epoch = 0
|
||||
if self.params.resume_checkpoint:
|
||||
initial_epoch = self.resume_from_checkpoint(model_dir=self.params.model_dir,
|
||||
train_steps=train_steps)
|
||||
|
||||
#Define Callbacks (TODO)
|
||||
callbacks=[hvd.callbacks.BroadcastGlobalVariablesCallback(0)]
|
||||
callbacks += custom_callbacks.get_callbacks(
|
||||
model_checkpoint=self.params.enable_checkpoint_and_export,
|
||||
include_tensorboard=self.params.enable_tensorboard,
|
||||
time_history=self.params.time_history,
|
||||
track_lr=True,
|
||||
write_model_weights=self.params.write_model_weights,
|
||||
initial_step=initial_epoch * train_steps,
|
||||
batch_size=self.train_builder.global_batch_size,
|
||||
log_steps=self.params.log_steps,
|
||||
model_dir=self.params.model_dir,
|
||||
save_checkpoint_freq=train_steps * self.params.save_checkpoint_freq,
|
||||
logger=self.logger)
|
||||
|
||||
if "eval" not in self.params.mode:
|
||||
validation_kwargs = {}
|
||||
else:
|
||||
validation_kwargs = {
|
||||
'validation_data': self.validation_dataset,
|
||||
'validation_steps': validation_steps,
|
||||
'validation_freq': self.params.num_epochs_between_eval,
|
||||
}
|
||||
|
||||
history = self.model.fit(
|
||||
self.train_dataset,
|
||||
epochs=train_epochs,
|
||||
steps_per_epoch=train_steps,
|
||||
initial_epoch=initial_epoch,
|
||||
callbacks=callbacks,
|
||||
verbose=2,
|
||||
**validation_kwargs)
|
||||
|
||||
validation_output = None
|
||||
eval_callback = None
|
||||
if not self.params.skip_eval and self.validation_builder is not None:
|
||||
eval_callback = custom_callbacks.EvalTimeHistory(batch_size=self.params.eval_batch_size, logger=self.logger)
|
||||
worker_validation_output = self.model.evaluate(
|
||||
self.validation_dataset, steps=validation_steps, callbacks=eval_callback, verbose=2)
|
||||
validation_output = list(hvd.allreduce(worker_validation_output,average=True))
|
||||
|
||||
build_stats(history, validation_output, callbacks, eval_callback, self.logger)
|
||||
|
||||
|
||||
def evaluate(self):
|
||||
|
||||
if self.validation_builder is not None:
|
||||
validation_steps = self.eval_num_examples // self.validation_builder.global_batch_size
|
||||
else:
|
||||
validation_steps = None
|
||||
|
||||
metrics_map = get_metrics(self.one_hot)
|
||||
metrics = [metrics_map[metric] for metric in self.metrics]
|
||||
|
||||
if self.one_hot:
|
||||
loss_obj = tf.keras.losses.CategoricalCrossentropy(
|
||||
label_smoothing=self.params.label_smoothing)
|
||||
else:
|
||||
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy()
|
||||
|
||||
# Training
|
||||
self.model.compile(optimizer="rmsprop",
|
||||
loss=loss_obj,
|
||||
metrics=metrics,
|
||||
experimental_run_tf_function=False)
|
||||
|
||||
_ = self.load_model_weights(self.params.model_dir)
|
||||
eval_callback = custom_callbacks.EvalTimeHistory(batch_size=self.params.eval_batch_size, logger=self.logger)
|
||||
results = self.model.evaluate(self.validation_dataset, steps=validation_steps, callbacks=eval_callback, verbose=1)
|
||||
build_stats(None, results, None, eval_callback, self.logger)
|
||||
|
||||
|
||||
def predict(self, to_predict, checkpoint_name=None, print_results=True):
|
||||
|
||||
images = preprocess_image_files(directory_name=to_predict, arch=self.params.arch, batch_size=self.params.predict_batch_size, dtype=DTYPE_MAP[self.params.dtype])
|
||||
nb_samples = len(images)
|
||||
if checkpoint_name is not None:
|
||||
self.model.load_weights(checkpoint_name)
|
||||
try:
|
||||
file_names = images.filenames
|
||||
num_files = len(file_names)
|
||||
if self.params.benchmark:
|
||||
nb_samples *= 50
|
||||
print_results = False
|
||||
num_files *= 50
|
||||
start_time = time.time()
|
||||
inference_results = self.model.predict(images, verbose=1, steps=nb_samples)
|
||||
total_time = time.time() - start_time
|
||||
score = tf.nn.softmax(inference_results, axis=1)
|
||||
|
||||
if print_results:
|
||||
for i, name in enumerate(file_names):
|
||||
print(
|
||||
"This {} image most likely belongs to {} class with a {} percent confidence."
|
||||
.format(name, tf.math.argmax(score[i]), 100 * tf.math.reduce_max(score[i]))
|
||||
)
|
||||
print("Total time to infer {} images :: {}".format(num_files, total_time))
|
||||
print("Inference Throughput {}".format(num_files/total_time))
|
||||
print("Inference Latency {}".format(total_time/num_files))
|
||||
|
||||
except KeyboardInterrupt:
|
||||
print("Keyboard interrupt")
|
||||
|
||||
print('Ending Inference ...')
|
||||
|
|
@ -0,0 +1,255 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import math
|
||||
|
||||
import tensorflow as tf
|
||||
import horovod.tensorflow as hvd
|
||||
|
||||
from model import efficientnet_model
|
||||
|
||||
from utils import dataset_factory, hvd_utils, callbacks, preprocessing
|
||||
|
||||
__all__ = ['get_optimizer_params', 'get_metrics', 'get_learning_rate_params', 'build_model_params', 'get_models', 'build_augmenter_params', \
|
||||
'get_image_size_from_model', 'get_dataset_builders', 'build_stats', 'parse_inference_input', 'preprocess_image_files']
|
||||
|
||||
def get_optimizer_params(name,
|
||||
decay,
|
||||
epsilon,
|
||||
momentum,
|
||||
moving_average_decay,
|
||||
nesterov,
|
||||
beta_1,
|
||||
beta_2):
|
||||
return {
|
||||
'name': name,
|
||||
'decay': decay,
|
||||
'epsilon': epsilon,
|
||||
'momentum': momentum,
|
||||
'moving_average_decay': moving_average_decay,
|
||||
'nesterov': nesterov,
|
||||
'beta_1': beta_1,
|
||||
'beta_2': beta_2
|
||||
}
|
||||
|
||||
|
||||
def get_metrics(one_hot: bool):
|
||||
"""Get a dict of available metrics to track."""
|
||||
if one_hot:
|
||||
return {
|
||||
# (name, metric_fn)
|
||||
'acc': tf.keras.metrics.CategoricalAccuracy(name='accuracy'),
|
||||
'accuracy': tf.keras.metrics.CategoricalAccuracy(name='accuracy'),
|
||||
'top_1': tf.keras.metrics.CategoricalAccuracy(name='accuracy'),
|
||||
'top_5': tf.keras.metrics.TopKCategoricalAccuracy(
|
||||
k=5,
|
||||
name='top_5_accuracy'),
|
||||
}
|
||||
else:
|
||||
return {
|
||||
# (name, metric_fn)
|
||||
'acc': tf.keras.metrics.SparseCategoricalAccuracy(name='accuracy'),
|
||||
'accuracy': tf.keras.metrics.SparseCategoricalAccuracy(name='accuracy'),
|
||||
'top_1': tf.keras.metrics.SparseCategoricalAccuracy(name='accuracy'),
|
||||
'top_5': tf.keras.metrics.SparseTopKCategoricalAccuracy(
|
||||
k=5,
|
||||
name='top_5_accuracy'),
|
||||
}
|
||||
|
||||
def get_learning_rate_params(name,
|
||||
initial_lr,
|
||||
decay_epochs,
|
||||
decay_rate,
|
||||
warmup_epochs):
|
||||
return {
|
||||
'name':name,
|
||||
'initial_lr': initial_lr,
|
||||
'decay_epochs': decay_epochs,
|
||||
'decay_rate': decay_rate,
|
||||
'warmup_epochs': warmup_epochs,
|
||||
'examples_per_epoch': None,
|
||||
'boundaries': None,
|
||||
'multipliers': None,
|
||||
'scale_by_batch_size': 1./128.,
|
||||
'staircase': True
|
||||
}
|
||||
|
||||
|
||||
def build_model_params(model_name, is_training, batch_norm, num_classes, activation, dtype, weight_decay, weight_init):
|
||||
return {
|
||||
'model_name': model_name,
|
||||
'model_weights_path': '',
|
||||
'weights_format': 'saved_model',
|
||||
'overrides': {
|
||||
'is_training': is_training,
|
||||
'batch_norm': batch_norm,
|
||||
'rescale_input': True,
|
||||
'num_classes': num_classes,
|
||||
'weight_decay': weight_decay,
|
||||
'activation': activation,
|
||||
'dtype': dtype,
|
||||
'weight_init': weight_init
|
||||
}
|
||||
}
|
||||
|
||||
def get_models():
|
||||
"""Returns the mapping from model type name to Keras model."""
|
||||
return {
|
||||
'efficientnet': efficientnet_model.EfficientNet.from_name,
|
||||
}
|
||||
|
||||
def build_augmenter_params(augmenter_name, cutout_const, translate_const, num_layers, magnitude, autoaugmentation_name):
|
||||
if augmenter_name is None or augmenter_name not in ['randaugment', 'autoaugment']:
|
||||
return {}
|
||||
augmenter_params = {}
|
||||
if cutout_const is not None:
|
||||
augmenter_params['cutout_const'] = cutout_const
|
||||
if translate_const is not None:
|
||||
augmenter_params['translate_const'] = translate_const
|
||||
if augmenter_name == 'randaugment':
|
||||
if num_layers is not None:
|
||||
augmenter_params['num_layers'] = num_layers
|
||||
if magnitude is not None:
|
||||
augmenter_params['magnitude'] = magnitude
|
||||
if augmenter_name == 'autoaugment':
|
||||
if autoaugmentation_name is not None:
|
||||
augmenter_params['autoaugmentation_name'] = autoaugmentation_name
|
||||
|
||||
return augmenter_params
|
||||
|
||||
def get_image_size_from_model(arch):
|
||||
"""If the given model has a preferred image size, return it."""
|
||||
if 'efficientnet' in arch:
|
||||
efficientnet_name = arch
|
||||
if efficientnet_name in efficientnet_model.MODEL_CONFIGS:
|
||||
return efficientnet_model.MODEL_CONFIGS[efficientnet_name]['resolution']
|
||||
return None
|
||||
|
||||
def get_dataset_builders(params, one_hot):
|
||||
"""Create and return train and validation dataset builders."""
|
||||
if hvd.size() > 1:
|
||||
num_gpus = hvd.size()
|
||||
else:
|
||||
num_devices = 1
|
||||
|
||||
image_size = get_image_size_from_model(params.arch)
|
||||
print("Image size {}".format(image_size))
|
||||
print("Train batch size {}".format(params.train_batch_size))
|
||||
builders = []
|
||||
validation_dataset_builder = None
|
||||
train_dataset_builder = None
|
||||
if "train" in params.mode:
|
||||
train_dataset_builder = dataset_factory.Dataset(data_dir=params.data_dir,
|
||||
index_file_dir=params.index_file,
|
||||
split='train',
|
||||
num_classes=params.num_classes,
|
||||
image_size=image_size,
|
||||
batch_size=params.train_batch_size,
|
||||
one_hot=one_hot,
|
||||
use_dali=params.use_dali,
|
||||
augmenter=params.augmenter_name,
|
||||
augmenter_params=build_augmenter_params(params.augmenter_name,
|
||||
params.cutout_const,
|
||||
params.translate_const,
|
||||
params.num_layers,
|
||||
params.magnitude,
|
||||
params.autoaugmentation_name),
|
||||
mixup_alpha=params.mixup_alpha
|
||||
)
|
||||
if "eval" in params.mode:
|
||||
validation_dataset_builder = dataset_factory.Dataset(data_dir=params.data_dir,
|
||||
index_file_dir=params.index_file,
|
||||
split='validation',
|
||||
num_classes=params.num_classes,
|
||||
image_size=image_size,
|
||||
batch_size=params.eval_batch_size,
|
||||
one_hot=one_hot,
|
||||
use_dali=params.use_dali_eval)
|
||||
|
||||
builders.append(train_dataset_builder)
|
||||
builders.append(validation_dataset_builder)
|
||||
|
||||
return builders
|
||||
|
||||
def build_stats(history, validation_output, train_callbacks, eval_callback, logger):
|
||||
stats = {}
|
||||
if validation_output:
|
||||
stats['eval_loss'] = float(validation_output[0])
|
||||
stats['eval_accuracy_top_1'] = float(validation_output[1])
|
||||
stats['eval_accuracy_top_5'] = float(validation_output[2])
|
||||
#This part is train loss on GPU_0
|
||||
if history and history.history:
|
||||
train_hist = history.history
|
||||
#Gets final loss from training.
|
||||
stats['training_loss'] = float(hvd.allreduce(tf.constant(train_hist['loss'][-1], dtype=tf.float32), average=True))
|
||||
# Gets top_1 training accuracy.
|
||||
if 'categorical_accuracy' in train_hist:
|
||||
stats['training_accuracy_top_1'] = float(hvd.allreduce(tf.constant(train_hist['categorical_accuracy'][-1], dtype=tf.float32), average=True))
|
||||
elif 'sparse_categorical_accuracy' in train_hist:
|
||||
stats['training_accuracy_top_1'] = float(hvd.allreduce(tf.constant(train_hist['sparse_categorical_accuracy'][-1], dtype=tf.float32), average=True))
|
||||
elif 'accuracy' in train_hist:
|
||||
stats['training_accuracy_top_1'] = float(hvd.allreduce(tf.constant(train_hist['accuracy'][-1], dtype=tf.float32), average=True))
|
||||
stats['training_accuracy_top_5'] = float(hvd.allreduce(tf.constant(train_hist['top_5_accuracy'][-1], dtype=tf.float32), average=True))
|
||||
|
||||
# Look for the time history callback which was used during keras.fit
|
||||
if train_callbacks:
|
||||
for callback in train_callbacks:
|
||||
if isinstance(callback, callbacks.TimeHistory):
|
||||
if callback.epoch_runtime_log:
|
||||
stats['avg_exp_per_second_training'] = callback.average_examples_per_second
|
||||
stats['avg_exp_per_second_training_per_GPU'] = callback.average_examples_per_second / hvd.size()
|
||||
|
||||
if eval_callback:
|
||||
stats['avg_exp_per_second_eval'] = float(eval_callback.average_examples_per_second) * hvd.size()
|
||||
stats['avg_exp_per_second_eval_per_GPU'] = float(eval_callback.average_examples_per_second)
|
||||
stats['avg_time_per_exp_eval'] = 1000./stats['avg_exp_per_second_eval']
|
||||
batch_time = eval_callback.batch_time
|
||||
batch_time.sort()
|
||||
latency_90pct_per_batch = sum( batch_time[:int( 0.9 * len(batch_time) )] ) / int( 0.9 * len(batch_time) )
|
||||
stats['latency_90pct'] = 1000.0 * latency_90pct_per_batch / eval_callback.batch_size
|
||||
latency_95pct_per_batch = sum( batch_time[:int( 0.95 * len(batch_time) )] ) / int( 0.95 * len(batch_time) )
|
||||
stats['latency_95pct'] = 1000.0 * latency_95pct_per_batch / eval_callback.batch_size
|
||||
latency_99pct_per_batch = sum( batch_time[:int( 0.99 * len(batch_time) )] ) / int( 0.99 * len(batch_time) )
|
||||
stats['latency_99pct'] = 1000.0 * latency_99pct_per_batch / eval_callback.batch_size
|
||||
|
||||
if not hvd_utils.is_using_hvd() or hvd.rank() == 0:
|
||||
logger.log(step=(), data=stats)
|
||||
|
||||
|
||||
def preprocess_image_files(directory_name, arch, batch_size, num_channels=3, dtype=tf.float32):
|
||||
image_size = get_image_size_from_model(arch)
|
||||
|
||||
datagen = tf.keras.preprocessing.image.ImageDataGenerator(data_format="channels_last")
|
||||
images = datagen.flow_from_directory(directory_name, class_mode=None, batch_size=batch_size, target_size=(image_size, image_size), shuffle=False)
|
||||
return images
|
||||
|
||||
|
||||
def parse_inference_input(to_predict):
|
||||
|
||||
filenames = []
|
||||
|
||||
image_formats = ['.jpg', '.jpeg', '.JPEG', '.JPG', '.png', '.PNG']
|
||||
|
||||
if os.path.isdir(to_predict):
|
||||
filenames = [f for f in os.listdir(to_predict)
|
||||
if os.path.isfile(os.path.join(to_predict, f))
|
||||
and os.path.splitext(f)[1] in image_formats]
|
||||
|
||||
elif os.path.isfile(to_predict):
|
||||
filenames.append(to_predict)
|
||||
|
||||
return filenames
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 1024 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 256 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 128 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 512 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/infer_data"
|
||||
INDX="./index_file"
|
||||
|
||||
python3 main.py --mode "predict" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--to_predict "/infer_data/" \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--predict_batch_size 8
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/infer_data"
|
||||
INDX="./index_file"
|
||||
|
||||
python3 main.py --mode "predict" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--to_predict "/infer_data/" \
|
||||
--use_xla \
|
||||
--predict_batch_size 8
|
||||
|
|
@ -0,0 +1,41 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 1024 \
|
||||
--eval_batch_size 1024 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,41 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 256 \
|
||||
--eval_batch_size 256 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,41 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 3 \
|
||||
--train_batch_size 1024 \
|
||||
--eval_batch_size 1024 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,41 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 256 \
|
||||
--eval_batch_size 256 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 128 \
|
||||
--eval_batch_size 128 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 128 \
|
||||
--eval_batch_size 128 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 512 \
|
||||
--eval_batch_size 512 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b0" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 512 \
|
||||
--eval_batch_size 512 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.0 \
|
||||
--weight_decay 5e-6 \
|
||||
--epsilon 0.001 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 128 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 64 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 32 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--max_epochs 1 \
|
||||
--eval_batch_size 64 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/infer_data"
|
||||
INDX="./index_file"
|
||||
|
||||
python3 main.py --mode "predict" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--to_predict "/infer_data/" \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--predict_batch_size 8
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/infer_data"
|
||||
INDX="./index_file"
|
||||
|
||||
python3 main.py --mode "predict" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--to_predict "/infer_data/" \
|
||||
--use_xla \
|
||||
--predict_batch_size 8
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 160 \
|
||||
--eval_batch_size 160 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 64 \
|
||||
--eval_batch_size 64 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 2 \
|
||||
--train_batch_size 160 \
|
||||
--eval_batch_size 160 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_amp \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 2 \
|
||||
--train_batch_size 64 \
|
||||
--eval_batch_size 64 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 32 \
|
||||
--eval_batch_size 32 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 2 \
|
||||
--train_batch_size 32 \
|
||||
--eval_batch_size 32 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 80 \
|
||||
--eval_batch_size 80 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
MODEL_DIR="./output"
|
||||
DATA_DIR="/data"
|
||||
INDX="./index_file"
|
||||
|
||||
# TF_XLA_FLAGS=--tf_xla_cpu_global_jit
|
||||
|
||||
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
|
||||
--mode "train_and_eval" \
|
||||
--arch "efficientnet-b4" \
|
||||
--model_dir $MODEL_DIR \
|
||||
--data_dir $DATA_DIR \
|
||||
--use_xla \
|
||||
--augmenter_name autoaugment \
|
||||
--weight_init fan_out \
|
||||
--lr_decay cosine \
|
||||
--max_epochs 500 \
|
||||
--train_batch_size 80 \
|
||||
--eval_batch_size 80 \
|
||||
--log_steps 100 \
|
||||
--save_checkpoint_freq 5 \
|
||||
--lr_init 0.005 \
|
||||
--batch_norm syncbn \
|
||||
--mixup_alpha 0.2 \
|
||||
--weight_decay 5e-6 \
|
||||
--resume_checkpoint
|
||||
227
TensorFlow2/Classification/ConvNets/efficientnet/scripts/bind.sh
Normal file
227
TensorFlow2/Classification/ConvNets/efficientnet/scripts/bind.sh
Normal file
|
|
@ -0,0 +1,227 @@
|
|||
#! /bin/bash
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
set -euo pipefail
|
||||
|
||||
print_usage() {
|
||||
cat << EOF
|
||||
${0} [options] [--] COMMAND [ARG...]
|
||||
|
||||
Control binding policy for each task. Assumes one rank will be launched for each GPU.
|
||||
|
||||
Options:
|
||||
--cpu=MODE
|
||||
* exclusive -- bind each rank to an exclusive set of cores near its GPU
|
||||
* exclusive,nosmt -- bind each rank to an exclusive set of cores near its GPU, without hyperthreading
|
||||
* node -- bind each rank to all cores in the NUMA node nearest its GPU [default]
|
||||
* *.sh -- bind each rank using the bash associative array bind_cpu_cores or bind_cpu_nodes from a file
|
||||
* off -- don't bind
|
||||
--mem=MODE
|
||||
* node -- bind each rank to the nearest NUMA node [default]
|
||||
* *.sh -- bind each rank using the bash associative array bind_mem from a file
|
||||
* off -- don't bind
|
||||
--ib=MODE
|
||||
* single -- bind each rank to a single IB device near its GPU
|
||||
* off -- don't bind [default]
|
||||
--cluster=CLUSTER
|
||||
Select which cluster is being used. May be required if system params cannot be detected.
|
||||
EOF
|
||||
}
|
||||
|
||||
################################################################################
|
||||
# Argument parsing
|
||||
################################################################################
|
||||
|
||||
cpu_mode='node'
|
||||
mem_mode='node'
|
||||
ib_mode='off'
|
||||
cluster=''
|
||||
while [ $# -gt 0 ]; do
|
||||
case "$1" in
|
||||
-h|--help) print_usage ; exit 0 ;;
|
||||
--cpu=*) cpu_mode="${1/*=/}"; shift ;;
|
||||
--cpu) cpu_mode="$2"; shift 2 ;;
|
||||
--mem=*) mem_mode="${1/*=/}"; shift ;;
|
||||
--mem) mem_mode="$2"; shift 2 ;;
|
||||
--ib=*) ib_mode="${1/*=/}"; shift ;;
|
||||
--ib) ib_mode="$2"; shift 2 ;;
|
||||
--cluster=*) cluster="${1/*=/}"; shift ;;
|
||||
--cluster) cluster="$2"; shift 2 ;;
|
||||
--) shift; break ;;
|
||||
*) break ;;
|
||||
esac
|
||||
done
|
||||
if [ $# -lt 1 ]; then
|
||||
echo 'ERROR: no command given' 2>&1
|
||||
print_usage
|
||||
exit 1
|
||||
fi
|
||||
|
||||
################################################################################
|
||||
# Get system params
|
||||
################################################################################
|
||||
|
||||
# LOCAL_RANK is set with an enroot hook for Pytorch containers
|
||||
# SLURM_LOCALID is set by Slurm
|
||||
# OMPI_COMM_WORLD_LOCAL_RANK is set by mpirun
|
||||
readonly local_rank="${LOCAL_RANK:=${SLURM_LOCALID:=${OMPI_COMM_WORLD_LOCAL_RANK:-}}}"
|
||||
if [ -z "${local_rank}" ]; then
|
||||
echo 'ERROR: cannot read LOCAL_RANK from env' >&2
|
||||
exit 1
|
||||
fi
|
||||
|
||||
num_gpus=$(nvidia-smi -i 0 --query-gpu=count --format=csv,noheader,nounits)
|
||||
if [ "${local_rank}" -ge "${num_gpus}" ]; then
|
||||
echo "ERROR: local rank is ${local_rank}, but there are only ${num_gpus} gpus available" >&2
|
||||
exit 1
|
||||
fi
|
||||
|
||||
get_lscpu_value() {
|
||||
awk -F: "(\$1 == \"${1}\"){gsub(/ /, \"\", \$2); print \$2; found=1} END{exit found!=1}"
|
||||
}
|
||||
lscpu_out=$(lscpu)
|
||||
num_sockets=$(get_lscpu_value 'Socket(s)' <<< "${lscpu_out}")
|
||||
num_nodes=$(get_lscpu_value 'NUMA node(s)' <<< "${lscpu_out}")
|
||||
cores_per_socket=$(get_lscpu_value 'Core(s) per socket' <<< "${lscpu_out}")
|
||||
|
||||
echo "num_sockets = ${num_sockets} num_nodes=${num_nodes} cores_per_socket=${cores_per_socket}"
|
||||
|
||||
readonly cores_per_node=$(( (num_sockets * cores_per_socket) / num_nodes ))
|
||||
if [ ${num_gpus} -gt 1 ]; then
|
||||
readonly gpus_per_node=$(( num_gpus / num_nodes ))
|
||||
else
|
||||
readonly gpus_per_node=1
|
||||
fi
|
||||
readonly cores_per_gpu=$(( cores_per_node / gpus_per_node ))
|
||||
readonly local_node=$(( local_rank / gpus_per_node ))
|
||||
|
||||
|
||||
declare -a ibdevs=()
|
||||
case "${cluster}" in
|
||||
circe)
|
||||
# Need to specialize for circe because IB detection is hard
|
||||
ibdevs=(mlx5_1 mlx5_2 mlx5_3 mlx5_4 mlx5_7 mlx5_8 mlx5_9 mlx5_10)
|
||||
;;
|
||||
selene)
|
||||
# Need to specialize for selene because IB detection is hard
|
||||
ibdevs=(mlx5_0 mlx5_1 mlx5_2 mlx5_3 mlx5_6 mlx5_7 mlx5_8 mlx5_9)
|
||||
;;
|
||||
'')
|
||||
if ibstat_out="$(ibstat -l 2>/dev/null | sort -V)" ; then
|
||||
mapfile -t ibdevs <<< "${ibstat_out}"
|
||||
fi
|
||||
;;
|
||||
*)
|
||||
echo "ERROR: Unknown cluster '${cluster}'" >&2
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
readonly num_ibdevs="${#ibdevs[@]}"
|
||||
|
||||
################################################################################
|
||||
# Setup for exec
|
||||
################################################################################
|
||||
|
||||
declare -a numactl_args=()
|
||||
|
||||
case "${cpu_mode}" in
|
||||
exclusive)
|
||||
numactl_args+=( "$(printf -- "--physcpubind=%u-%u,%u-%u" \
|
||||
$(( local_rank * cores_per_gpu )) \
|
||||
$(( (local_rank + 1) * cores_per_gpu - 1 )) \
|
||||
$(( local_rank * cores_per_gpu + (cores_per_gpu * gpus_per_node * num_nodes) )) \
|
||||
$(( (local_rank + 1) * cores_per_gpu + (cores_per_gpu * gpus_per_node * num_nodes) - 1 )) \
|
||||
)" )
|
||||
;;
|
||||
exclusive,nosmt)
|
||||
numactl_args+=( "$(printf -- "--physcpubind=%u-%u" \
|
||||
$(( local_rank * cores_per_gpu )) \
|
||||
$(( (local_rank + 1) * cores_per_gpu - 1 )) \
|
||||
)" )
|
||||
;;
|
||||
node)
|
||||
numactl_args+=( "--cpunodebind=${local_node}" )
|
||||
;;
|
||||
*.sh)
|
||||
source "${cpu_mode}"
|
||||
if [ -n "${bind_cpu_cores:-}" ]; then
|
||||
numactl_args+=( "--physcpubind=${bind_cpu_cores[${local_rank}]}" )
|
||||
elif [ -n "${bind_cpu_nodes:-}" ]; then
|
||||
numactl_args+=( "--cpunodebind=${bind_cpu_nodes[${local_rank}]}" )
|
||||
else
|
||||
echo "ERROR: invalid CPU affinity file ${cpu_mode}." >&2
|
||||
exit 1
|
||||
fi
|
||||
;;
|
||||
off|'')
|
||||
;;
|
||||
*)
|
||||
echo "ERROR: invalid cpu mode '${cpu_mode}'" 2>&1
|
||||
print_usage
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
|
||||
case "${mem_mode}" in
|
||||
node)
|
||||
numactl_args+=( "--membind=${local_node}" )
|
||||
;;
|
||||
*.sh)
|
||||
source "${mem_mode}"
|
||||
if [ -z "${bind_mem:-}" ]; then
|
||||
echo "ERROR: invalid memory affinity file ${mem_mode}." >&2
|
||||
exit 1
|
||||
fi
|
||||
numactl_args+=( "--membind=${bind_mem[${local_rank}]}" )
|
||||
;;
|
||||
off|'')
|
||||
;;
|
||||
*)
|
||||
echo "ERROR: invalid mem mode '${mem_mode}'" 2>&1
|
||||
print_usage
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
|
||||
case "${ib_mode}" in
|
||||
single)
|
||||
if [ "${num_ibdevs}" -eq 0 ]; then
|
||||
echo "WARNING: used '$0 --ib=single', but there are 0 IB devices available; skipping IB binding." 2>&1
|
||||
else
|
||||
readonly ibdev="${ibdevs[$(( local_rank * num_ibdevs / num_gpus ))]}"
|
||||
export OMPI_MCA_btl_openib_if_include="${OMPI_MCA_btl_openib_if_include-$ibdev}"
|
||||
export UCX_NET_DEVICES="${UCX_NET_DEVICES-$ibdev:1}"
|
||||
fi
|
||||
;;
|
||||
off|'')
|
||||
;;
|
||||
*)
|
||||
echo "ERROR: invalid ib mode '${ib_mode}'" 2>&1
|
||||
print_usage
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
|
||||
################################################################################
|
||||
# Exec
|
||||
################################################################################
|
||||
|
||||
if [ "${#numactl_args[@]}" -gt 0 ] ; then
|
||||
set -x
|
||||
exec numactl "${numactl_args[@]}" -- "${@}"
|
||||
else
|
||||
exec "${@}"
|
||||
fi
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
#!/bin/bash
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
SRC_DIR=${1}
|
||||
DST_DIR=${2}
|
||||
|
||||
echo "Creating training file indexes"
|
||||
mkdir -p ${DST_DIR}
|
||||
|
||||
for file in ${SRC_DIR}/train-*; do
|
||||
BASENAME=$(basename $file)
|
||||
DST_NAME=$DST_DIR/$BASENAME
|
||||
|
||||
echo "Creating index $DST_NAME for $file"
|
||||
tfrecord2idx $file $DST_NAME
|
||||
done
|
||||
|
||||
echo "Creating validation file indexes"
|
||||
for file in ${SRC_DIR}/validation-*; do
|
||||
BASENAME=$(basename $file)
|
||||
DST_NAME=$DST_DIR/$BASENAME
|
||||
|
||||
echo "Creating index $DST_NAME for $file"
|
||||
tfrecord2idx $file $DST_NAME
|
||||
done
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
#!/bin/bash
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
CONTAINER_TF2x_BASE="nvcr.io/nvidia/tensorflow"
|
||||
CONTAINER_TF2x_TAG="21.02-tf2-py3"
|
||||
# ======================== Refresh base image ======================== #
|
||||
docker pull "${CONTAINER_TF2x_BASE}:${CONTAINER_TF2x_TAG}"
|
||||
# ========================== Build container ========================= #
|
||||
echo -e "\n\nBuilding Effnet_test Container\n\n"
|
||||
|
||||
sleep 1
|
||||
|
||||
docker build -t nvcr.io/nvidia/efficientnet-tf2:21.02-tf2-py3 \
|
||||
--build-arg FROM_IMAGE_NAME="nvcr.io/nvidia/tensorflow:21.02-tf2-py3" \
|
||||
.
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
#!/bin/bash
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
nvidia-docker run -it --rm --net=host --runtime=nvidia --ipc=host --cap-add=SYS_PTRACE --cap-add SYS_ADMIN --cap-add DAC_READ_SEARCH --security-opt seccomp=unconfined \
|
||||
-v $(pwd)/:/workspace/ \
|
||||
-v "/imagenet_tfrecords":/data/ \
|
||||
-v "/imagenet_infer/":/infer_data/images/ \
|
||||
nvcr.io/nvidia/efficientnet-tf2:21.02-tf2-py3
|
||||
123
TensorFlow2/Classification/ConvNets/efficientnet/utils/Dali.py
Normal file
123
TensorFlow2/Classification/ConvNets/efficientnet/utils/Dali.py
Normal file
|
|
@ -0,0 +1,123 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import sys
|
||||
|
||||
import tensorflow as tf
|
||||
import horovod.tensorflow.keras as hvd
|
||||
|
||||
from nvidia import dali
|
||||
import nvidia.dali.plugin.tf as dali_tf
|
||||
import numpy as np
|
||||
|
||||
class DaliPipeline(dali.pipeline.Pipeline):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
tfrec_filenames,
|
||||
tfrec_idx_filenames,
|
||||
height,
|
||||
width,
|
||||
batch_size,
|
||||
num_threads,
|
||||
device_id,
|
||||
shard_id,
|
||||
num_gpus,
|
||||
num_classes,
|
||||
deterministic=False,
|
||||
dali_cpu=True,
|
||||
training=True
|
||||
):
|
||||
|
||||
kwargs = dict()
|
||||
if deterministic:
|
||||
kwargs['seed'] = 7 * (1 + hvd.rank())
|
||||
super(DaliPipeline, self).__init__(batch_size, num_threads, device_id, **kwargs)
|
||||
|
||||
self.training = training
|
||||
self.input = dali.ops.TFRecordReader(
|
||||
path=tfrec_filenames,
|
||||
index_path=tfrec_idx_filenames,
|
||||
random_shuffle=True,
|
||||
shard_id=shard_id,
|
||||
num_shards=num_gpus,
|
||||
initial_fill=10000,
|
||||
features={
|
||||
'image/encoded': dali.tfrecord.FixedLenFeature((), dali.tfrecord.string, ""),
|
||||
'image/class/label': dali.tfrecord.FixedLenFeature([1], dali.tfrecord.int64, -1),
|
||||
'image/class/text': dali.tfrecord.FixedLenFeature([], dali.tfrecord.string, ''),
|
||||
'image/object/bbox/xmin': dali.tfrecord.VarLenFeature(dali.tfrecord.float32, 0.0),
|
||||
'image/object/bbox/ymin': dali.tfrecord.VarLenFeature(dali.tfrecord.float32, 0.0),
|
||||
'image/object/bbox/xmax': dali.tfrecord.VarLenFeature(dali.tfrecord.float32, 0.0),
|
||||
'image/object/bbox/ymax': dali.tfrecord.VarLenFeature(dali.tfrecord.float32, 0.0)
|
||||
}
|
||||
)
|
||||
|
||||
if self.training:
|
||||
self.decode = dali.ops.ImageDecoderRandomCrop(
|
||||
device="cpu" if dali_cpu else "mixed",
|
||||
output_type=dali.types.RGB,
|
||||
random_aspect_ratio=[0.75, 1.33],
|
||||
random_area=[0.05, 1.0],
|
||||
num_attempts=100
|
||||
)
|
||||
self.resize = dali.ops.Resize(device="cpu" if dali_cpu else "gpu", resize_x=width, resize_y=height)
|
||||
else:
|
||||
self.decode = dali.ops.ImageDecoder(
|
||||
device="cpu",
|
||||
output_type=dali.types.RGB
|
||||
)
|
||||
# Make sure that every image > 224 for CropMirrorNormalize
|
||||
self.resize = dali.ops.Resize(device="cpu" if dali_cpu else "gpu", resize_x=width, resize_y=height)
|
||||
|
||||
self.normalize = dali.ops.CropMirrorNormalize(
|
||||
device="gpu",
|
||||
output_dtype=dali.types.FLOAT,
|
||||
image_type=dali.types.RGB,
|
||||
output_layout=dali.types.NHWC,
|
||||
mirror=1 if self.training else 0
|
||||
)
|
||||
self.one_hot = dali.ops.OneHot(num_classes=num_classes)
|
||||
self.shapes = dali.ops.Shapes(type=dali.types.INT32)
|
||||
self.crop = dali.ops.Crop(device="gpu")
|
||||
self.cast_float = dali.ops.Cast(dtype=dali.types.FLOAT)
|
||||
self.extract_h = dali.ops.Slice(normalized_anchor=False, normalized_shape=False, axes=[0])
|
||||
self.extract_w = dali.ops.Slice(normalized_anchor=False, normalized_shape=False, axes=[0])
|
||||
|
||||
def define_graph(self):
|
||||
# Read images and labels
|
||||
inputs = self.input(name="Reader")
|
||||
images = inputs["image/encoded"]
|
||||
labels = inputs["image/class/label"]
|
||||
labels -= 1
|
||||
labels = self.one_hot(labels).gpu()
|
||||
|
||||
# Decode and augmentation
|
||||
images = self.decode(images)
|
||||
if not self.training:
|
||||
shapes = self.shapes(images)
|
||||
h = self.extract_h(shapes, dali.types.Constant(np.array([0], dtype=np.float32)), dali.types.Constant(np.array([1], dtype=np.float32)))
|
||||
w = self.extract_w(shapes, dali.types.Constant(np.array([1], dtype=np.float32)), dali.types.Constant(np.array([1], dtype=np.float32)))
|
||||
CROP_PADDING = 32
|
||||
CROP_H = h * h / (h + CROP_PADDING)
|
||||
CROP_W = w * w / (w + CROP_PADDING)
|
||||
CROP_H = self.cast_float(CROP_H)
|
||||
CROP_W = self.cast_float(CROP_W)
|
||||
images = images.gpu()
|
||||
images = self.crop(images, crop_h = CROP_H, crop_w = CROP_W)
|
||||
images = self.resize(images)
|
||||
images = self.normalize(images)
|
||||
|
||||
|
||||
return (images, labels)
|
||||
|
|
@ -0,0 +1,999 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""AutoAugment and RandAugment policies for enhanced image preprocessing.
|
||||
|
||||
AutoAugment Reference: https://arxiv.org/abs/1805.09501
|
||||
RandAugment Reference: https://arxiv.org/abs/1909.13719
|
||||
"""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import math
|
||||
import tensorflow as tf
|
||||
from typing import Any, Dict, List, Optional, Text, Tuple
|
||||
|
||||
from tensorflow.python.keras.layers.preprocessing import image_preprocessing as image_ops
|
||||
|
||||
# This signifies the max integer that the controller RNN could predict for the
|
||||
# augmentation scheme.
|
||||
_MAX_LEVEL = 10.
|
||||
|
||||
|
||||
def to_4d(image: tf.Tensor) -> tf.Tensor:
|
||||
"""Converts an input Tensor to 4 dimensions.
|
||||
|
||||
4D image => [N, H, W, C] or [N, C, H, W]
|
||||
3D image => [1, H, W, C] or [1, C, H, W]
|
||||
2D image => [1, H, W, 1]
|
||||
|
||||
Args:
|
||||
image: The 2/3/4D input tensor.
|
||||
|
||||
Returns:
|
||||
A 4D image tensor.
|
||||
|
||||
Raises:
|
||||
`TypeError` if `image` is not a 2/3/4D tensor.
|
||||
|
||||
"""
|
||||
shape = tf.shape(image)
|
||||
original_rank = tf.rank(image)
|
||||
left_pad = tf.cast(tf.less_equal(original_rank, 3), dtype=tf.int32)
|
||||
right_pad = tf.cast(tf.equal(original_rank, 2), dtype=tf.int32)
|
||||
new_shape = tf.concat(
|
||||
[
|
||||
tf.ones(shape=left_pad, dtype=tf.int32),
|
||||
shape,
|
||||
tf.ones(shape=right_pad, dtype=tf.int32),
|
||||
],
|
||||
axis=0,
|
||||
)
|
||||
return tf.reshape(image, new_shape)
|
||||
|
||||
|
||||
def from_4d(image: tf.Tensor, ndims: tf.Tensor) -> tf.Tensor:
|
||||
"""Converts a 4D image back to `ndims` rank."""
|
||||
shape = tf.shape(image)
|
||||
begin = tf.cast(tf.less_equal(ndims, 3), dtype=tf.int32)
|
||||
end = 4 - tf.cast(tf.equal(ndims, 2), dtype=tf.int32)
|
||||
new_shape = shape[begin:end]
|
||||
return tf.reshape(image, new_shape)
|
||||
|
||||
|
||||
def _convert_translation_to_transform(translations: tf.Tensor) -> tf.Tensor:
|
||||
"""Converts translations to a projective transform.
|
||||
|
||||
The translation matrix looks like this:
|
||||
[[1 0 -dx]
|
||||
[0 1 -dy]
|
||||
[0 0 1]]
|
||||
|
||||
Args:
|
||||
translations: The 2-element list representing [dx, dy], or a matrix of
|
||||
2-element lists representing [dx dy] to translate for each image. The
|
||||
shape must be static.
|
||||
|
||||
Returns:
|
||||
The transformation matrix of shape (num_images, 8).
|
||||
|
||||
Raises:
|
||||
`TypeError` if
|
||||
- the shape of `translations` is not known or
|
||||
- the shape of `translations` is not rank 1 or 2.
|
||||
|
||||
"""
|
||||
translations = tf.convert_to_tensor(translations, dtype=tf.float32)
|
||||
if translations.get_shape().ndims is None:
|
||||
raise TypeError('translations rank must be statically known')
|
||||
elif len(translations.get_shape()) == 1:
|
||||
translations = translations[None]
|
||||
elif len(translations.get_shape()) != 2:
|
||||
raise TypeError('translations should have rank 1 or 2.')
|
||||
num_translations = tf.shape(translations)[0]
|
||||
|
||||
return tf.concat(
|
||||
values=[
|
||||
tf.ones((num_translations, 1), tf.dtypes.float32),
|
||||
tf.zeros((num_translations, 1), tf.dtypes.float32),
|
||||
-translations[:, 0, None],
|
||||
tf.zeros((num_translations, 1), tf.dtypes.float32),
|
||||
tf.ones((num_translations, 1), tf.dtypes.float32),
|
||||
-translations[:, 1, None],
|
||||
tf.zeros((num_translations, 2), tf.dtypes.float32),
|
||||
],
|
||||
axis=1,
|
||||
)
|
||||
|
||||
|
||||
def _convert_angles_to_transform(
|
||||
angles: tf.Tensor,
|
||||
image_width: tf.Tensor,
|
||||
image_height: tf.Tensor) -> tf.Tensor:
|
||||
"""Converts an angle or angles to a projective transform.
|
||||
|
||||
Args:
|
||||
angles: A scalar to rotate all images, or a vector to rotate a batch of
|
||||
images. This must be a scalar.
|
||||
image_width: The width of the image(s) to be transformed.
|
||||
image_height: The height of the image(s) to be transformed.
|
||||
|
||||
Returns:
|
||||
A tensor of shape (num_images, 8).
|
||||
|
||||
Raises:
|
||||
`TypeError` if `angles` is not rank 0 or 1.
|
||||
|
||||
"""
|
||||
angles = tf.convert_to_tensor(angles, dtype=tf.float32)
|
||||
if len(angles.get_shape()) == 0: # pylint:disable=g-explicit-length-test
|
||||
angles = angles[None]
|
||||
elif len(angles.get_shape()) != 1:
|
||||
raise TypeError('Angles should have a rank 0 or 1.')
|
||||
x_offset = ((image_width - 1) -
|
||||
(tf.math.cos(angles) * (image_width - 1) - tf.math.sin(angles) *
|
||||
(image_height - 1))) / 2.0
|
||||
y_offset = ((image_height - 1) -
|
||||
(tf.math.sin(angles) * (image_width - 1) + tf.math.cos(angles) *
|
||||
(image_height - 1))) / 2.0
|
||||
num_angles = tf.shape(angles)[0]
|
||||
return tf.concat(
|
||||
values=[
|
||||
tf.math.cos(angles)[:, None],
|
||||
-tf.math.sin(angles)[:, None],
|
||||
x_offset[:, None],
|
||||
tf.math.sin(angles)[:, None],
|
||||
tf.math.cos(angles)[:, None],
|
||||
y_offset[:, None],
|
||||
tf.zeros((num_angles, 2), tf.dtypes.float32),
|
||||
],
|
||||
axis=1,
|
||||
)
|
||||
|
||||
|
||||
def transform(image: tf.Tensor, transforms) -> tf.Tensor:
|
||||
"""Prepares input data for `image_ops.transform`."""
|
||||
original_ndims = tf.rank(image)
|
||||
transforms = tf.convert_to_tensor(transforms, dtype=tf.float32)
|
||||
if transforms.shape.rank == 1:
|
||||
transforms = transforms[None]
|
||||
image = to_4d(image)
|
||||
image = image_ops.transform(
|
||||
images=image,
|
||||
transforms=transforms,
|
||||
interpolation='nearest')
|
||||
return from_4d(image, original_ndims)
|
||||
|
||||
|
||||
def translate(image: tf.Tensor, translations) -> tf.Tensor:
|
||||
"""Translates image(s) by provided vectors.
|
||||
|
||||
Args:
|
||||
image: An image Tensor of type uint8.
|
||||
translations: A vector or matrix representing [dx dy].
|
||||
|
||||
Returns:
|
||||
The translated version of the image.
|
||||
|
||||
"""
|
||||
transforms = _convert_translation_to_transform(translations)
|
||||
return transform(image, transforms=transforms)
|
||||
|
||||
|
||||
def rotate(image: tf.Tensor, degrees: float) -> tf.Tensor:
|
||||
"""Rotates the image by degrees either clockwise or counterclockwise.
|
||||
|
||||
Args:
|
||||
image: An image Tensor of type uint8.
|
||||
degrees: Float, a scalar angle in degrees to rotate all images by. If
|
||||
degrees is positive the image will be rotated clockwise otherwise it will
|
||||
be rotated counterclockwise.
|
||||
|
||||
Returns:
|
||||
The rotated version of image.
|
||||
|
||||
"""
|
||||
# Convert from degrees to radians.
|
||||
degrees_to_radians = math.pi / 180.0
|
||||
radians = tf.cast(degrees * degrees_to_radians, tf.float32)
|
||||
|
||||
original_ndims = tf.rank(image)
|
||||
image = to_4d(image)
|
||||
|
||||
image_height = tf.cast(tf.shape(image)[1], tf.float32)
|
||||
image_width = tf.cast(tf.shape(image)[2], tf.float32)
|
||||
transforms = _convert_angles_to_transform(angles=radians,
|
||||
image_width=image_width,
|
||||
image_height=image_height)
|
||||
# In practice, we should randomize the rotation degrees by flipping
|
||||
# it negatively half the time, but that's done on 'degrees' outside
|
||||
# of the function.
|
||||
image = transform(image, transforms=transforms)
|
||||
return from_4d(image, original_ndims)
|
||||
|
||||
|
||||
def blend(image1: tf.Tensor, image2: tf.Tensor, factor: float) -> tf.Tensor:
|
||||
"""Blend image1 and image2 using 'factor'.
|
||||
|
||||
Factor can be above 0.0. A value of 0.0 means only image1 is used.
|
||||
A value of 1.0 means only image2 is used. A value between 0.0 and
|
||||
1.0 means we linearly interpolate the pixel values between the two
|
||||
images. A value greater than 1.0 "extrapolates" the difference
|
||||
between the two pixel values, and we clip the results to values
|
||||
between 0 and 255.
|
||||
|
||||
Args:
|
||||
image1: An image Tensor of type uint8.
|
||||
image2: An image Tensor of type uint8.
|
||||
factor: A floating point value above 0.0.
|
||||
|
||||
Returns:
|
||||
A blended image Tensor of type uint8.
|
||||
"""
|
||||
if factor == 0.0:
|
||||
return tf.convert_to_tensor(image1)
|
||||
if factor == 1.0:
|
||||
return tf.convert_to_tensor(image2)
|
||||
|
||||
image1 = tf.cast(image1, tf.float32)
|
||||
image2 = tf.cast(image2, tf.float32)
|
||||
|
||||
difference = image2 - image1
|
||||
scaled = factor * difference
|
||||
|
||||
# Do addition in float.
|
||||
temp = tf.cast(image1, tf.float32) + scaled
|
||||
|
||||
# Interpolate
|
||||
if factor > 0.0 and factor < 1.0:
|
||||
# Interpolation means we always stay within 0 and 255.
|
||||
return tf.cast(temp, tf.uint8)
|
||||
|
||||
# Extrapolate:
|
||||
#
|
||||
# We need to clip and then cast.
|
||||
return tf.cast(tf.clip_by_value(temp, 0.0, 255.0), tf.uint8)
|
||||
|
||||
|
||||
def cutout(image: tf.Tensor, pad_size: int, replace: int = 0) -> tf.Tensor:
|
||||
"""Apply cutout (https://arxiv.org/abs/1708.04552) to image.
|
||||
|
||||
This operation applies a (2*pad_size x 2*pad_size) mask of zeros to
|
||||
a random location within `img`. The pixel values filled in will be of the
|
||||
value `replace`. The located where the mask will be applied is randomly
|
||||
chosen uniformly over the whole image.
|
||||
|
||||
Args:
|
||||
image: An image Tensor of type uint8.
|
||||
pad_size: Specifies how big the zero mask that will be generated is that
|
||||
is applied to the image. The mask will be of size
|
||||
(2*pad_size x 2*pad_size).
|
||||
replace: What pixel value to fill in the image in the area that has
|
||||
the cutout mask applied to it.
|
||||
|
||||
Returns:
|
||||
An image Tensor that is of type uint8.
|
||||
"""
|
||||
image_height = tf.shape(image)[0]
|
||||
image_width = tf.shape(image)[1]
|
||||
|
||||
# Sample the center location in the image where the zero mask will be applied.
|
||||
cutout_center_height = tf.random.uniform(
|
||||
shape=[], minval=0, maxval=image_height,
|
||||
dtype=tf.int32)
|
||||
|
||||
cutout_center_width = tf.random.uniform(
|
||||
shape=[], minval=0, maxval=image_width,
|
||||
dtype=tf.int32)
|
||||
|
||||
lower_pad = tf.maximum(0, cutout_center_height - pad_size)
|
||||
upper_pad = tf.maximum(0, image_height - cutout_center_height - pad_size)
|
||||
left_pad = tf.maximum(0, cutout_center_width - pad_size)
|
||||
right_pad = tf.maximum(0, image_width - cutout_center_width - pad_size)
|
||||
|
||||
cutout_shape = [image_height - (lower_pad + upper_pad),
|
||||
image_width - (left_pad + right_pad)]
|
||||
padding_dims = [[lower_pad, upper_pad], [left_pad, right_pad]]
|
||||
mask = tf.pad(
|
||||
tf.zeros(cutout_shape, dtype=image.dtype),
|
||||
padding_dims, constant_values=1)
|
||||
mask = tf.expand_dims(mask, -1)
|
||||
mask = tf.tile(mask, [1, 1, 3])
|
||||
image = tf.where(
|
||||
tf.equal(mask, 0),
|
||||
tf.ones_like(image, dtype=image.dtype) * replace,
|
||||
image)
|
||||
return image
|
||||
|
||||
|
||||
def solarize(image: tf.Tensor, threshold: int = 128) -> tf.Tensor:
|
||||
# For each pixel in the image, select the pixel
|
||||
# if the value is less than the threshold.
|
||||
# Otherwise, subtract 255 from the pixel.
|
||||
return tf.where(image < threshold, image, 255 - image)
|
||||
|
||||
|
||||
def solarize_add(image: tf.Tensor,
|
||||
addition: int = 0,
|
||||
threshold: int = 128) -> tf.Tensor:
|
||||
# For each pixel in the image less than threshold
|
||||
# we add 'addition' amount to it and then clip the
|
||||
# pixel value to be between 0 and 255. The value
|
||||
# of 'addition' is between -128 and 128.
|
||||
added_image = tf.cast(image, tf.int64) + addition
|
||||
added_image = tf.cast(tf.clip_by_value(added_image, 0, 255), tf.uint8)
|
||||
return tf.where(image < threshold, added_image, image)
|
||||
|
||||
|
||||
def color(image: tf.Tensor, factor: float) -> tf.Tensor:
|
||||
"""Equivalent of PIL Color."""
|
||||
degenerate = tf.image.grayscale_to_rgb(tf.image.rgb_to_grayscale(image))
|
||||
return blend(degenerate, image, factor)
|
||||
|
||||
|
||||
def contrast(image: tf.Tensor, factor: float) -> tf.Tensor:
|
||||
"""Equivalent of PIL Contrast."""
|
||||
degenerate = tf.image.rgb_to_grayscale(image)
|
||||
# Cast before calling tf.histogram.
|
||||
degenerate = tf.cast(degenerate, tf.int32)
|
||||
|
||||
# Compute the grayscale histogram, then compute the mean pixel value,
|
||||
# and create a constant image size of that value. Use that as the
|
||||
# blending degenerate target of the original image.
|
||||
hist = tf.histogram_fixed_width(degenerate, [0, 255], nbins=256)
|
||||
mean = tf.reduce_sum(tf.cast(hist, tf.float32)) / 256.0
|
||||
degenerate = tf.ones_like(degenerate, dtype=tf.float32) * mean
|
||||
degenerate = tf.clip_by_value(degenerate, 0.0, 255.0)
|
||||
degenerate = tf.image.grayscale_to_rgb(tf.cast(degenerate, tf.uint8))
|
||||
return blend(degenerate, image, factor)
|
||||
|
||||
|
||||
def brightness(image: tf.Tensor, factor: float) -> tf.Tensor:
|
||||
"""Equivalent of PIL Brightness."""
|
||||
degenerate = tf.zeros_like(image)
|
||||
return blend(degenerate, image, factor)
|
||||
|
||||
|
||||
def posterize(image: tf.Tensor, bits: int) -> tf.Tensor:
|
||||
"""Equivalent of PIL Posterize."""
|
||||
shift = 8 - bits
|
||||
return tf.bitwise.left_shift(tf.bitwise.right_shift(image, shift), shift)
|
||||
|
||||
|
||||
def wrapped_rotate(image: tf.Tensor, degrees: float, replace: int) -> tf.Tensor:
|
||||
"""Applies rotation with wrap/unwrap."""
|
||||
image = rotate(wrap(image), degrees=degrees)
|
||||
return unwrap(image, replace)
|
||||
|
||||
|
||||
def translate_x(image: tf.Tensor, pixels: int, replace: int) -> tf.Tensor:
|
||||
"""Equivalent of PIL Translate in X dimension."""
|
||||
image = translate(wrap(image), [-pixels, 0])
|
||||
return unwrap(image, replace)
|
||||
|
||||
|
||||
def translate_y(image: tf.Tensor, pixels: int, replace: int) -> tf.Tensor:
|
||||
"""Equivalent of PIL Translate in Y dimension."""
|
||||
image = translate(wrap(image), [0, -pixels])
|
||||
return unwrap(image, replace)
|
||||
|
||||
|
||||
def shear_x(image: tf.Tensor, level: float, replace: int) -> tf.Tensor:
|
||||
"""Equivalent of PIL Shearing in X dimension."""
|
||||
# Shear parallel to x axis is a projective transform
|
||||
# with a matrix form of:
|
||||
# [1 level
|
||||
# 0 1].
|
||||
image = transform(image=wrap(image),
|
||||
transforms=[1., level, 0., 0., 1., 0., 0., 0.])
|
||||
return unwrap(image, replace)
|
||||
|
||||
|
||||
def shear_y(image: tf.Tensor, level: float, replace: int) -> tf.Tensor:
|
||||
"""Equivalent of PIL Shearing in Y dimension."""
|
||||
# Shear parallel to y axis is a projective transform
|
||||
# with a matrix form of:
|
||||
# [1 0
|
||||
# level 1].
|
||||
image = transform(image=wrap(image),
|
||||
transforms=[1., 0., 0., level, 1., 0., 0., 0.])
|
||||
return unwrap(image, replace)
|
||||
|
||||
|
||||
def autocontrast(image: tf.Tensor) -> tf.Tensor:
|
||||
"""Implements Autocontrast function from PIL using TF ops.
|
||||
|
||||
Args:
|
||||
image: A 3D uint8 tensor.
|
||||
|
||||
Returns:
|
||||
The image after it has had autocontrast applied to it and will be of type
|
||||
uint8.
|
||||
"""
|
||||
|
||||
def scale_channel(image: tf.Tensor) -> tf.Tensor:
|
||||
"""Scale the 2D image using the autocontrast rule."""
|
||||
# A possibly cheaper version can be done using cumsum/unique_with_counts
|
||||
# over the histogram values, rather than iterating over the entire image.
|
||||
# to compute mins and maxes.
|
||||
lo = tf.cast(tf.reduce_min(image), tf.float32)
|
||||
hi = tf.cast(tf.reduce_max(image), tf.float32)
|
||||
|
||||
# Scale the image, making the lowest value 0 and the highest value 255.
|
||||
def scale_values(im):
|
||||
scale = 255.0 / (hi - lo)
|
||||
offset = -lo * scale
|
||||
im = tf.cast(im, tf.float32) * scale + offset
|
||||
im = tf.clip_by_value(im, 0.0, 255.0)
|
||||
return tf.cast(im, tf.uint8)
|
||||
|
||||
result = tf.cond(hi > lo, lambda: scale_values(image), lambda: image)
|
||||
return result
|
||||
|
||||
# Assumes RGB for now. Scales each channel independently
|
||||
# and then stacks the result.
|
||||
s1 = scale_channel(image[:, :, 0])
|
||||
s2 = scale_channel(image[:, :, 1])
|
||||
s3 = scale_channel(image[:, :, 2])
|
||||
image = tf.stack([s1, s2, s3], 2)
|
||||
return image
|
||||
|
||||
|
||||
def sharpness(image: tf.Tensor, factor: float) -> tf.Tensor:
|
||||
"""Implements Sharpness function from PIL using TF ops."""
|
||||
orig_image = image
|
||||
image = tf.cast(image, tf.float32)
|
||||
# Make image 4D for conv operation.
|
||||
image = tf.expand_dims(image, 0)
|
||||
# SMOOTH PIL Kernel.
|
||||
kernel = tf.constant(
|
||||
[[1, 1, 1], [1, 5, 1], [1, 1, 1]], dtype=tf.float32,
|
||||
shape=[3, 3, 1, 1]) / 13.
|
||||
# Tile across channel dimension.
|
||||
kernel = tf.tile(kernel, [1, 1, 3, 1])
|
||||
strides = [1, 1, 1, 1]
|
||||
degenerate = tf.nn.depthwise_conv2d(
|
||||
image, kernel, strides, padding='VALID', dilations=[1, 1])
|
||||
degenerate = tf.clip_by_value(degenerate, 0.0, 255.0)
|
||||
degenerate = tf.squeeze(tf.cast(degenerate, tf.uint8), [0])
|
||||
|
||||
# For the borders of the resulting image, fill in the values of the
|
||||
# original image.
|
||||
mask = tf.ones_like(degenerate)
|
||||
padded_mask = tf.pad(mask, [[1, 1], [1, 1], [0, 0]])
|
||||
padded_degenerate = tf.pad(degenerate, [[1, 1], [1, 1], [0, 0]])
|
||||
result = tf.where(tf.equal(padded_mask, 1), padded_degenerate, orig_image)
|
||||
|
||||
# Blend the final result.
|
||||
return blend(result, orig_image, factor)
|
||||
|
||||
|
||||
def equalize(image: tf.Tensor) -> tf.Tensor:
|
||||
"""Implements Equalize function from PIL using TF ops."""
|
||||
def scale_channel(im, c):
|
||||
"""Scale the data in the channel to implement equalize."""
|
||||
im = tf.cast(im[:, :, c], tf.int32)
|
||||
# Compute the histogram of the image channel.
|
||||
histo = tf.histogram_fixed_width(im, [0, 255], nbins=256)
|
||||
|
||||
# For the purposes of computing the step, filter out the nonzeros.
|
||||
nonzero = tf.where(tf.not_equal(histo, 0))
|
||||
nonzero_histo = tf.reshape(tf.gather(histo, nonzero), [-1])
|
||||
step = (tf.reduce_sum(nonzero_histo) - nonzero_histo[-1]) // 255
|
||||
|
||||
def build_lut(histo, step):
|
||||
# Compute the cumulative sum, shifting by step // 2
|
||||
# and then normalization by step.
|
||||
lut = (tf.cumsum(histo) + (step // 2)) // step
|
||||
# Shift lut, prepending with 0.
|
||||
lut = tf.concat([[0], lut[:-1]], 0)
|
||||
# Clip the counts to be in range. This is done
|
||||
# in the C code for image.point.
|
||||
return tf.clip_by_value(lut, 0, 255)
|
||||
|
||||
# If step is zero, return the original image. Otherwise, build
|
||||
# lut from the full histogram and step and then index from it.
|
||||
result = tf.cond(tf.equal(step, 0),
|
||||
lambda: im,
|
||||
lambda: tf.gather(build_lut(histo, step), im))
|
||||
|
||||
return tf.cast(result, tf.uint8)
|
||||
|
||||
# Assumes RGB for now. Scales each channel independently
|
||||
# and then stacks the result.
|
||||
s1 = scale_channel(image, 0)
|
||||
s2 = scale_channel(image, 1)
|
||||
s3 = scale_channel(image, 2)
|
||||
image = tf.stack([s1, s2, s3], 2)
|
||||
return image
|
||||
|
||||
|
||||
def invert(image: tf.Tensor) -> tf.Tensor:
|
||||
"""Inverts the image pixels."""
|
||||
image = tf.convert_to_tensor(image)
|
||||
return 255 - image
|
||||
|
||||
|
||||
def wrap(image: tf.Tensor) -> tf.Tensor:
|
||||
"""Returns 'image' with an extra channel set to all 1s."""
|
||||
shape = tf.shape(image)
|
||||
extended_channel = tf.ones([shape[0], shape[1], 1], image.dtype)
|
||||
extended = tf.concat([image, extended_channel], axis=2)
|
||||
return extended
|
||||
|
||||
|
||||
def unwrap(image: tf.Tensor, replace: int) -> tf.Tensor:
|
||||
"""Unwraps an image produced by wrap.
|
||||
|
||||
Where there is a 0 in the last channel for every spatial position,
|
||||
the rest of the three channels in that spatial dimension are grayed
|
||||
(set to 128). Operations like translate and shear on a wrapped
|
||||
Tensor will leave 0s in empty locations. Some transformations look
|
||||
at the intensity of values to do preprocessing, and we want these
|
||||
empty pixels to assume the 'average' value, rather than pure black.
|
||||
|
||||
|
||||
Args:
|
||||
image: A 3D Image Tensor with 4 channels.
|
||||
replace: A one or three value 1D tensor to fill empty pixels.
|
||||
|
||||
Returns:
|
||||
image: A 3D image Tensor with 3 channels.
|
||||
"""
|
||||
image_shape = tf.shape(image)
|
||||
# Flatten the spatial dimensions.
|
||||
flattened_image = tf.reshape(image, [-1, image_shape[2]])
|
||||
|
||||
# Find all pixels where the last channel is zero.
|
||||
alpha_channel = tf.expand_dims(flattened_image[:, 3], axis=-1)
|
||||
|
||||
replace = tf.concat([replace, tf.ones([1], image.dtype)], 0)
|
||||
|
||||
# Where they are zero, fill them in with 'replace'.
|
||||
flattened_image = tf.where(
|
||||
tf.equal(alpha_channel, 0),
|
||||
tf.ones_like(flattened_image, dtype=image.dtype) * replace,
|
||||
flattened_image)
|
||||
|
||||
image = tf.reshape(flattened_image, image_shape)
|
||||
image = tf.slice(image, [0, 0, 0], [image_shape[0], image_shape[1], 3])
|
||||
return image
|
||||
|
||||
|
||||
def _randomly_negate_tensor(tensor):
|
||||
"""With 50% prob turn the tensor negative."""
|
||||
should_flip = tf.cast(tf.floor(tf.random.uniform([]) + 0.5), tf.bool)
|
||||
final_tensor = tf.cond(should_flip, lambda: tensor, lambda: -tensor)
|
||||
return final_tensor
|
||||
|
||||
|
||||
def _rotate_level_to_arg(level: float):
|
||||
level = (level/_MAX_LEVEL) * 30.
|
||||
level = _randomly_negate_tensor(level)
|
||||
return (level,)
|
||||
|
||||
|
||||
def _shrink_level_to_arg(level: float):
|
||||
"""Converts level to ratio by which we shrink the image content."""
|
||||
if level == 0:
|
||||
return (1.0,) # if level is zero, do not shrink the image
|
||||
# Maximum shrinking ratio is 2.9.
|
||||
level = 2. / (_MAX_LEVEL / level) + 0.9
|
||||
return (level,)
|
||||
|
||||
|
||||
def _enhance_level_to_arg(level: float):
|
||||
return ((level/_MAX_LEVEL) * 1.8 + 0.1,)
|
||||
|
||||
|
||||
def _shear_level_to_arg(level: float):
|
||||
level = (level/_MAX_LEVEL) * 0.3
|
||||
# Flip level to negative with 50% chance.
|
||||
level = _randomly_negate_tensor(level)
|
||||
return (level,)
|
||||
|
||||
|
||||
def _translate_level_to_arg(level: float, translate_const: float):
|
||||
level = (level/_MAX_LEVEL) * float(translate_const)
|
||||
# Flip level to negative with 50% chance.
|
||||
level = _randomly_negate_tensor(level)
|
||||
return (level,)
|
||||
|
||||
|
||||
def _mult_to_arg(level: float, multiplier: float = 1.):
|
||||
return (int((level / _MAX_LEVEL) * multiplier),)
|
||||
|
||||
|
||||
def _apply_func_with_prob(func: Any,
|
||||
image: tf.Tensor,
|
||||
args: Any,
|
||||
prob: float):
|
||||
"""Apply `func` to image w/ `args` as input with probability `prob`."""
|
||||
assert isinstance(args, tuple)
|
||||
|
||||
# Apply the function with probability `prob`.
|
||||
should_apply_op = tf.cast(
|
||||
tf.floor(tf.random.uniform([], dtype=tf.float32) + prob), tf.bool)
|
||||
augmented_image = tf.cond(
|
||||
should_apply_op,
|
||||
lambda: func(image, *args),
|
||||
lambda: image)
|
||||
return augmented_image
|
||||
|
||||
|
||||
def select_and_apply_random_policy(policies: Any, image: tf.Tensor):
|
||||
"""Select a random policy from `policies` and apply it to `image`."""
|
||||
policy_to_select = tf.random.uniform([], maxval=len(policies), dtype=tf.int32)
|
||||
# Note that using tf.case instead of tf.conds would result in significantly
|
||||
# larger graphs and would even break export for some larger policies.
|
||||
for (i, policy) in enumerate(policies):
|
||||
image = tf.cond(
|
||||
tf.equal(i, policy_to_select),
|
||||
lambda selected_policy=policy: selected_policy(image),
|
||||
lambda: image)
|
||||
return image
|
||||
|
||||
|
||||
NAME_TO_FUNC = {
|
||||
'AutoContrast': autocontrast,
|
||||
'Equalize': equalize,
|
||||
'Invert': invert,
|
||||
'Rotate': wrapped_rotate,
|
||||
'Posterize': posterize,
|
||||
'Solarize': solarize,
|
||||
'SolarizeAdd': solarize_add,
|
||||
'Color': color,
|
||||
'Contrast': contrast,
|
||||
'Brightness': brightness,
|
||||
'Sharpness': sharpness,
|
||||
'ShearX': shear_x,
|
||||
'ShearY': shear_y,
|
||||
'TranslateX': translate_x,
|
||||
'TranslateY': translate_y,
|
||||
'Cutout': cutout,
|
||||
}
|
||||
|
||||
# Functions that have a 'replace' parameter
|
||||
REPLACE_FUNCS = frozenset({
|
||||
'Rotate',
|
||||
'TranslateX',
|
||||
'ShearX',
|
||||
'ShearY',
|
||||
'TranslateY',
|
||||
'Cutout',
|
||||
})
|
||||
|
||||
|
||||
def level_to_arg(cutout_const: float, translate_const: float):
|
||||
"""Creates a dict mapping image operation names to their arguments."""
|
||||
|
||||
no_arg = lambda level: ()
|
||||
posterize_arg = lambda level: _mult_to_arg(level, 4)
|
||||
solarize_arg = lambda level: _mult_to_arg(level, 256)
|
||||
solarize_add_arg = lambda level: _mult_to_arg(level, 110)
|
||||
cutout_arg = lambda level: _mult_to_arg(level, cutout_const)
|
||||
translate_arg = lambda level: _translate_level_to_arg(level, translate_const)
|
||||
|
||||
args = {
|
||||
'AutoContrast': no_arg,
|
||||
'Equalize': no_arg,
|
||||
'Invert': no_arg,
|
||||
'Rotate': _rotate_level_to_arg,
|
||||
'Posterize': posterize_arg,
|
||||
'Solarize': solarize_arg,
|
||||
'SolarizeAdd': solarize_add_arg,
|
||||
'Color': _enhance_level_to_arg,
|
||||
'Contrast': _enhance_level_to_arg,
|
||||
'Brightness': _enhance_level_to_arg,
|
||||
'Sharpness': _enhance_level_to_arg,
|
||||
'ShearX': _shear_level_to_arg,
|
||||
'ShearY': _shear_level_to_arg,
|
||||
'Cutout': cutout_arg,
|
||||
'TranslateX': translate_arg,
|
||||
'TranslateY': translate_arg,
|
||||
}
|
||||
return args
|
||||
|
||||
|
||||
def _parse_policy_info(name: Text,
|
||||
prob: float,
|
||||
level: float,
|
||||
replace_value: List[int],
|
||||
cutout_const: float,
|
||||
translate_const: float) -> Tuple[Any, float, Any]:
|
||||
"""Return the function that corresponds to `name` and update `level` param."""
|
||||
func = NAME_TO_FUNC[name]
|
||||
args = level_to_arg(cutout_const, translate_const)[name](level)
|
||||
|
||||
if name in REPLACE_FUNCS:
|
||||
# Add in replace arg if it is required for the function that is called.
|
||||
args = tuple(list(args) + [replace_value])
|
||||
|
||||
return func, prob, args
|
||||
|
||||
|
||||
class ImageAugment(object):
|
||||
"""Image augmentation class for applying image distortions."""
|
||||
|
||||
def distort(self, image: tf.Tensor) -> tf.Tensor:
|
||||
"""Given an image tensor, returns a distorted image with the same shape.
|
||||
|
||||
Args:
|
||||
image: `Tensor` of shape [height, width, 3] representing an image.
|
||||
|
||||
Returns:
|
||||
The augmented version of `image`.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
class AutoAugment(ImageAugment):
|
||||
"""Applies the AutoAugment policy to images.
|
||||
|
||||
AutoAugment is from the paper: https://arxiv.org/abs/1805.09501.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
augmentation_name: Text = 'v0',
|
||||
policies: Optional[Dict[Text, Any]] = None,
|
||||
cutout_const: float = 100,
|
||||
translate_const: float = 250):
|
||||
"""Applies the AutoAugment policy to images.
|
||||
|
||||
Args:
|
||||
augmentation_name: The name of the AutoAugment policy to use. The
|
||||
available options are `v0` and `test`. `v0` is the policy used for all
|
||||
of the results in the paper and was found to achieve the best results on
|
||||
the COCO dataset. `v1`, `v2` and `v3` are additional good policies found
|
||||
on the COCO dataset that have slight variation in what operations were
|
||||
used during the search procedure along with how many operations are
|
||||
applied in parallel to a single image (2 vs 3).
|
||||
policies: list of lists of tuples in the form `(func, prob, level)`,
|
||||
`func` is a string name of the augmentation function, `prob` is the
|
||||
probability of applying the `func` operation, `level` is the input
|
||||
argument for `func`.
|
||||
cutout_const: multiplier for applying cutout.
|
||||
translate_const: multiplier for applying translation.
|
||||
"""
|
||||
super(AutoAugment, self).__init__()
|
||||
|
||||
|
||||
if policies is None:
|
||||
self.available_policies = {
|
||||
'v0': self.policy_v0(),
|
||||
'test': self.policy_test(),
|
||||
'simple': self.policy_simple(),
|
||||
}
|
||||
|
||||
if augmentation_name not in self.available_policies:
|
||||
raise ValueError(
|
||||
'Invalid augmentation_name: {}'.format(augmentation_name))
|
||||
|
||||
self.augmentation_name = augmentation_name
|
||||
self.policies = self.available_policies[augmentation_name]
|
||||
self.cutout_const = float(cutout_const)
|
||||
self.translate_const = float(translate_const)
|
||||
|
||||
def distort(self, image: tf.Tensor) -> tf.Tensor:
|
||||
"""Applies the AutoAugment policy to `image`.
|
||||
|
||||
AutoAugment is from the paper: https://arxiv.org/abs/1805.09501.
|
||||
|
||||
Args:
|
||||
image: `Tensor` of shape [height, width, 3] representing an image.
|
||||
|
||||
Returns:
|
||||
A version of image that now has data augmentation applied to it based on
|
||||
the `policies` pass into the function.
|
||||
"""
|
||||
input_image_type = image.dtype
|
||||
|
||||
if input_image_type != tf.uint8:
|
||||
image = tf.clip_by_value(image, 0.0, 255.0)
|
||||
image = tf.cast(image, dtype=tf.uint8)
|
||||
|
||||
replace_value = [128] * 3
|
||||
|
||||
# func is the string name of the augmentation function, prob is the
|
||||
# probability of applying the operation and level is the parameter
|
||||
# associated with the tf op.
|
||||
|
||||
# tf_policies are functions that take in an image and return an augmented
|
||||
# image.
|
||||
tf_policies = []
|
||||
for policy in self.policies:
|
||||
tf_policy = []
|
||||
# Link string name to the correct python function and make sure the
|
||||
# correct argument is passed into that function.
|
||||
for policy_info in policy:
|
||||
policy_info = list(policy_info) + [
|
||||
replace_value, self.cutout_const, self.translate_const
|
||||
]
|
||||
tf_policy.append(_parse_policy_info(*policy_info))
|
||||
# Now build the tf policy that will apply the augmentation procedue
|
||||
# on image.
|
||||
def make_final_policy(tf_policy_):
|
||||
|
||||
def final_policy(image_):
|
||||
for func, prob, args in tf_policy_:
|
||||
image_ = _apply_func_with_prob(func, image_, args, prob)
|
||||
return image_
|
||||
|
||||
return final_policy
|
||||
|
||||
tf_policies.append(make_final_policy(tf_policy))
|
||||
|
||||
image = select_and_apply_random_policy(tf_policies, image)
|
||||
image = tf.cast(image, dtype=input_image_type)
|
||||
return image
|
||||
|
||||
@staticmethod
|
||||
def policy_v0():
|
||||
"""Autoaugment policy that was used in AutoAugment Paper.
|
||||
|
||||
Each tuple is an augmentation operation of the form
|
||||
(operation, probability, magnitude). Each element in policy is a
|
||||
sub-policy that will be applied sequentially on the image.
|
||||
|
||||
Returns:
|
||||
the policy.
|
||||
"""
|
||||
|
||||
# TODO(dankondratyuk): tensorflow_addons defines custom ops, which
|
||||
# for some reason are not included when building/linking
|
||||
# This results in the error, "Op type not registered
|
||||
# 'Addons>ImageProjectiveTransformV2' in binary" when running on borg TPUs
|
||||
policy = [
|
||||
[('Equalize', 0.8, 1), ('ShearY', 0.8, 4)],
|
||||
[('Color', 0.4, 9), ('Equalize', 0.6, 3)],
|
||||
[('Color', 0.4, 1), ('Rotate', 0.6, 8)],
|
||||
[('Solarize', 0.8, 3), ('Equalize', 0.4, 7)],
|
||||
[('Solarize', 0.4, 2), ('Solarize', 0.6, 2)],
|
||||
[('Color', 0.2, 0), ('Equalize', 0.8, 8)],
|
||||
[('Equalize', 0.4, 8), ('SolarizeAdd', 0.8, 3)],
|
||||
[('ShearX', 0.2, 9), ('Rotate', 0.6, 8)],
|
||||
[('Color', 0.6, 1), ('Equalize', 1.0, 2)],
|
||||
[('Invert', 0.4, 9), ('Rotate', 0.6, 0)],
|
||||
[('Equalize', 1.0, 9), ('ShearY', 0.6, 3)],
|
||||
[('Color', 0.4, 7), ('Equalize', 0.6, 0)],
|
||||
[('Posterize', 0.4, 6), ('AutoContrast', 0.4, 7)],
|
||||
[('Solarize', 0.6, 8), ('Color', 0.6, 9)],
|
||||
[('Solarize', 0.2, 4), ('Rotate', 0.8, 9)],
|
||||
[('Rotate', 1.0, 7), ('TranslateY', 0.8, 9)],
|
||||
[('ShearX', 0.0, 0), ('Solarize', 0.8, 4)],
|
||||
[('ShearY', 0.8, 0), ('Color', 0.6, 4)],
|
||||
[('Color', 1.0, 0), ('Rotate', 0.6, 2)],
|
||||
[('Equalize', 0.8, 4), ('Equalize', 0.0, 8)],
|
||||
[('Equalize', 1.0, 4), ('AutoContrast', 0.6, 2)],
|
||||
[('ShearY', 0.4, 7), ('SolarizeAdd', 0.6, 7)],
|
||||
[('Posterize', 0.8, 2), ('Solarize', 0.6, 10)],
|
||||
[('Solarize', 0.6, 8), ('Equalize', 0.6, 1)],
|
||||
[('Color', 0.8, 6), ('Rotate', 0.4, 5)],
|
||||
]
|
||||
return policy
|
||||
|
||||
@staticmethod
|
||||
def policy_simple():
|
||||
"""Same as `policy_v0`, except with custom ops removed."""
|
||||
|
||||
policy = [
|
||||
[('Color', 0.4, 9), ('Equalize', 0.6, 3)],
|
||||
[('Solarize', 0.8, 3), ('Equalize', 0.4, 7)],
|
||||
[('Solarize', 0.4, 2), ('Solarize', 0.6, 2)],
|
||||
[('Color', 0.2, 0), ('Equalize', 0.8, 8)],
|
||||
[('Equalize', 0.4, 8), ('SolarizeAdd', 0.8, 3)],
|
||||
[('Color', 0.6, 1), ('Equalize', 1.0, 2)],
|
||||
[('Color', 0.4, 7), ('Equalize', 0.6, 0)],
|
||||
[('Posterize', 0.4, 6), ('AutoContrast', 0.4, 7)],
|
||||
[('Solarize', 0.6, 8), ('Color', 0.6, 9)],
|
||||
[('Equalize', 0.8, 4), ('Equalize', 0.0, 8)],
|
||||
[('Equalize', 1.0, 4), ('AutoContrast', 0.6, 2)],
|
||||
[('Posterize', 0.8, 2), ('Solarize', 0.6, 10)],
|
||||
[('Solarize', 0.6, 8), ('Equalize', 0.6, 1)],
|
||||
]
|
||||
return policy
|
||||
|
||||
@staticmethod
|
||||
def policy_test():
|
||||
"""Autoaugment test policy for debugging."""
|
||||
policy = [
|
||||
[('TranslateX', 1.0, 4), ('Equalize', 1.0, 10)],
|
||||
]
|
||||
return policy
|
||||
|
||||
|
||||
class RandAugment(ImageAugment):
|
||||
"""Applies the RandAugment policy to images.
|
||||
|
||||
RandAugment is from the paper https://arxiv.org/abs/1909.13719,
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
num_layers: int = 2,
|
||||
magnitude: float = 10.,
|
||||
cutout_const: float = 40.,
|
||||
translate_const: float = 100.):
|
||||
"""Applies the RandAugment policy to images.
|
||||
|
||||
Args:
|
||||
num_layers: Integer, the number of augmentation transformations to apply
|
||||
sequentially to an image. Represented as (N) in the paper. Usually best
|
||||
values will be in the range [1, 3].
|
||||
magnitude: Integer, shared magnitude across all augmentation operations.
|
||||
Represented as (M) in the paper. Usually best values are in the range
|
||||
[5, 10].
|
||||
cutout_const: multiplier for applying cutout.
|
||||
translate_const: multiplier for applying translation.
|
||||
"""
|
||||
super(RandAugment, self).__init__()
|
||||
|
||||
self.num_layers = num_layers
|
||||
self.magnitude = float(magnitude)
|
||||
self.cutout_const = float(cutout_const)
|
||||
self.translate_const = float(translate_const)
|
||||
self.available_ops = [
|
||||
'AutoContrast', 'Equalize', 'Invert', 'Rotate', 'Posterize', 'Solarize',
|
||||
'Color', 'Contrast', 'Brightness', 'Sharpness', 'ShearX', 'ShearY',
|
||||
'TranslateX', 'TranslateY', 'Cutout', 'SolarizeAdd'
|
||||
]
|
||||
|
||||
def distort(self, image: tf.Tensor) -> tf.Tensor:
|
||||
"""Applies the RandAugment policy to `image`.
|
||||
|
||||
Args:
|
||||
image: `Tensor` of shape [height, width, 3] representing an image.
|
||||
|
||||
Returns:
|
||||
The augmented version of `image`.
|
||||
"""
|
||||
input_image_type = image.dtype
|
||||
|
||||
if input_image_type != tf.uint8:
|
||||
image = tf.clip_by_value(image, 0.0, 255.0)
|
||||
image = tf.cast(image, dtype=tf.uint8)
|
||||
|
||||
replace_value = [128] * 3
|
||||
min_prob, max_prob = 0.2, 0.8
|
||||
|
||||
for _ in range(self.num_layers):
|
||||
op_to_select = tf.random.uniform(
|
||||
[], maxval=len(self.available_ops) + 1, dtype=tf.int32)
|
||||
|
||||
branch_fns = []
|
||||
for (i, op_name) in enumerate(self.available_ops):
|
||||
prob = tf.random.uniform([],
|
||||
minval=min_prob,
|
||||
maxval=max_prob,
|
||||
dtype=tf.float32)
|
||||
func, _, args = _parse_policy_info(op_name,
|
||||
prob,
|
||||
self.magnitude,
|
||||
replace_value,
|
||||
self.cutout_const,
|
||||
self.translate_const)
|
||||
branch_fns.append((
|
||||
i,
|
||||
# pylint:disable=g-long-lambda
|
||||
lambda selected_func=func, selected_args=args: selected_func(
|
||||
image, *selected_args)))
|
||||
# pylint:enable=g-long-lambda
|
||||
|
||||
image = tf.switch_case(branch_index=op_to_select,
|
||||
branch_fns=branch_fns,
|
||||
default=lambda: tf.identity(image))
|
||||
|
||||
image = tf.cast(image, dtype=input_image_type)
|
||||
return image
|
||||
|
|
@ -0,0 +1,408 @@
|
|||
# Lint as: python3
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Common modules for callbacks."""
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
from typing import Any, List, MutableMapping, Text
|
||||
import tensorflow as tf
|
||||
from tensorflow import keras
|
||||
|
||||
from utils import optimizer_factory
|
||||
import horovod.tensorflow as hvd
|
||||
import time
|
||||
|
||||
|
||||
def get_callbacks(model_checkpoint: bool = True,
|
||||
include_tensorboard: bool = True,
|
||||
time_history: bool = True,
|
||||
track_lr: bool = True,
|
||||
write_model_weights: bool = True,
|
||||
initial_step: int = 0,
|
||||
batch_size: int = 0,
|
||||
log_steps: int = 100,
|
||||
model_dir: str = None,
|
||||
save_checkpoint_freq: int = 0,
|
||||
logger = None) -> List[tf.keras.callbacks.Callback]:
|
||||
"""Get all callbacks."""
|
||||
model_dir = model_dir or ''
|
||||
callbacks = []
|
||||
if model_checkpoint and hvd.rank() == 0:
|
||||
ckpt_full_path = os.path.join(model_dir, 'model.ckpt-{epoch:04d}')
|
||||
callbacks.append(tf.keras.callbacks.ModelCheckpoint(
|
||||
ckpt_full_path, save_weights_only=True, verbose=1, save_freq=save_checkpoint_freq))
|
||||
if time_history and logger is not None and hvd.rank() == 0:
|
||||
callbacks.append(
|
||||
TimeHistory(
|
||||
batch_size,
|
||||
log_steps,
|
||||
logdir=model_dir if include_tensorboard else None,
|
||||
logger=logger))
|
||||
if include_tensorboard:
|
||||
callbacks.append(
|
||||
CustomTensorBoard(
|
||||
log_dir=model_dir,
|
||||
track_lr=track_lr,
|
||||
initial_step=initial_step,
|
||||
write_images=write_model_weights))
|
||||
return callbacks
|
||||
|
||||
|
||||
def get_scalar_from_tensor(t: tf.Tensor) -> int:
|
||||
"""Utility function to convert a Tensor to a scalar."""
|
||||
t = tf.keras.backend.get_value(t)
|
||||
if callable(t):
|
||||
return t()
|
||||
else:
|
||||
return t
|
||||
|
||||
|
||||
class CustomTensorBoard(tf.keras.callbacks.TensorBoard):
|
||||
"""A customized TensorBoard callback that tracks additional datapoints.
|
||||
|
||||
Metrics tracked:
|
||||
- Global learning rate
|
||||
|
||||
Attributes:
|
||||
log_dir: the path of the directory where to save the log files to be parsed
|
||||
by TensorBoard.
|
||||
track_lr: `bool`, whether or not to track the global learning rate.
|
||||
initial_step: the initial step, used for preemption recovery.
|
||||
**kwargs: Additional arguments for backwards compatibility. Possible key is
|
||||
`period`.
|
||||
"""
|
||||
|
||||
# TODO(b/146499062): track params, flops, log lr, l2 loss,
|
||||
# classification loss
|
||||
|
||||
def __init__(self,
|
||||
log_dir: str,
|
||||
track_lr: bool = False,
|
||||
initial_step: int = 0,
|
||||
**kwargs):
|
||||
super(CustomTensorBoard, self).__init__(log_dir=log_dir, **kwargs)
|
||||
self.step = initial_step
|
||||
self._track_lr = track_lr
|
||||
|
||||
def on_batch_begin(self,
|
||||
epoch: int,
|
||||
logs: MutableMapping[str, Any] = None) -> None:
|
||||
self.step += 1
|
||||
if logs is None:
|
||||
logs = {}
|
||||
logs.update(self._calculate_metrics())
|
||||
super(CustomTensorBoard, self).on_batch_begin(epoch, logs)
|
||||
|
||||
def on_epoch_begin(self,
|
||||
epoch: int,
|
||||
logs: MutableMapping[str, Any] = None) -> None:
|
||||
if logs is None:
|
||||
logs = {}
|
||||
metrics = self._calculate_metrics()
|
||||
logs.update(metrics)
|
||||
super(CustomTensorBoard, self).on_epoch_begin(epoch, logs)
|
||||
|
||||
def on_epoch_end(self,
|
||||
epoch: int,
|
||||
logs: MutableMapping[str, Any] = None) -> None:
|
||||
if logs is None:
|
||||
logs = {}
|
||||
metrics = self._calculate_metrics()
|
||||
logs.update(metrics)
|
||||
super(CustomTensorBoard, self).on_epoch_end(epoch, logs)
|
||||
|
||||
def _calculate_metrics(self) -> MutableMapping[str, Any]:
|
||||
logs = {}
|
||||
# TODO(b/149030439): disable LR reporting.
|
||||
if self._track_lr:
|
||||
logs['learning_rate'] = self._calculate_lr()
|
||||
return logs
|
||||
|
||||
def _calculate_lr(self) -> int:
|
||||
"""Calculates the learning rate given the current step."""
|
||||
return get_scalar_from_tensor(
|
||||
self._get_base_optimizer()._decayed_lr(var_dtype=tf.float32)) # pylint:disable=protected-access
|
||||
|
||||
def _get_base_optimizer(self) -> tf.keras.optimizers.Optimizer:
|
||||
"""Get the base optimizer used by the current model."""
|
||||
|
||||
optimizer = self.model.optimizer
|
||||
|
||||
# The optimizer might be wrapped by another class, so unwrap it
|
||||
while hasattr(optimizer, '_optimizer'):
|
||||
optimizer = optimizer._optimizer # pylint:disable=protected-access
|
||||
|
||||
return optimizer
|
||||
|
||||
class MovingAverageCallback(tf.keras.callbacks.Callback):
|
||||
"""A Callback to be used with a `MovingAverage` optimizer.
|
||||
|
||||
Applies moving average weights to the model during validation time to test
|
||||
and predict on the averaged weights rather than the current model weights.
|
||||
Once training is complete, the model weights will be overwritten with the
|
||||
averaged weights (by default).
|
||||
|
||||
Attributes:
|
||||
overwrite_weights_on_train_end: Whether to overwrite the current model
|
||||
weights with the averaged weights from the moving average optimizer.
|
||||
**kwargs: Any additional callback arguments.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
overwrite_weights_on_train_end: bool = False,
|
||||
**kwargs):
|
||||
super(MovingAverageCallback, self).__init__(**kwargs)
|
||||
self.overwrite_weights_on_train_end = overwrite_weights_on_train_end
|
||||
|
||||
def set_model(self, model: tf.keras.Model):
|
||||
super(MovingAverageCallback, self).set_model(model)
|
||||
assert isinstance(self.model.optimizer,
|
||||
optimizer_factory.MovingAverage)
|
||||
self.model.optimizer.shadow_copy(self.model)
|
||||
|
||||
def on_test_begin(self, logs: MutableMapping[Text, Any] = None):
|
||||
self.model.optimizer.swap_weights()
|
||||
|
||||
def on_test_end(self, logs: MutableMapping[Text, Any] = None):
|
||||
self.model.optimizer.swap_weights()
|
||||
|
||||
def on_train_end(self, logs: MutableMapping[Text, Any] = None):
|
||||
if self.overwrite_weights_on_train_end:
|
||||
self.model.optimizer.assign_average_vars(self.model.variables)
|
||||
|
||||
|
||||
class AverageModelCheckpoint(tf.keras.callbacks.ModelCheckpoint):
|
||||
"""Saves and, optionally, assigns the averaged weights.
|
||||
|
||||
Taken from tfa.callbacks.AverageModelCheckpoint.
|
||||
|
||||
Attributes:
|
||||
update_weights: If True, assign the moving average weights
|
||||
to the model, and save them. If False, keep the old
|
||||
non-averaged weights, but the saved model uses the
|
||||
average weights.
|
||||
See `tf.keras.callbacks.ModelCheckpoint` for the other args.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
update_weights: bool,
|
||||
filepath: str,
|
||||
monitor: str = 'val_loss',
|
||||
verbose: int = 0,
|
||||
save_best_only: bool = False,
|
||||
save_weights_only: bool = False,
|
||||
mode: str = 'auto',
|
||||
save_freq: str = 'epoch',
|
||||
**kwargs):
|
||||
self.update_weights = update_weights
|
||||
super().__init__(
|
||||
filepath,
|
||||
monitor,
|
||||
verbose,
|
||||
save_best_only,
|
||||
save_weights_only,
|
||||
mode,
|
||||
save_freq,
|
||||
**kwargs)
|
||||
|
||||
def set_model(self, model):
|
||||
if not isinstance(model.optimizer, optimizer_factory.MovingAverage):
|
||||
raise TypeError(
|
||||
'AverageModelCheckpoint is only used when training'
|
||||
'with MovingAverage')
|
||||
return super().set_model(model)
|
||||
|
||||
def _save_model(self, epoch, logs):
|
||||
assert isinstance(self.model.optimizer, optimizer_factory.MovingAverage)
|
||||
|
||||
if self.update_weights:
|
||||
self.model.optimizer.assign_average_vars(self.model.variables)
|
||||
return super()._save_model(epoch, logs)
|
||||
else:
|
||||
# Note: `model.get_weights()` gives us the weights (non-ref)
|
||||
# whereas `model.variables` returns references to the variables.
|
||||
non_avg_weights = self.model.get_weights()
|
||||
self.model.optimizer.assign_average_vars(self.model.variables)
|
||||
# result is currently None, since `super._save_model` doesn't
|
||||
# return anything, but this may change in the future.
|
||||
result = super()._save_model(epoch, logs)
|
||||
self.model.set_weights(non_avg_weights)
|
||||
return result
|
||||
|
||||
|
||||
|
||||
class BatchTimestamp(object):
|
||||
"""A structure to store batch time stamp."""
|
||||
|
||||
def __init__(self, batch_index, timestamp):
|
||||
self.batch_index = batch_index
|
||||
self.timestamp = timestamp
|
||||
|
||||
def __repr__(self):
|
||||
return "'BatchTimestamp<batch_index: {}, timestamp: {}>'".format(
|
||||
self.batch_index, self.timestamp)
|
||||
|
||||
|
||||
|
||||
class TimeHistory(tf.keras.callbacks.Callback):
|
||||
"""Callback for Keras models."""
|
||||
|
||||
def __init__(self, batch_size, log_steps, logger, logdir=None):
|
||||
"""Callback for logging performance.
|
||||
|
||||
Args:
|
||||
batch_size: Total batch size.
|
||||
log_steps: Interval of steps between logging of batch level stats.
|
||||
logdir: Optional directory to write TensorBoard summaries.
|
||||
"""
|
||||
# TODO(wcromar): remove this parameter and rely on `logs` parameter of
|
||||
# on_train_batch_end()
|
||||
self.batch_size = batch_size
|
||||
super(TimeHistory, self).__init__()
|
||||
self.log_steps = log_steps
|
||||
self.last_log_step = 0
|
||||
self.steps_before_epoch = 0
|
||||
self.steps_in_epoch = 0
|
||||
self.start_time = None
|
||||
self.logger = logger
|
||||
self.step_per_epoch = 0
|
||||
|
||||
if logdir:
|
||||
self.summary_writer = tf.summary.create_file_writer(logdir)
|
||||
else:
|
||||
self.summary_writer = None
|
||||
|
||||
# Logs start of step 1 then end of each step based on log_steps interval.
|
||||
self.timestamp_log = []
|
||||
|
||||
# Records the time each epoch takes to run from start to finish of epoch.
|
||||
self.epoch_runtime_log = []
|
||||
self.throughput = []
|
||||
|
||||
@property
|
||||
def global_steps(self):
|
||||
"""The current 1-indexed global step."""
|
||||
return self.steps_before_epoch + self.steps_in_epoch
|
||||
|
||||
@property
|
||||
def average_steps_per_second(self):
|
||||
"""The average training steps per second across all epochs."""
|
||||
return (self.global_steps - self.step_per_epoch) / sum(self.epoch_runtime_log[1:])
|
||||
|
||||
@property
|
||||
def average_examples_per_second(self):
|
||||
"""The average number of training examples per second across all epochs."""
|
||||
# return self.average_steps_per_second * self.batch_size
|
||||
ind = int(0.1*len(self.throughput))
|
||||
return sum(self.throughput[ind:])/(len(self.throughput[ind:])+1)
|
||||
|
||||
def on_train_end(self, logs=None):
|
||||
self.train_finish_time = time.time()
|
||||
|
||||
if self.summary_writer:
|
||||
self.summary_writer.flush()
|
||||
|
||||
def on_epoch_begin(self, epoch, logs=None):
|
||||
self.epoch_start = time.time()
|
||||
|
||||
def on_batch_begin(self, batch, logs=None):
|
||||
if not self.start_time:
|
||||
self.start_time = time.time()
|
||||
|
||||
# Record the timestamp of the first global step
|
||||
if not self.timestamp_log:
|
||||
self.timestamp_log.append(BatchTimestamp(self.global_steps,
|
||||
self.start_time))
|
||||
|
||||
def on_batch_end(self, batch, logs=None):
|
||||
"""Records elapse time of the batch and calculates examples per second."""
|
||||
self.steps_in_epoch = batch + 1
|
||||
steps_since_last_log = self.global_steps - self.last_log_step
|
||||
if steps_since_last_log >= self.log_steps:
|
||||
now = time.time()
|
||||
elapsed_time = now - self.start_time
|
||||
steps_per_second = steps_since_last_log / elapsed_time
|
||||
examples_per_second = steps_per_second * self.batch_size
|
||||
|
||||
self.timestamp_log.append(BatchTimestamp(self.global_steps, now))
|
||||
elapsed_time_str='{:.2f} seconds'.format(elapsed_time)
|
||||
self.logger.log(step='PARAMETER', data={'TimeHistory': elapsed_time_str, 'examples/second': examples_per_second, 'steps': (self.last_log_step, self.global_steps)})
|
||||
|
||||
if self.summary_writer:
|
||||
with self.summary_writer.as_default():
|
||||
tf.summary.scalar('global_step/sec', steps_per_second,
|
||||
self.global_steps)
|
||||
tf.summary.scalar('examples/sec', examples_per_second,
|
||||
self.global_steps)
|
||||
|
||||
self.last_log_step = self.global_steps
|
||||
self.start_time = None
|
||||
self.throughput.append(examples_per_second)
|
||||
|
||||
def on_epoch_end(self, epoch, logs=None):
|
||||
if epoch == 0:
|
||||
self.step_per_epoch = self.steps_in_epoch
|
||||
epoch_run_time = time.time() - self.epoch_start
|
||||
self.epoch_runtime_log.append(epoch_run_time)
|
||||
|
||||
self.steps_before_epoch += self.steps_in_epoch
|
||||
self.steps_in_epoch = 0
|
||||
|
||||
|
||||
class EvalTimeHistory(tf.keras.callbacks.Callback):
|
||||
"""Callback for Keras models."""
|
||||
|
||||
def __init__(self, batch_size, logger, logdir=None):
|
||||
"""Callback for logging performance.
|
||||
|
||||
Args:
|
||||
batch_size: Total batch size.
|
||||
log_steps: Interval of steps between logging of batch level stats.
|
||||
logdir: Optional directory to write TensorBoard summaries.
|
||||
"""
|
||||
# TODO(wcromar): remove this parameter and rely on `logs` parameter of
|
||||
# on_train_batch_end()
|
||||
self.batch_size = batch_size
|
||||
self.global_steps = 0
|
||||
self.batch_time = []
|
||||
self.eval_time = 0
|
||||
super(EvalTimeHistory, self).__init__()
|
||||
self.logger = logger
|
||||
|
||||
|
||||
@property
|
||||
def average_steps_per_second(self):
|
||||
"""The average training steps per second across all epochs."""
|
||||
return (self.global_steps - 1) / self.eval_time
|
||||
|
||||
@property
|
||||
def average_examples_per_second(self):
|
||||
"""The average number of training examples per second across all epochs."""
|
||||
return self.average_steps_per_second * self.batch_size
|
||||
|
||||
def on_test_batch_end(self, batch, logs=None):
|
||||
self.global_steps += 1
|
||||
self.batch_time.append(time.time() - self.test_begin)
|
||||
|
||||
def on_test_batch_begin(self, epoch, logs=None):
|
||||
self.test_begin = time.time()
|
||||
|
||||
def on_test_end(self, epoch, logs=None):
|
||||
self.eval_time = sum(self.batch_time) - self.batch_time[0]
|
||||
|
|
@ -0,0 +1,371 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import yaml
|
||||
|
||||
|
||||
def _add_bool_argument(parser, name=None, default=False, required=False, help=None):
|
||||
|
||||
if not isinstance(default, bool):
|
||||
raise ValueError()
|
||||
|
||||
feature_parser = parser.add_mutually_exclusive_group(required=required)
|
||||
|
||||
feature_parser.add_argument('--' + name, dest=name, action='store_true', help=help, default=default)
|
||||
feature_parser.add_argument('--no' + name, dest=name, action='store_false')
|
||||
feature_parser.set_defaults(name=default)
|
||||
|
||||
|
||||
def parse_cmdline():
|
||||
|
||||
p = argparse.ArgumentParser(description="JoC-RN50v1.5-TF")
|
||||
|
||||
# ====== Define the common flags across models. ======
|
||||
p.add_argument(
|
||||
'--model_dir',
|
||||
type=str,
|
||||
default=None,
|
||||
help=('The directory where the model and training/evaluation summaries'
|
||||
'are stored.'))
|
||||
|
||||
p.add_argument(
|
||||
'--config_file',
|
||||
type=str,
|
||||
default=None,
|
||||
help=('A YAML file which specifies overrides. Note that this file can be '
|
||||
'used as an override template to override the default parameters '
|
||||
'specified in Python. If the same parameter is specified in both '
|
||||
'`--config_file` and `--params_override`, the one in '
|
||||
'`--params_override` will be used finally.'))
|
||||
|
||||
p.add_argument(
|
||||
'--params_override',
|
||||
type=str,
|
||||
default=None,
|
||||
help=('a YAML/JSON string or a YAML file which specifies additional '
|
||||
'overrides over the default parameters and those specified in '
|
||||
'`--config_file`. Note that this is supposed to be used only to '
|
||||
'override the model parameters, but not the parameters like TPU '
|
||||
'specific flags. One canonical use case of `--config_file` and '
|
||||
'`--params_override` is users first define a template config file '
|
||||
'using `--config_file`, then use `--params_override` to adjust the '
|
||||
'minimal set of tuning parameters, for example setting up different'
|
||||
' `train_batch_size`. '
|
||||
'The final override order of parameters: default_model_params --> '
|
||||
'params from config_file --> params in params_override.'
|
||||
'See also the help message of `--config_file`.'))
|
||||
|
||||
p.add_argument(
|
||||
'--save_checkpoint_freq',
|
||||
type=int,
|
||||
default=1,
|
||||
help='Number of epochs to save checkpoint.')
|
||||
|
||||
p.add_argument(
|
||||
'--data_dir',
|
||||
type=str,
|
||||
default='.',
|
||||
required=True,
|
||||
help='The location of the input data. Files should be named `train-*` and `validation-*`.')
|
||||
|
||||
p.add_argument(
|
||||
'--mode',
|
||||
type=str,
|
||||
default='train_and_eval',
|
||||
required=False,
|
||||
help='Mode to run: `train`, `eval`, `train_and_eval` or `export`.')
|
||||
|
||||
p.add_argument(
|
||||
'--arch',
|
||||
type=str,
|
||||
default='efficientnet-b0',
|
||||
required=False,
|
||||
help='The type of the model, e.g. EfficientNet, etc.')
|
||||
|
||||
p.add_argument(
|
||||
'--dataset',
|
||||
type=str,
|
||||
default='ImageNet',
|
||||
required=False,
|
||||
help='The name of the dataset, e.g. ImageNet, etc.')
|
||||
|
||||
p.add_argument(
|
||||
'--log_steps',
|
||||
type=int,
|
||||
default=100,
|
||||
help='The interval of steps between logging of batch level stats.')
|
||||
|
||||
p.add_argument(
|
||||
'--time_history',
|
||||
action='store_true',
|
||||
default=True,
|
||||
help='Logging the time for training steps.')
|
||||
|
||||
p.add_argument(
|
||||
'--use_xla',
|
||||
action='store_true',
|
||||
default=False,
|
||||
help='Set to True to enable XLA')
|
||||
|
||||
p.add_argument(
|
||||
'--use_amp',
|
||||
action='store_true',
|
||||
default=False,
|
||||
help='Set to True to enable AMP')
|
||||
|
||||
p.add_argument(
|
||||
'--intraop_threads',
|
||||
type=str,
|
||||
default='',
|
||||
help='intra thread should match the number of CPU cores')
|
||||
|
||||
p.add_argument(
|
||||
'--interop_threads',
|
||||
type=str,
|
||||
default='',
|
||||
help='inter thread should match the number of CPU sockets')
|
||||
|
||||
p.add_argument(
|
||||
'--export_dir', required=False, default=None, type=str, help="Directory in which to write exported SavedModel."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--results_dir',
|
||||
type=str,
|
||||
required=False,
|
||||
default='.',
|
||||
help="Directory in which to write training logs, summaries and checkpoints."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--inference_checkpoint',
|
||||
type=str,
|
||||
required=False,
|
||||
default=None,
|
||||
help="Path to checkpoint to do inference on."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--to_predict',
|
||||
type=str,
|
||||
required=False,
|
||||
default=None,
|
||||
help="Path to image to do inference on."
|
||||
)
|
||||
|
||||
|
||||
p.add_argument(
|
||||
'--log_filename',
|
||||
type=str,
|
||||
required=False,
|
||||
default='log.json',
|
||||
help="Name of the JSON file to which write the training log"
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--display_every',
|
||||
default=10,
|
||||
type=int,
|
||||
required=False,
|
||||
help="How often (in batches) to print out running information."
|
||||
)
|
||||
|
||||
#model_params:
|
||||
p.add_argument(
|
||||
'--num_classes', type=int, default=1000, required=False, help="Number of classes to train on.")
|
||||
|
||||
p.add_argument(
|
||||
'--batch_norm', type=str, default='default', required=False, help="Type of Batch norm used.")
|
||||
|
||||
p.add_argument(
|
||||
'--activation', type=str, default='swish', required=False, help="Type of activation to be used.")
|
||||
|
||||
#optimizer:
|
||||
p.add_argument(
|
||||
'--optimizer', type=str, default='rmsprop', required=False, help="Optimizer to be used.")
|
||||
|
||||
p.add_argument(
|
||||
'--momentum', type=float, default=0.9, required=False, help="The value of Momentum.")
|
||||
|
||||
p.add_argument(
|
||||
'--epsilon', type=float, default=0.001, required=False, help="The value of Epsilon for optimizer.")
|
||||
|
||||
p.add_argument(
|
||||
'--decay', type=float, default=0.9, required=False, help="The value of decay.")
|
||||
|
||||
p.add_argument(
|
||||
'--moving_average_decay', type=float, default=0.0, required=False, help="The value of moving average.")
|
||||
|
||||
p.add_argument(
|
||||
'--lookahead', action='store_true', default=False, required=False, help="Lookahead.")
|
||||
|
||||
p.add_argument(
|
||||
'--nesterov', action='store_true', default=False, required=False, help="nesterov bool.")
|
||||
|
||||
p.add_argument(
|
||||
'--beta_1', type=float, default=0.0, required=False, help="beta1 for Adam/AdamW.")
|
||||
|
||||
p.add_argument(
|
||||
'--beta_2', type=float, default=0.0, required=False, help="beta2 for Adam/AdamW..")
|
||||
|
||||
#loss:
|
||||
p.add_argument(
|
||||
'--label_smoothing', type=float, default=0.1, required=False, help="The value of label smoothing.")
|
||||
p.add_argument(
|
||||
'--mixup_alpha', type=float, default=0.0, required=False, help="Mix up alpha")
|
||||
|
||||
# Training specific params
|
||||
p.add_argument(
|
||||
'--max_epochs',
|
||||
default=300,
|
||||
type=int,
|
||||
required=False,
|
||||
help="Number of steps of training."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--num_epochs_between_eval',
|
||||
type=int,
|
||||
default=1,
|
||||
required=False,
|
||||
help="Eval after how many steps of training.")
|
||||
|
||||
p.add_argument(
|
||||
'--steps_per_epoch',
|
||||
default=None,
|
||||
type=int,
|
||||
required=False,
|
||||
help="Number of steps of training."
|
||||
)
|
||||
# LR Params
|
||||
p.add_argument(
|
||||
'--warmup_epochs',
|
||||
default=5,
|
||||
type=int,
|
||||
required=False,
|
||||
help="Number of steps considered as warmup and not taken into account for performance measurements."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--lr_init', default=0.008, type=float, required=False, help="Initial value for the learning rate."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--lr_decay', type=str, default='exponential', required=False, help="Type of LR Decay.")
|
||||
|
||||
p.add_argument('--lr_decay_rate', default=0.97, type=float, required=False, help="LR Decay rate.")
|
||||
|
||||
p.add_argument('--lr_decay_epochs', default=2.4, type=float, required=False, help="LR Decay epoch.")
|
||||
|
||||
p.add_argument(
|
||||
'--lr_warmup_epochs',
|
||||
default=5,
|
||||
type=int,
|
||||
required=False,
|
||||
help="Number of warmup epochs for learning rate schedule."
|
||||
)
|
||||
|
||||
p.add_argument('--weight_decay', default=5e-6, type=float, required=False, help="Weight Decay scale factor.")
|
||||
|
||||
p.add_argument(
|
||||
'--weight_init',
|
||||
default='fan_out',
|
||||
choices=['fan_in', 'fan_out'],
|
||||
type=str,
|
||||
required=False,
|
||||
help="Model weight initialization method."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--train_num_examples', type=int, default=1281167, required=False, help="Training number of examples.")
|
||||
|
||||
p.add_argument(
|
||||
'--train_batch_size', type=int, default=32, required=False, help="Training batch size per GPU.")
|
||||
|
||||
p.add_argument(
|
||||
'--augmenter_name', type=str, default='autoaugment', required=False, help="Type of Augmentation during preprocessing only during training.")
|
||||
|
||||
#Rand-augment params
|
||||
p.add_argument(
|
||||
'--num_layers', type=int, default=None, required=False, help="Rand Augmentation parameter.")
|
||||
p.add_argument(
|
||||
'--magnitude', type=float, default=None, required=False, help="Rand Augmentation parameter.")
|
||||
p.add_argument(
|
||||
'--cutout_const', type=float, default=None, required=False, help="Rand/Auto Augmentation parameter.")
|
||||
p.add_argument(
|
||||
'--translate_const', type=float, default=None, required=False, help="Rand/Auto Augmentation parameter.")
|
||||
#Auto-augment params
|
||||
p.add_argument(
|
||||
'--autoaugmentation_name', type=str, default=None, required=False, help="Auto-Augmentation parameter.")
|
||||
#evaluation:
|
||||
|
||||
# Tensor format used for the computation.
|
||||
p.add_argument(
|
||||
'--data_format', choices=['NHWC', 'NCHW'], type=str, default='NCHW', required=False, help=argparse.SUPPRESS
|
||||
)
|
||||
|
||||
# validation_dataset:
|
||||
p.add_argument(
|
||||
'--eval_num_examples', type=int, default=50000, required=False, help="Evaluation number of examples")
|
||||
p.add_argument(
|
||||
'--eval_batch_size', type=int, default=32, required=False, help="Evaluation batch size per GPU.")
|
||||
p.add_argument(
|
||||
'--predict_batch_size', type=int, default=32, required=False, help="Predict batch size per GPU.")
|
||||
p.add_argument(
|
||||
'--skip_eval', action='store_true', default=False, required=False, help="Skip eval during training.")
|
||||
|
||||
p.add_argument(
|
||||
'--resume_checkpoint', action='store_true', default=False, required=False, help="Resume from a checkpoint in the model_dir.")
|
||||
|
||||
p.add_argument('--use_dali', action='store_true', default=False,
|
||||
help='Use dali for data loading and preprocessing of train dataset.')
|
||||
|
||||
p.add_argument('--use_dali_eval', action='store_true', default=False,
|
||||
help='Use dali for data loading and preprocessing of eval dataset.')
|
||||
|
||||
p.add_argument(
|
||||
'--index_file', type=str, default='', required=False,
|
||||
help="Path to index file required for dali.")
|
||||
|
||||
p.add_argument('--benchmark', action='store_true', default=False, required=False, help="Benchmarking or not")
|
||||
# Callbacks options
|
||||
p.add_argument(
|
||||
'--enable_checkpoint_and_export', action='store_true', default=True, required=False, help="Evaluation number of examples")
|
||||
p.add_argument(
|
||||
'--enable_tensorboard', action='store_true', default=False, required=False, help="Enable Tensorboard logging.")
|
||||
p.add_argument(
|
||||
'--write_model_weights', action='store_true', default=False, required=False, help="whether to write model weights to visualize as image in TensorBoard..")
|
||||
|
||||
p.add_argument('--seed', type=int, default=None, required=False, help="Random seed.")
|
||||
|
||||
p.add_argument('--dtype', type=str, default='float32', required=False, help="Only permitted `float32`,`bfloat16`,`float16`,`fp32`,`bf16`")
|
||||
|
||||
p.add_argument('--run_eagerly', action='store_true', default=False, required=False, help="Random seed.")
|
||||
|
||||
|
||||
|
||||
FLAGS, unknown_args = p.parse_known_args()
|
||||
|
||||
if len(unknown_args) > 0:
|
||||
|
||||
for bad_arg in unknown_args:
|
||||
print("ERROR: Unknown command line arg: %s" % bad_arg)
|
||||
|
||||
raise ValueError("Invalid command line arg(s)")
|
||||
|
||||
return FLAGS
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
#!/bin/bash
|
||||
|
||||
SRC_DIR=${1}
|
||||
DST_DIR=${2}
|
||||
|
||||
echo "Creating training file indexes"
|
||||
mkdir -p ${DST_DIR}
|
||||
|
||||
for file in ${SRC_DIR}/train-*; do
|
||||
BASENAME=$(basename $file)
|
||||
DST_NAME=$DST_DIR/$BASENAME
|
||||
|
||||
echo "Creating index $DST_NAME for $file"
|
||||
tfrecord2idx $file $DST_NAME
|
||||
done
|
||||
|
||||
echo "Creating validation file indexes"
|
||||
for file in ${SRC_DIR}/validation-*; do
|
||||
BASENAME=$(basename $file)
|
||||
DST_NAME=$DST_DIR/$BASENAME
|
||||
|
||||
echo "Creating index $DST_NAME for $file"
|
||||
tfrecord2idx $file $DST_NAME
|
||||
done
|
||||
|
|
@ -0,0 +1,387 @@
|
|||
# Lint as: python3
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Dataset utilities for vision tasks using TFDS and tf.data.Dataset."""
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
from typing import Any, List, Optional, Tuple, Mapping, Union
|
||||
import functools
|
||||
import tensorflow as tf
|
||||
import tensorflow_datasets as tfds
|
||||
from tensorflow import keras
|
||||
|
||||
from utils import augment, preprocessing, Dali
|
||||
import horovod.tensorflow.keras as hvd
|
||||
import nvidia.dali.plugin.tf as dali_tf
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
AUGMENTERS = {
|
||||
'autoaugment': augment.AutoAugment,
|
||||
'randaugment': augment.RandAugment,
|
||||
}
|
||||
|
||||
class Dataset:
|
||||
"""An object for building datasets.
|
||||
|
||||
Allows building various pipelines fetching examples, preprocessing, etc.
|
||||
Maintains additional state information calculated from the dataset, i.e.,
|
||||
training set split, batch size, and number of steps (batches).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
data_dir,
|
||||
index_file_dir,
|
||||
split='train',
|
||||
num_classes=None,
|
||||
image_size=224,
|
||||
num_channels=3,
|
||||
batch_size=128,
|
||||
dtype='float32',
|
||||
one_hot=False,
|
||||
use_dali=False,
|
||||
augmenter=None,
|
||||
shuffle_buffer_size=10000,
|
||||
file_shuffle_buffer_size=1024,
|
||||
cache=False,
|
||||
mean_subtract=False,
|
||||
standardize=False,
|
||||
augmenter_params=None,
|
||||
mixup_alpha=0.0):
|
||||
"""Initialize the builder from the config."""
|
||||
if not os.path.exists(data_dir):
|
||||
raise FileNotFoundError('Cannot find data dir: {}'.format(data_dir))
|
||||
if one_hot and num_classes is None:
|
||||
raise FileNotFoundError('Number of classes is required for one_hot')
|
||||
self._data_dir = data_dir
|
||||
self._split = split
|
||||
self._image_size = image_size
|
||||
self._num_classes = num_classes
|
||||
self._num_channels = num_channels
|
||||
self._batch_size = batch_size
|
||||
self._dtype = dtype
|
||||
self._one_hot = one_hot
|
||||
self._augmenter_name = augmenter
|
||||
self._shuffle_buffer_size = shuffle_buffer_size
|
||||
self._file_shuffle_buffer_size = file_shuffle_buffer_size
|
||||
self._cache = cache
|
||||
self._mean_subtract = mean_subtract
|
||||
self._standardize = standardize
|
||||
self._index_file = index_file_dir
|
||||
self._use_dali = use_dali
|
||||
self.mixup_alpha = mixup_alpha
|
||||
|
||||
self._num_gpus = hvd.size()
|
||||
|
||||
if self._augmenter_name is not None:
|
||||
augmenter = AUGMENTERS.get(self._augmenter_name, None)
|
||||
params = augmenter_params or {}
|
||||
self._augmenter = augmenter(**params) if augmenter is not None else None
|
||||
else:
|
||||
self._augmenter = None
|
||||
|
||||
def mixup(self, batch_size, alpha, images, labels):
|
||||
"""Applies Mixup regularization to a batch of images and labels.
|
||||
[1] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, David Lopez-Paz
|
||||
Mixup: Beyond Empirical Risk Minimization.
|
||||
ICLR'18, https://arxiv.org/abs/1710.09412
|
||||
Arguments:
|
||||
batch_size: The input batch size for images and labels.
|
||||
alpha: Float that controls the strength of Mixup regularization.
|
||||
images: A batch of images of shape [batch_size, ...]
|
||||
labels: A batch of labels of shape [batch_size, num_classes]
|
||||
Returns:
|
||||
A tuple of (images, labels) with the same dimensions as the input with
|
||||
Mixup regularization applied.
|
||||
"""
|
||||
# Mixup of images will be performed on device later
|
||||
if alpha == 0.0:
|
||||
images_mix_weight = tf.ones([batch_size, 1, 1, 1])
|
||||
return (images, images_mix_weight), labels
|
||||
|
||||
mix_weight = tf.compat.v1.distributions.Beta(alpha, alpha).sample([batch_size, 1])
|
||||
mix_weight = tf.maximum(mix_weight, 1. - mix_weight)
|
||||
images_mix_weight = tf.reshape(mix_weight, [batch_size, 1, 1, 1])
|
||||
# Mixup on a single batch is implemented by taking a weighted sum with the
|
||||
# same batch in reverse.
|
||||
labels_mix = labels * mix_weight + labels[::-1] * (1. - mix_weight)
|
||||
return (images, images_mix_weight), labels_mix
|
||||
|
||||
|
||||
@property
|
||||
def is_training(self) -> bool:
|
||||
"""Whether this is the training set."""
|
||||
return self._split == 'train'
|
||||
|
||||
@property
|
||||
def global_batch_size(self) -> int:
|
||||
"""The batch size, multiplied by the number of replicas (if configured)."""
|
||||
return self._batch_size * self._num_gpus
|
||||
|
||||
@property
|
||||
def local_batch_size(self):
|
||||
"""The base unscaled batch size."""
|
||||
return self._batch_size
|
||||
|
||||
@property
|
||||
def dtype(self) -> tf.dtypes.DType:
|
||||
"""Converts the config's dtype string to a tf dtype.
|
||||
|
||||
Returns:
|
||||
A mapping from string representation of a dtype to the `tf.dtypes.DType`.
|
||||
|
||||
Raises:
|
||||
ValueError if the config's dtype is not supported.
|
||||
|
||||
"""
|
||||
dtype_map = {
|
||||
'float32': tf.float32,
|
||||
'bfloat16': tf.bfloat16,
|
||||
'float16': tf.float16,
|
||||
'fp32': tf.float32,
|
||||
'bf16': tf.bfloat16,
|
||||
}
|
||||
try:
|
||||
return dtype_map[self._dtype]
|
||||
except:
|
||||
raise ValueError('{} provided key. Invalid DType provided. Supported types: {}'.format(self._dtype,
|
||||
dtype_map.keys()))
|
||||
|
||||
@property
|
||||
def image_size(self) -> int:
|
||||
"""The size of each image (can be inferred from the dataset)."""
|
||||
return int(self._image_size)
|
||||
|
||||
@property
|
||||
def num_channels(self) -> int:
|
||||
"""The number of image channels (can be inferred from the dataset)."""
|
||||
return int(self._num_channels)
|
||||
|
||||
@property
|
||||
def num_classes(self) -> int:
|
||||
"""The number of classes (can be inferred from the dataset)."""
|
||||
return int(self._num_classes)
|
||||
|
||||
@property
|
||||
def num_steps(self) -> int:
|
||||
"""The number of classes (can be inferred from the dataset)."""
|
||||
return int(self._num_steps)
|
||||
|
||||
def build(self) -> tf.data.Dataset:
|
||||
"""Construct a dataset end-to-end and return it.
|
||||
|
||||
Args:
|
||||
input_context: An optional context provided by `tf.distribute` for
|
||||
cross-replica training.
|
||||
|
||||
Returns:
|
||||
A TensorFlow dataset outputting batched images and labels.
|
||||
"""
|
||||
if self._use_dali:
|
||||
print("Using dali for {train} dataloading".format(train = "training" if self.is_training else "validation"))
|
||||
tfrec_filenames = sorted(tf.io.gfile.glob(os.path.join(self._data_dir, '%s-*' % self._split)))
|
||||
tfrec_idx_filenames = sorted(tf.io.gfile.glob(os.path.join(self._index_file, '%s-*' % self._split)))
|
||||
|
||||
# # Create pipeline
|
||||
dali_pipeline = Dali.DaliPipeline(tfrec_filenames=tfrec_filenames,
|
||||
tfrec_idx_filenames=tfrec_idx_filenames,
|
||||
height=self._image_size,
|
||||
width=self._image_size,
|
||||
batch_size=self.local_batch_size,
|
||||
num_threads=1,
|
||||
device_id=hvd.local_rank(),
|
||||
shard_id=hvd.rank(),
|
||||
num_gpus=hvd.size(),
|
||||
num_classes=self.num_classes,
|
||||
deterministic=False,
|
||||
dali_cpu=False,
|
||||
training=self.is_training)
|
||||
|
||||
# Define shapes and types of the outputs
|
||||
shapes = (
|
||||
(self.local_batch_size, self._image_size, self._image_size, 3),
|
||||
(self.local_batch_size, self._num_classes))
|
||||
dtypes = (
|
||||
tf.float32,
|
||||
tf.float32)
|
||||
|
||||
# Create dataset
|
||||
dataset = dali_tf.DALIDataset(
|
||||
pipeline=dali_pipeline,
|
||||
batch_size=self.local_batch_size,
|
||||
output_shapes=shapes,
|
||||
output_dtypes=dtypes,
|
||||
device_id=hvd.local_rank())
|
||||
# if self.is_training and self._augmenter:
|
||||
# print('Augmenting with {}'.format(self._augmenter))
|
||||
# dataset.unbatch().map(self.augment_pipeline, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(self.local_batch_size)
|
||||
return dataset
|
||||
else:
|
||||
print("Using tf native pipeline for {train} dataloading".format(train = "training" if self.is_training else "validation"))
|
||||
dataset = self.load_records()
|
||||
dataset = self.pipeline(dataset)
|
||||
|
||||
return dataset
|
||||
|
||||
# def augment_pipeline(self, image, label) -> Tuple[tf.Tensor, tf.Tensor]:
|
||||
# image = self._augmenter.distort(image)
|
||||
# return image, label
|
||||
|
||||
|
||||
def load_records(self) -> tf.data.Dataset:
|
||||
"""Return a dataset loading files with TFRecords."""
|
||||
if self._data_dir is None:
|
||||
raise ValueError('Dataset must specify a path for the data files.')
|
||||
|
||||
file_pattern = os.path.join(self._data_dir,
|
||||
'{}*'.format(self._split))
|
||||
dataset = tf.data.Dataset.list_files(file_pattern, shuffle=False)
|
||||
return dataset
|
||||
|
||||
def pipeline(self, dataset: tf.data.Dataset) -> tf.data.Dataset:
|
||||
"""Build a pipeline fetching, shuffling, and preprocessing the dataset.
|
||||
|
||||
Args:
|
||||
dataset: A `tf.data.Dataset` that loads raw files.
|
||||
|
||||
Returns:
|
||||
A TensorFlow dataset outputting batched images and labels.
|
||||
"""
|
||||
if self._num_gpus > 1:
|
||||
dataset = dataset.shard(self._num_gpus, hvd.rank())
|
||||
|
||||
if self.is_training:
|
||||
# Shuffle the input files.
|
||||
dataset.shuffle(buffer_size=self._file_shuffle_buffer_size)
|
||||
|
||||
if self.is_training and not self._cache:
|
||||
dataset = dataset.repeat()
|
||||
|
||||
# Read the data from disk in parallel
|
||||
dataset = dataset.interleave(
|
||||
tf.data.TFRecordDataset,
|
||||
cycle_length=10,
|
||||
block_length=1,
|
||||
num_parallel_calls=tf.data.experimental.AUTOTUNE)
|
||||
|
||||
if self._cache:
|
||||
dataset = dataset.cache()
|
||||
|
||||
if self.is_training:
|
||||
dataset = dataset.shuffle(self._shuffle_buffer_size)
|
||||
dataset = dataset.repeat()
|
||||
|
||||
# Parse, pre-process, and batch the data in parallel
|
||||
preprocess = self.parse_record
|
||||
dataset = dataset.map(preprocess,
|
||||
num_parallel_calls=tf.data.experimental.AUTOTUNE)
|
||||
|
||||
if self._num_gpus > 1:
|
||||
# The batch size of the dataset will be multiplied by the number of
|
||||
# replicas automatically when strategy.distribute_datasets_from_function
|
||||
# is called, so we use local batch size here.
|
||||
dataset = dataset.batch(self.local_batch_size,
|
||||
drop_remainder=self.is_training)
|
||||
else:
|
||||
dataset = dataset.batch(self.global_batch_size,
|
||||
drop_remainder=self.is_training)
|
||||
|
||||
# Apply Mixup
|
||||
mixup_alpha = self.mixup_alpha if self.is_training else 0.0
|
||||
dataset = dataset.map(
|
||||
functools.partial(self.mixup, self.local_batch_size, mixup_alpha),
|
||||
num_parallel_calls=64)
|
||||
|
||||
# Prefetch overlaps in-feed with training
|
||||
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
|
||||
|
||||
return dataset
|
||||
|
||||
def parse_record(self, record: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
|
||||
"""Parse an ImageNet record from a serialized string Tensor."""
|
||||
keys_to_features = {
|
||||
'image/encoded':
|
||||
tf.io.FixedLenFeature((), tf.string, ''),
|
||||
'image/format':
|
||||
tf.io.FixedLenFeature((), tf.string, 'jpeg'),
|
||||
'image/class/label':
|
||||
tf.io.FixedLenFeature([], tf.int64, -1),
|
||||
'image/class/text':
|
||||
tf.io.FixedLenFeature([], tf.string, ''),
|
||||
'image/object/bbox/xmin':
|
||||
tf.io.VarLenFeature(dtype=tf.float32),
|
||||
'image/object/bbox/ymin':
|
||||
tf.io.VarLenFeature(dtype=tf.float32),
|
||||
'image/object/bbox/xmax':
|
||||
tf.io.VarLenFeature(dtype=tf.float32),
|
||||
'image/object/bbox/ymax':
|
||||
tf.io.VarLenFeature(dtype=tf.float32),
|
||||
'image/object/class/label':
|
||||
tf.io.VarLenFeature(dtype=tf.int64),
|
||||
}
|
||||
|
||||
parsed = tf.io.parse_single_example(record, keys_to_features)
|
||||
|
||||
label = tf.reshape(parsed['image/class/label'], shape=[1])
|
||||
label = tf.cast(label, dtype=tf.int32)
|
||||
|
||||
# Subtract one so that labels are in [0, 1000)
|
||||
label -= 1
|
||||
|
||||
image_bytes = tf.reshape(parsed['image/encoded'], shape=[])
|
||||
image, label = self.preprocess(image_bytes, label)
|
||||
|
||||
return image, label
|
||||
|
||||
def preprocess(self, image: tf.Tensor, label: tf.Tensor
|
||||
) -> Tuple[tf.Tensor, tf.Tensor]:
|
||||
"""Apply image preprocessing and augmentation to the image and label."""
|
||||
if self.is_training:
|
||||
image = preprocessing.preprocess_for_train(
|
||||
image,
|
||||
image_size=self._image_size,
|
||||
mean_subtract=self._mean_subtract,
|
||||
standardize=self._standardize,
|
||||
dtype=self.dtype,
|
||||
augmenter=self._augmenter)
|
||||
else:
|
||||
image = preprocessing.preprocess_for_eval(
|
||||
image,
|
||||
image_size=self._image_size,
|
||||
num_channels=self._num_channels,
|
||||
mean_subtract=self._mean_subtract,
|
||||
standardize=self._standardize,
|
||||
dtype=self.dtype)
|
||||
|
||||
label = tf.cast(label, tf.int32)
|
||||
if self._one_hot:
|
||||
label = tf.one_hot(label, self.num_classes)
|
||||
label = tf.reshape(label, [self.num_classes])
|
||||
|
||||
return image, label
|
||||
|
||||
@classmethod
|
||||
def from_params(cls, *args, **kwargs):
|
||||
"""Construct a dataset builder from a default config and any overrides."""
|
||||
config = DatasetConfig.from_args(*args, **kwargs)
|
||||
return cls(config)
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import horovod.tensorflow as hvd
|
||||
|
||||
__all__ = [
|
||||
'is_using_hvd',
|
||||
]
|
||||
|
||||
def is_using_hvd():
|
||||
return hvd.size() > 1
|
||||
|
|
@ -0,0 +1,130 @@
|
|||
# Lint as: python3
|
||||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Learning rate utilities for vision tasks."""
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
from typing import Any, List, Mapping
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
BASE_LEARNING_RATE = 0.1
|
||||
|
||||
__all__ = [ 'WarmupDecaySchedule', 'PiecewiseConstantDecayWithWarmup' ]
|
||||
|
||||
@tf.keras.utils.register_keras_serializable(package='Custom')
|
||||
class WarmupDecaySchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
|
||||
"""A wrapper for LearningRateSchedule that includes warmup steps."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
lr_schedule: tf.keras.optimizers.schedules.LearningRateSchedule,
|
||||
warmup_steps: int,
|
||||
**kwargs):
|
||||
"""Add warmup decay to a learning rate schedule.
|
||||
|
||||
Args:
|
||||
lr_schedule: base learning rate scheduler
|
||||
warmup_steps: number of warmup steps
|
||||
|
||||
"""
|
||||
super(WarmupDecaySchedule, self).__init__()
|
||||
self._lr_schedule = lr_schedule
|
||||
self._warmup_steps = warmup_steps
|
||||
|
||||
|
||||
def __call__(self, step: int):
|
||||
lr = self._lr_schedule(step)
|
||||
if self._warmup_steps:
|
||||
step_decay = step - self._warmup_steps
|
||||
lr = self._lr_schedule(step_decay)
|
||||
initial_learning_rate = tf.convert_to_tensor(
|
||||
self._lr_schedule.initial_learning_rate, name="initial_learning_rate")
|
||||
dtype = initial_learning_rate.dtype
|
||||
global_step_recomp = tf.cast(step, dtype)
|
||||
warmup_steps = tf.cast(self._warmup_steps, dtype)
|
||||
warmup_lr = initial_learning_rate * global_step_recomp / warmup_steps
|
||||
lr = tf.cond(global_step_recomp < warmup_steps,
|
||||
lambda: warmup_lr,
|
||||
lambda: lr)
|
||||
return lr
|
||||
|
||||
def get_config(self) -> Mapping[str, Any]:
|
||||
config = self._lr_schedule.get_config()
|
||||
config.update({
|
||||
"warmup_steps": self._warmup_steps,
|
||||
})
|
||||
config.update({
|
||||
"lr_schedule": self._lr_schedule,
|
||||
})
|
||||
return config
|
||||
|
||||
|
||||
|
||||
# TODO(b/149030439) - refactor this with
|
||||
# tf.keras.optimizers.schedules.PiecewiseConstantDecay + WarmupDecaySchedule.
|
||||
class PiecewiseConstantDecayWithWarmup(
|
||||
tf.keras.optimizers.schedules.LearningRateSchedule):
|
||||
"""Piecewise constant decay with warmup schedule."""
|
||||
|
||||
def __init__(self,
|
||||
batch_size: int,
|
||||
epoch_size: int,
|
||||
warmup_epochs: int,
|
||||
boundaries: List[int],
|
||||
multipliers: List[float]):
|
||||
"""Piecewise constant decay with warmup.
|
||||
|
||||
Args:
|
||||
batch_size: The training batch size used in the experiment.
|
||||
epoch_size: The size of an epoch, or the number of examples in an epoch.
|
||||
warmup_epochs: The number of warmup epochs to apply.
|
||||
boundaries: The list of floats with strictly increasing entries.
|
||||
multipliers: The list of multipliers/learning rates to use for the
|
||||
piecewise portion. The length must be 1 less than that of boundaries.
|
||||
|
||||
"""
|
||||
super(PiecewiseConstantDecayWithWarmup, self).__init__()
|
||||
if len(boundaries) != len(multipliers) - 1:
|
||||
raise ValueError("The length of boundaries must be 1 less than the "
|
||||
"length of multipliers")
|
||||
|
||||
base_lr_batch_size = 256
|
||||
steps_per_epoch = epoch_size // batch_size
|
||||
|
||||
self._rescaled_lr = BASE_LEARNING_RATE * batch_size / base_lr_batch_size
|
||||
self._step_boundaries = [float(steps_per_epoch) * x for x in boundaries]
|
||||
self._lr_values = [self._rescaled_lr * m for m in multipliers]
|
||||
self._warmup_steps = warmup_epochs * steps_per_epoch
|
||||
|
||||
def __call__(self, step: int):
|
||||
"""Compute learning rate at given step."""
|
||||
def warmup_lr():
|
||||
return self._rescaled_lr * (
|
||||
step / tf.cast(self._warmup_steps, tf.float32))
|
||||
def piecewise_lr():
|
||||
return tf.compat.v1.train.piecewise_constant(
|
||||
tf.cast(step, tf.float32), self._step_boundaries, self._lr_values)
|
||||
return tf.cond(step < self._warmup_steps, warmup_lr, piecewise_lr)
|
||||
|
||||
def get_config(self) -> Mapping[str, Any]:
|
||||
return {
|
||||
"rescaled_lr": self._rescaled_lr,
|
||||
"step_boundaries": self._step_boundaries,
|
||||
"lr_values": self._lr_values,
|
||||
"warmup_steps": self._warmup_steps,
|
||||
}
|
||||
|
|
@ -0,0 +1,377 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Optimizer factory for vision tasks."""
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import tensorflow as tf
|
||||
import tensorflow_addons as tfa
|
||||
|
||||
from typing import Any, Dict, Text, List
|
||||
from tensorflow import keras
|
||||
# pylint: disable=protected-access
|
||||
|
||||
from utils import learning_rate
|
||||
|
||||
class MovingAverage(tf.keras.optimizers.Optimizer):
|
||||
"""Optimizer that computes a moving average of the variables.
|
||||
|
||||
Empirically it has been found that using the moving average of the trained
|
||||
parameters of a deep network is better than using its trained parameters
|
||||
directly. This optimizer allows you to compute this moving average and swap
|
||||
the variables at save time so that any code outside of the training loop
|
||||
will use by default the average values instead of the original ones.
|
||||
|
||||
Example of usage for training:
|
||||
```python
|
||||
opt = tf.keras.optimizers.SGD(learning_rate)
|
||||
opt = MovingAverage(opt)
|
||||
|
||||
opt.shadow_copy(model)
|
||||
```
|
||||
|
||||
At test time, swap the shadow variables to evaluate on the averaged weights:
|
||||
```python
|
||||
opt.swap_weights()
|
||||
# Test eval the model here
|
||||
opt.swap_weights()
|
||||
```
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
optimizer: tf.keras.optimizers.Optimizer,
|
||||
average_decay: float = 0.99,
|
||||
start_step: int = 0,
|
||||
dynamic_decay: bool = True,
|
||||
name: Text = 'moving_average',
|
||||
**kwargs):
|
||||
"""Construct a new MovingAverage optimizer.
|
||||
|
||||
Args:
|
||||
optimizer: `tf.keras.optimizers.Optimizer` that will be
|
||||
used to compute and apply gradients.
|
||||
average_decay: float. Decay to use to maintain the moving averages
|
||||
of trained variables.
|
||||
start_step: int. What step to start the moving average.
|
||||
dynamic_decay: bool. Whether to change the decay based on the number
|
||||
of optimizer updates. Decay will start at 0.1 and gradually increase
|
||||
up to `average_decay` after each optimizer update. This behavior is
|
||||
similar to `tf.train.ExponentialMovingAverage` in TF 1.x.
|
||||
name: Optional name for the operations created when applying
|
||||
gradients. Defaults to "moving_average".
|
||||
**kwargs: keyword arguments. Allowed to be {`clipnorm`,
|
||||
`clipvalue`, `lr`, `decay`}.
|
||||
"""
|
||||
super(MovingAverage, self).__init__(name, **kwargs)
|
||||
self._optimizer = optimizer
|
||||
self._average_decay = average_decay
|
||||
self._start_step = tf.constant(start_step, tf.float32)
|
||||
self._dynamic_decay = dynamic_decay
|
||||
|
||||
def shadow_copy(self, model: tf.keras.Model):
|
||||
"""Creates shadow variables for the given model weights."""
|
||||
for var in model.weights:
|
||||
self.add_slot(var, 'average', initializer='zeros')
|
||||
self._average_weights = [
|
||||
self.get_slot(var, 'average') for var in model.weights
|
||||
]
|
||||
self._model_weights = model.weights
|
||||
|
||||
@property
|
||||
def has_shadow_copy(self):
|
||||
"""Whether this optimizer has created shadow variables."""
|
||||
return self._model_weights is not None
|
||||
|
||||
def _create_slots(self, var_list):
|
||||
self._optimizer._create_slots(var_list=var_list) # pylint: disable=protected-access
|
||||
|
||||
def apply_gradients(self, grads_and_vars, name: Text = None):
|
||||
result = self._optimizer.apply_gradients(grads_and_vars, name)
|
||||
self.update_average(self._optimizer.iterations)
|
||||
return result
|
||||
|
||||
@tf.function
|
||||
def update_average(self, step: tf.Tensor):
|
||||
step = tf.cast(step, tf.float32)
|
||||
if step < self._start_step:
|
||||
decay = tf.constant(0., tf.float32)
|
||||
elif self._dynamic_decay:
|
||||
decay = step - self._start_step
|
||||
decay = tf.minimum(self._average_decay, (1. + decay) / (10. + decay))
|
||||
else:
|
||||
decay = self._average_decay
|
||||
|
||||
def _apply_moving(v_moving, v_normal):
|
||||
diff = v_moving - v_normal
|
||||
v_moving.assign_sub(tf.cast(1. - decay, v_moving.dtype) * diff)
|
||||
return v_moving
|
||||
|
||||
def _update(strategy, v_moving_and_v_normal):
|
||||
for v_moving, v_normal in v_moving_and_v_normal:
|
||||
strategy.extended.update(v_moving, _apply_moving, args=(v_normal,))
|
||||
|
||||
ctx = tf.distribute.get_replica_context()
|
||||
return ctx.merge_call(_update, args=(zip(self._average_weights,
|
||||
self._model_weights),))
|
||||
|
||||
def swap_weights(self):
|
||||
"""Swap the average and moving weights.
|
||||
|
||||
This is a convenience method to allow one to evaluate the averaged weights
|
||||
at test time. Loads the weights stored in `self._average` into the model,
|
||||
keeping a copy of the original model weights. Swapping twice will return
|
||||
the original weights.
|
||||
"""
|
||||
if tf.distribute.in_cross_replica_context():
|
||||
strategy = tf.distribute.get_strategy()
|
||||
strategy.run(self._swap_weights, args=())
|
||||
else:
|
||||
raise ValueError('Swapping weights must occur under a '
|
||||
'tf.distribute.Strategy')
|
||||
|
||||
@tf.function
|
||||
def _swap_weights(self):
|
||||
def fn_0(a, b):
|
||||
a.assign_add(b)
|
||||
return a
|
||||
def fn_1(b, a):
|
||||
b.assign(a - b)
|
||||
return b
|
||||
def fn_2(a, b):
|
||||
a.assign_sub(b)
|
||||
return a
|
||||
|
||||
def swap(strategy, a_and_b):
|
||||
"""Swap `a` and `b` and mirror to all devices."""
|
||||
for a, b in a_and_b:
|
||||
strategy.extended.update(a, fn_0, args=(b,)) # a = a + b
|
||||
strategy.extended.update(b, fn_1, args=(a,)) # b = a - b
|
||||
strategy.extended.update(a, fn_2, args=(b,)) # a = a - b
|
||||
|
||||
ctx = tf.distribute.get_replica_context()
|
||||
return ctx.merge_call(
|
||||
swap, args=(zip(self._average_weights, self._model_weights),))
|
||||
|
||||
def assign_average_vars(self, var_list: List[tf.Variable]):
|
||||
"""Assign variables in var_list with their respective averages.
|
||||
|
||||
Args:
|
||||
var_list: List of model variables to be assigned to their average.
|
||||
Returns:
|
||||
assign_op: The op corresponding to the assignment operation of
|
||||
variables to their average.
|
||||
"""
|
||||
assign_op = tf.group([
|
||||
var.assign(self.get_slot(var, 'average')) for var in var_list
|
||||
if var.trainable
|
||||
])
|
||||
return assign_op
|
||||
|
||||
def _create_hypers(self):
|
||||
self._optimizer._create_hypers() # pylint: disable=protected-access
|
||||
|
||||
def _prepare(self, var_list):
|
||||
return self._optimizer._prepare(var_list=var_list) # pylint: disable=protected-access
|
||||
|
||||
@property
|
||||
def iterations(self):
|
||||
return self._optimizer.iterations
|
||||
|
||||
@iterations.setter
|
||||
def iterations(self, variable):
|
||||
self._optimizer.iterations = variable
|
||||
|
||||
@property
|
||||
def weights(self):
|
||||
# return self._weights + self._optimizer.weights
|
||||
return self._optimizer.weights
|
||||
|
||||
@property
|
||||
def lr(self):
|
||||
return self._optimizer._get_hyper('learning_rate')
|
||||
|
||||
@lr.setter
|
||||
def lr(self, lr):
|
||||
self._optimizer._set_hyper('learning_rate', lr)
|
||||
|
||||
@property
|
||||
def learning_rate(self):
|
||||
return self._optimizer._get_hyper('learning_rate')
|
||||
|
||||
@learning_rate.setter
|
||||
def learning_rate(self, learning_rate): # pylint: disable=redefined-outer-name
|
||||
self._optimizer._set_hyper('learning_rate', learning_rate)
|
||||
|
||||
def _resource_apply_dense(self, grad, var):
|
||||
return self._optimizer._resource_apply_dense(grad, var)
|
||||
|
||||
def _resource_apply_sparse(self, grad, var, indices):
|
||||
return self._optimizer._resource_apply_sparse(grad, var, indices)
|
||||
|
||||
def _resource_apply_sparse_duplicate_indices(self, grad, var, indices):
|
||||
return self._optimizer._resource_apply_sparse_duplicate_indices(
|
||||
grad, var, indices)
|
||||
|
||||
def get_config(self):
|
||||
config = {
|
||||
'optimizer': tf.keras.optimizers.serialize(self._optimizer),
|
||||
'average_decay': self._average_decay,
|
||||
'start_step': self._start_step,
|
||||
'dynamic_decay': self._dynamic_decay,
|
||||
}
|
||||
base_config = super(MovingAverage, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, config, custom_objects=None):
|
||||
optimizer = tf.keras.optimizers.deserialize(
|
||||
config.pop('optimizer'),
|
||||
custom_objects=custom_objects,
|
||||
)
|
||||
return cls(optimizer, **config)
|
||||
|
||||
|
||||
def build_optimizer(
|
||||
optimizer_name: Text,
|
||||
base_learning_rate: tf.keras.optimizers.schedules.LearningRateSchedule,
|
||||
params: Dict[Text, Any]):
|
||||
"""Build the optimizer based on name.
|
||||
|
||||
Args:
|
||||
optimizer_name: String representation of the optimizer name. Examples:
|
||||
sgd, momentum, rmsprop.
|
||||
base_learning_rate: `tf.keras.optimizers.schedules.LearningRateSchedule`
|
||||
base learning rate.
|
||||
params: String -> Any dictionary representing the optimizer params.
|
||||
This should contain optimizer specific parameters such as
|
||||
`base_learning_rate`, `decay`, etc.
|
||||
|
||||
Returns:
|
||||
A tf.keras.Optimizer.
|
||||
|
||||
Raises:
|
||||
ValueError if the provided optimizer_name is not supported.
|
||||
|
||||
"""
|
||||
optimizer_name = optimizer_name.lower()
|
||||
|
||||
if optimizer_name == 'sgd':
|
||||
nesterov = params.get('nesterov', False)
|
||||
optimizer = tf.keras.optimizers.SGD(learning_rate=base_learning_rate,
|
||||
nesterov=nesterov)
|
||||
elif optimizer_name == 'momentum':
|
||||
nesterov = params.get('nesterov', False)
|
||||
optimizer = tf.keras.optimizers.SGD(learning_rate=base_learning_rate,
|
||||
momentum=params['momentum'],
|
||||
nesterov=nesterov)
|
||||
elif optimizer_name == 'rmsprop':
|
||||
rho = params.get('decay', None) or params.get('rho', 0.9)
|
||||
momentum = params.get('momentum', 0.9)
|
||||
epsilon = params.get('epsilon', 1e-07)
|
||||
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate,
|
||||
rho=rho,
|
||||
momentum=momentum,
|
||||
epsilon=epsilon)
|
||||
elif optimizer_name == 'adam':
|
||||
beta_1 = params.get('beta_1', 0.9)
|
||||
beta_2 = params.get('beta_2', 0.999)
|
||||
epsilon = params.get('epsilon', 1e-07)
|
||||
optimizer = tf.keras.optimizers.Adam(learning_rate=base_learning_rate,
|
||||
beta_1=beta_1,
|
||||
beta_2=beta_2,
|
||||
epsilon=epsilon)
|
||||
elif optimizer_name == 'adamw':
|
||||
weight_decay = params.get('weight_decay', 0.01)
|
||||
beta_1 = params.get('beta_1', 0.9)
|
||||
beta_2 = params.get('beta_2', 0.999)
|
||||
epsilon = params.get('epsilon', 1e-07)
|
||||
optimizer = tfa.optimizers.AdamW(weight_decay=weight_decay,
|
||||
learning_rate=base_learning_rate,
|
||||
beta_1=beta_1,
|
||||
beta_2=beta_2,
|
||||
epsilon=epsilon)
|
||||
else:
|
||||
raise ValueError('Unknown optimizer %s' % optimizer_name)
|
||||
|
||||
if params.get('lookahead', None):
|
||||
optimizer = tfa.optimizers.Lookahead(optimizer)
|
||||
|
||||
# Moving average should be applied last, as it's applied at test time
|
||||
moving_average_decay = params.get('moving_average_decay', 0.)
|
||||
if moving_average_decay is not None and moving_average_decay > 0.:
|
||||
optimizer = MovingAverage(
|
||||
optimizer,
|
||||
average_decay=moving_average_decay)
|
||||
return optimizer
|
||||
|
||||
|
||||
def build_learning_rate(params: Dict[Text, Any],
|
||||
batch_size: int = None,
|
||||
train_steps: int = None,
|
||||
max_epochs: int = None):
|
||||
"""Build the learning rate given the provided configuration."""
|
||||
decay_type = params['name']
|
||||
base_lr = params['initial_lr']
|
||||
decay_rate = params['decay_rate']
|
||||
if params['decay_epochs'] is not None:
|
||||
decay_steps = params['decay_epochs'] * train_steps
|
||||
else:
|
||||
decay_steps = 0
|
||||
if params['warmup_epochs'] is not None:
|
||||
warmup_steps = params['warmup_epochs'] * train_steps
|
||||
else:
|
||||
warmup_steps = 0
|
||||
|
||||
lr_multiplier = params['scale_by_batch_size']
|
||||
|
||||
if lr_multiplier and lr_multiplier > 0:
|
||||
# Scale the learning rate based on the batch size and a multiplier
|
||||
base_lr *= lr_multiplier * batch_size
|
||||
|
||||
if decay_type == 'exponential':
|
||||
lr = tf.keras.optimizers.schedules.ExponentialDecay(
|
||||
initial_learning_rate=base_lr,
|
||||
decay_steps=decay_steps,
|
||||
decay_rate=decay_rate,
|
||||
staircase=params['staircase'])
|
||||
elif decay_type == 'piecewise_constant_with_warmup':
|
||||
lr = learning_rate.PiecewiseConstantDecayWithWarmup(
|
||||
batch_size=batch_size,
|
||||
epoch_size=params['examples_per_epoch'],
|
||||
warmup_epochs=params['warmup_epochs'],
|
||||
boundaries=params['boundaries'],
|
||||
multipliers=params['multipliers'])
|
||||
elif decay_type == 'cosine':
|
||||
decay_steps = (max_epochs - params['warmup_epochs']) * train_steps
|
||||
lr = tf.keras.experimental.CosineDecay(
|
||||
initial_learning_rate=base_lr,
|
||||
decay_steps=decay_steps,
|
||||
alpha=0.0
|
||||
)
|
||||
elif decay_type == 'linearcosine':
|
||||
decay_steps = (max_epochs - params['warmup_epochs']) * train_steps
|
||||
lr = tf.keras.experimental.NoisyLinearCosineDecay(
|
||||
initial_learning_rate=base_lr,
|
||||
decay_steps=decay_steps,
|
||||
initial_variance=0.5,
|
||||
variance_decay=0.55,
|
||||
num_periods=0.5, alpha=0.0, beta=0.001
|
||||
)
|
||||
if warmup_steps > 0:
|
||||
if decay_type != 'piecewise_constant_with_warmup':
|
||||
lr = learning_rate.WarmupDecaySchedule(lr, warmup_steps)
|
||||
return lr
|
||||
|
|
@ -0,0 +1,404 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ==============================================================================
|
||||
"""Preprocessing functions for images."""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
# from __future__ import google_type_annotations
|
||||
from __future__ import print_function
|
||||
|
||||
import tensorflow as tf
|
||||
from typing import List, Optional, Text, Tuple
|
||||
|
||||
from utils import augment
|
||||
|
||||
|
||||
# Calculated from the ImageNet training set
|
||||
MEAN_RGB = (0.485 * 255, 0.456 * 255, 0.406 * 255)
|
||||
STDDEV_RGB = (0.229 * 255, 0.224 * 255, 0.225 * 255)
|
||||
|
||||
IMAGE_SIZE = 224
|
||||
CROP_PADDING = 32
|
||||
|
||||
|
||||
def mean_image_subtraction(
|
||||
image_bytes: tf.Tensor,
|
||||
means: Tuple[float, ...],
|
||||
num_channels: int = 3,
|
||||
dtype: tf.dtypes.DType = tf.float32,
|
||||
) -> tf.Tensor:
|
||||
"""Subtracts the given means from each image channel.
|
||||
|
||||
For example:
|
||||
means = [123.68, 116.779, 103.939]
|
||||
image_bytes = mean_image_subtraction(image_bytes, means)
|
||||
|
||||
Note that the rank of `image` must be known.
|
||||
|
||||
Args:
|
||||
image_bytes: a tensor of size [height, width, C].
|
||||
means: a C-vector of values to subtract from each channel.
|
||||
num_channels: number of color channels in the image that will be distorted.
|
||||
dtype: the dtype to convert the images to. Set to `None` to skip conversion.
|
||||
|
||||
Returns:
|
||||
the centered image.
|
||||
|
||||
Raises:
|
||||
ValueError: If the rank of `image` is unknown, if `image` has a rank other
|
||||
than three or if the number of channels in `image` doesn't match the
|
||||
number of values in `means`.
|
||||
"""
|
||||
if image_bytes.get_shape().ndims != 3:
|
||||
raise ValueError('Input must be of size [height, width, C>0]')
|
||||
|
||||
if len(means) != num_channels:
|
||||
raise ValueError('len(means) must match the number of channels')
|
||||
|
||||
# We have a 1-D tensor of means; convert to 3-D.
|
||||
# Note(b/130245863): we explicitly call `broadcast` instead of simply
|
||||
# expanding dimensions for better performance.
|
||||
means = tf.broadcast_to(means, tf.shape(image_bytes))
|
||||
if dtype is not None:
|
||||
means = tf.cast(means, dtype=dtype)
|
||||
|
||||
return image_bytes - means
|
||||
|
||||
|
||||
def standardize_image(
|
||||
image_bytes: tf.Tensor,
|
||||
stddev: Tuple[float, ...],
|
||||
num_channels: int = 3,
|
||||
dtype: tf.dtypes.DType = tf.float32,
|
||||
) -> tf.Tensor:
|
||||
"""Divides the given stddev from each image channel.
|
||||
|
||||
For example:
|
||||
stddev = [123.68, 116.779, 103.939]
|
||||
image_bytes = standardize_image(image_bytes, stddev)
|
||||
|
||||
Note that the rank of `image` must be known.
|
||||
|
||||
Args:
|
||||
image_bytes: a tensor of size [height, width, C].
|
||||
stddev: a C-vector of values to divide from each channel.
|
||||
num_channels: number of color channels in the image that will be distorted.
|
||||
dtype: the dtype to convert the images to. Set to `None` to skip conversion.
|
||||
|
||||
Returns:
|
||||
the centered image.
|
||||
|
||||
Raises:
|
||||
ValueError: If the rank of `image` is unknown, if `image` has a rank other
|
||||
than three or if the number of channels in `image` doesn't match the
|
||||
number of values in `stddev`.
|
||||
"""
|
||||
if image_bytes.get_shape().ndims != 3:
|
||||
raise ValueError('Input must be of size [height, width, C>0]')
|
||||
|
||||
if len(stddev) != num_channels:
|
||||
raise ValueError('len(stddev) must match the number of channels')
|
||||
|
||||
# We have a 1-D tensor of stddev; convert to 3-D.
|
||||
# Note(b/130245863): we explicitly call `broadcast` instead of simply
|
||||
# expanding dimensions for better performance.
|
||||
stddev = tf.broadcast_to(stddev, tf.shape(image_bytes))
|
||||
if dtype is not None:
|
||||
stddev = tf.cast(stddev, dtype=dtype)
|
||||
|
||||
return image_bytes / stddev
|
||||
|
||||
|
||||
def normalize_images(features: tf.Tensor,
|
||||
mean_rgb: Tuple[float, ...] = MEAN_RGB,
|
||||
stddev_rgb: Tuple[float, ...] = STDDEV_RGB,
|
||||
num_channels: int = 3,
|
||||
dtype: tf.dtypes.DType = tf.float32,
|
||||
data_format: Text = 'channels_last') -> tf.Tensor:
|
||||
"""Normalizes the input image channels with the given mean and stddev.
|
||||
|
||||
Args:
|
||||
features: `Tensor` representing decoded images in float format.
|
||||
mean_rgb: the mean of the channels to subtract.
|
||||
stddev_rgb: the stddev of the channels to divide.
|
||||
num_channels: the number of channels in the input image tensor.
|
||||
dtype: the dtype to convert the images to. Set to `None` to skip conversion.
|
||||
data_format: the format of the input image tensor
|
||||
['channels_first', 'channels_last'].
|
||||
|
||||
Returns:
|
||||
A normalized image `Tensor`.
|
||||
"""
|
||||
# TODO(allencwang) - figure out how to use mean_image_subtraction and
|
||||
# standardize_image on batches of images and replace the following.
|
||||
if data_format == 'channels_first':
|
||||
stats_shape = [num_channels, 1, 1]
|
||||
else:
|
||||
stats_shape = [1, 1, num_channels]
|
||||
|
||||
if dtype is not None:
|
||||
features = tf.image.convert_image_dtype(features, dtype=dtype)
|
||||
|
||||
if mean_rgb is not None:
|
||||
mean_rgb = tf.constant(mean_rgb,
|
||||
shape=stats_shape,
|
||||
dtype=features.dtype)
|
||||
mean_rgb = tf.broadcast_to(mean_rgb, tf.shape(features))
|
||||
features = features - mean_rgb
|
||||
|
||||
if stddev_rgb is not None:
|
||||
stddev_rgb = tf.constant(stddev_rgb,
|
||||
shape=stats_shape,
|
||||
dtype=features.dtype)
|
||||
stddev_rgb = tf.broadcast_to(stddev_rgb, tf.shape(features))
|
||||
features = features / stddev_rgb
|
||||
|
||||
return features
|
||||
|
||||
|
||||
def decode_and_center_crop(image_bytes: tf.Tensor,
|
||||
image_size: int = IMAGE_SIZE,
|
||||
crop_padding: int = CROP_PADDING) -> tf.Tensor:
|
||||
"""Crops to center of image with padding then scales image_size.
|
||||
|
||||
Args:
|
||||
image_bytes: `Tensor` representing an image binary of arbitrary size.
|
||||
image_size: image height/width dimension.
|
||||
crop_padding: the padding size to use when centering the crop.
|
||||
|
||||
Returns:
|
||||
A decoded and cropped image `Tensor`.
|
||||
"""
|
||||
decoded = image_bytes.dtype != tf.string
|
||||
shape = (tf.shape(image_bytes) if decoded
|
||||
else tf.image.extract_jpeg_shape(image_bytes))
|
||||
image_height = shape[0]
|
||||
image_width = shape[1]
|
||||
|
||||
padded_center_crop_size = tf.cast(
|
||||
((image_size / (image_size + crop_padding)) *
|
||||
tf.cast(tf.minimum(image_height, image_width), tf.float32)),
|
||||
tf.int32)
|
||||
|
||||
offset_height = ((image_height - padded_center_crop_size) + 1) // 2
|
||||
offset_width = ((image_width - padded_center_crop_size) + 1) // 2
|
||||
crop_window = tf.stack([offset_height, offset_width,
|
||||
padded_center_crop_size, padded_center_crop_size])
|
||||
if decoded:
|
||||
image = tf.image.crop_to_bounding_box(
|
||||
image_bytes,
|
||||
offset_height=offset_height,
|
||||
offset_width=offset_width,
|
||||
target_height=padded_center_crop_size,
|
||||
target_width=padded_center_crop_size)
|
||||
else:
|
||||
image = tf.image.decode_and_crop_jpeg(image_bytes, crop_window, channels=3)
|
||||
|
||||
image = resize_image(image_bytes=image,
|
||||
height=image_size,
|
||||
width=image_size)
|
||||
|
||||
return image
|
||||
|
||||
|
||||
def decode_crop_and_flip(image_bytes: tf.Tensor) -> tf.Tensor:
|
||||
"""Crops an image to a random part of the image, then randomly flips.
|
||||
|
||||
Args:
|
||||
image_bytes: `Tensor` representing an image binary of arbitrary size.
|
||||
|
||||
Returns:
|
||||
A decoded and cropped image `Tensor`.
|
||||
|
||||
"""
|
||||
decoded = image_bytes.dtype != tf.string
|
||||
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4])
|
||||
shape = (tf.shape(image_bytes) if decoded
|
||||
else tf.image.extract_jpeg_shape(image_bytes))
|
||||
sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
|
||||
shape,
|
||||
bounding_boxes=bbox,
|
||||
min_object_covered=0.1,
|
||||
aspect_ratio_range=[0.75, 1.33],
|
||||
area_range=[0.05, 1.0],
|
||||
max_attempts=100,
|
||||
use_image_if_no_bounding_boxes=True)
|
||||
bbox_begin, bbox_size, _ = sample_distorted_bounding_box
|
||||
|
||||
# Reassemble the bounding box in the format the crop op requires.
|
||||
offset_height, offset_width, _ = tf.unstack(bbox_begin)
|
||||
target_height, target_width, _ = tf.unstack(bbox_size)
|
||||
crop_window = tf.stack([offset_height, offset_width,
|
||||
target_height, target_width])
|
||||
if decoded:
|
||||
cropped = tf.image.crop_to_bounding_box(
|
||||
image_bytes,
|
||||
offset_height=offset_height,
|
||||
offset_width=offset_width,
|
||||
target_height=target_height,
|
||||
target_width=target_width)
|
||||
else:
|
||||
cropped = tf.image.decode_and_crop_jpeg(image_bytes,
|
||||
crop_window,
|
||||
channels=3)
|
||||
|
||||
# Flip to add a little more random distortion in.
|
||||
cropped = tf.image.random_flip_left_right(cropped)
|
||||
return cropped
|
||||
|
||||
|
||||
def resize_image(image_bytes: tf.Tensor,
|
||||
height: int = IMAGE_SIZE,
|
||||
width: int = IMAGE_SIZE) -> tf.Tensor:
|
||||
"""Resizes an image to a given height and width.
|
||||
|
||||
Args:
|
||||
image_bytes: `Tensor` representing an image binary of arbitrary size.
|
||||
height: image height dimension.
|
||||
width: image width dimension.
|
||||
|
||||
Returns:
|
||||
A tensor containing the resized image.
|
||||
|
||||
"""
|
||||
return tf.compat.v1.image.resize(
|
||||
image_bytes, [height, width], method=tf.image.ResizeMethod.BILINEAR,
|
||||
align_corners=False)
|
||||
|
||||
|
||||
def preprocess_for_predict(
|
||||
images: tf.Tensor,
|
||||
image_size: int = IMAGE_SIZE,
|
||||
num_channels: int = 3,
|
||||
dtype: tf.dtypes.DType = tf.float32
|
||||
) -> tf.Tensor:
|
||||
images = tf.reshape(images, [image_size, image_size, num_channels])
|
||||
if dtype is not None:
|
||||
images = tf.image.convert_image_dtype(images, dtype=dtype)
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def preprocess_for_eval(
|
||||
image_bytes: tf.Tensor,
|
||||
image_size: int = IMAGE_SIZE,
|
||||
num_channels: int = 3,
|
||||
mean_subtract: bool = False,
|
||||
standardize: bool = False,
|
||||
dtype: tf.dtypes.DType = tf.float32
|
||||
) -> tf.Tensor:
|
||||
"""Preprocesses the given image for evaluation.
|
||||
|
||||
Args:
|
||||
image_bytes: `Tensor` representing an image binary of arbitrary size.
|
||||
image_size: image height/width dimension.
|
||||
num_channels: number of image input channels.
|
||||
mean_subtract: whether or not to apply mean subtraction.
|
||||
standardize: whether or not to apply standardization.
|
||||
dtype: the dtype to convert the images to. Set to `None` to skip conversion.
|
||||
|
||||
Returns:
|
||||
A preprocessed and normalized image `Tensor`.
|
||||
"""
|
||||
images = decode_and_center_crop(image_bytes, image_size)
|
||||
images = tf.reshape(images, [image_size, image_size, num_channels])
|
||||
|
||||
if mean_subtract:
|
||||
images = mean_image_subtraction(image_bytes=images, means=MEAN_RGB)
|
||||
if standardize:
|
||||
images = standardize_image(image_bytes=images, stddev=STDDEV_RGB)
|
||||
if dtype is not None:
|
||||
images = tf.image.convert_image_dtype(images, dtype=dtype)
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def load_eval_image(filename: Text, image_size: int = IMAGE_SIZE) -> tf.Tensor:
|
||||
"""Reads an image from the filesystem and applies image preprocessing.
|
||||
|
||||
Args:
|
||||
filename: a filename path of an image.
|
||||
image_size: image height/width dimension.
|
||||
|
||||
Returns:
|
||||
A preprocessed and normalized image `Tensor`.
|
||||
"""
|
||||
image_bytes = tf.io.read_file(filename)
|
||||
image = preprocess_for_eval(image_bytes, image_size)
|
||||
|
||||
return image
|
||||
|
||||
|
||||
def build_eval_dataset(filenames: List[Text],
|
||||
labels: List[int] = None,
|
||||
image_size: int = IMAGE_SIZE,
|
||||
batch_size: int = 1) -> tf.Tensor:
|
||||
"""Builds a tf.data.Dataset from a list of filenames and labels.
|
||||
|
||||
Args:
|
||||
filenames: a list of filename paths of images.
|
||||
labels: a list of labels corresponding to each image.
|
||||
image_size: image height/width dimension.
|
||||
batch_size: the batch size used by the dataset
|
||||
|
||||
Returns:
|
||||
A preprocessed and normalized image `Tensor`.
|
||||
"""
|
||||
if labels is None:
|
||||
labels = [0] * len(filenames)
|
||||
|
||||
filenames = tf.constant(filenames)
|
||||
labels = tf.constant(labels)
|
||||
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
|
||||
|
||||
dataset = dataset.map(
|
||||
lambda filename, label: (load_eval_image(filename, image_size), label))
|
||||
dataset = dataset.batch(batch_size)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
def preprocess_for_train(image_bytes: tf.Tensor,
|
||||
image_size: int = IMAGE_SIZE,
|
||||
augmenter: Optional[augment.ImageAugment] = None,
|
||||
mean_subtract: bool = False,
|
||||
standardize: bool = False,
|
||||
dtype: tf.dtypes.DType = tf.float32) -> tf.Tensor:
|
||||
"""Preprocesses the given image for training.
|
||||
|
||||
Args:
|
||||
image_bytes: `Tensor` representing an image binary of
|
||||
arbitrary size of dtype tf.uint8.
|
||||
image_size: image height/width dimension.
|
||||
augmenter: the image augmenter to apply.
|
||||
mean_subtract: whether or not to apply mean subtraction.
|
||||
standardize: whether or not to apply standardization.
|
||||
dtype: the dtype to convert the images to. Set to `None` to skip conversion.
|
||||
|
||||
Returns:
|
||||
A preprocessed and normalized image `Tensor`.
|
||||
"""
|
||||
images = decode_crop_and_flip(image_bytes=image_bytes)
|
||||
images = resize_image(images, height=image_size, width=image_size)
|
||||
if mean_subtract:
|
||||
images = mean_image_subtraction(image_bytes=images, means=MEAN_RGB)
|
||||
if standardize:
|
||||
images = standardize_image(image_bytes=images, stddev=STDDEV_RGB)
|
||||
if augmenter is not None:
|
||||
images = augmenter.distort(images)
|
||||
if dtype is not None:
|
||||
images = tf.image.convert_image_dtype(images, dtype)
|
||||
|
||||
return images
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
import numpy as np
|
||||
import tensorflow as tf
|
||||
import horovod.tensorflow as hvd
|
||||
|
||||
|
||||
def set_flags(params):
|
||||
# os.environ['CUDA_CACHE_DISABLE'] = '1'
|
||||
os.environ['HOROVOD_GPU_ALLREDUCE'] = 'NCCL'
|
||||
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
|
||||
# os.environ['TF_GPU_THREAD_MODE'] = 'gpu_private'
|
||||
# os.environ['TF_USE_CUDNN_BATCHNORM_SPATIAL_PERSISTENT'] = '0'
|
||||
os.environ['TF_ADJUST_HUE_FUSED'] = '1'
|
||||
os.environ['TF_ADJUST_SATURATION_FUSED'] = '1'
|
||||
os.environ['TF_ENABLE_WINOGRAD_NONFUSED'] = '1'
|
||||
# os.environ['TF_SYNC_ON_FINISH'] = '0'
|
||||
os.environ['TF_AUTOTUNE_THRESHOLD'] = '2'
|
||||
os.environ['HOROVOD_CACHE_CAPACITY'] = "0"
|
||||
os.environ['HOROVOD_CYCLE_TIME'] = "1.0"
|
||||
if params.intraop_threads:
|
||||
os.environ['TF_NUM_INTRAOP_THREADS'] = params.intraop_threads
|
||||
if params.interop_threads:
|
||||
os.environ['TF_NUM_INTEROP_THREADS'] = params.interop_threads
|
||||
|
||||
if params.use_xla:
|
||||
os.environ['TF_XLA_FLAGS'] = "--tf_xla_enable_lazy_compilation=false --tf_xla_auto_jit=1 --tf_xla_async_io_level=1"
|
||||
os.environ['TF_EXTRA_PTXAS_OPTIONS'] = "-sw200428197=true"
|
||||
tf.keras.backend.clear_session()
|
||||
tf.config.optimizer.set_jit(True)
|
||||
|
||||
gpus = tf.config.experimental.list_physical_devices('GPU')
|
||||
for gpu in gpus:
|
||||
tf.config.experimental.set_memory_growth(gpu, True)
|
||||
assert tf.config.experimental.get_memory_growth(gpu)
|
||||
tf.config.experimental.set_visible_devices(gpus, 'GPU')
|
||||
if gpus:
|
||||
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
|
||||
|
||||
|
||||
np.random.seed(params.seed)
|
||||
tf.random.set_seed(params.seed)
|
||||
|
||||
if params.use_amp:
|
||||
policy = tf.keras.mixed_precision.experimental.Policy('mixed_float16', loss_scale='dynamic')
|
||||
tf.keras.mixed_precision.experimental.set_policy(policy)
|
||||
else:
|
||||
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '0'
|
||||
Loading…
Reference in a new issue