| .. | ||
| examples | ||
| image_classification | ||
| img | ||
| resnet50v1.5 | ||
| Dockerfile | ||
| LICENSE | ||
| main.py | ||
| multiproc.py | ||
| README.md | ||
ResNet50 v1.5
The model
The ResNet50 v1.5 model is a modified version of the original ResNet50 v1 model.
The difference between v1 and v1.5 is that, in the bottleneck blocks which requires downsampling, v1 has stride = 2 in the first 1x1 convolution, whereas v1.5 has stride = 2 in the 3x3 convolution.
This difference makes ResNet50 v1.5 slightly more accurate (~0.5% top1) than v1, but comes with a smallperformance drawback (~5% imgs/sec).
The model is initialized as described in Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
Training procedure
Optimizer
This model trains for 90 epochs, with standard ResNet v1.5 setup:
-
SGD with momentum (0.875)
-
Learning rate = 0.256 for 256 batch size, for other batch sizes we lineary scale the learning rate.
-
Learning rate schedule - we use cosine LR schedule
-
For bigger batch sizes (512 and up) we use linear warmup of the learning rate during first couple of epochs according to Training ImageNet in 1 hour. Warmup length depends on total training length.
-
Weight decay: 3.0517578125e-05 (1/32768).
-
We do not apply WD on Batch Norm trainable parameters (gamma/bias)
-
Label Smoothing: 0.1
-
We train for:
-
50 Epochs -> configuration that reaches 75.9% top1 accuracy
-
90 Epochs -> 90 epochs is a standard for ResNet50
-
250 Epochs -> best possible accuracy.
-
-
For 250 epoch training we also use MixUp regularization.
Data Augmentation
This model uses the following data augmentation:
-
For training:
- Normalization
- Random resized crop to 224x224
- Scale from 8% to 100%
- Aspect ratio from 3/4 to 4/3
- Random horizontal flip
-
For inference:
- Normalization
- Scale to 256x256
- Center crop to 224x224
Other training recipes
This script does not targeting any specific benchmark. There are changes that others have made which can speed up convergence and/or increase accuracy.
One of the more popular training recipes is provided by fast.ai.
The fast.ai recipe introduces many changes to the training procedure, one of which is progressive resizing of the training images.
The first part of training uses 128px images, the middle part uses 224px images, and the last part uses 288px images. The final validation is performed on 288px images.
Training script in this repository performs validation on 224px images, just like the original paper described.
These two approaches can't be directly compared, since the fast.ai recipe requires validation on 288px images, and this recipe keeps the original assumption that validation is done on 224px images.
Using 288px images means that a lot more FLOPs are needed during inference to reach the same accuracy.
Setup
Requirements
Ensure you meet the following requirements:
- NVIDIA Docker
- PyTorch 19.05-py3 NGC container or newer
- (optional) NVIDIA Volta GPU (see section below) - for best training performance using mixed precision
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning DGX Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running PyTorch
Training using mixed precision with Tensor Cores
Hardware requirements
Training with mixed precision on NVIDIA Tensor Cores, requires an NVIDIA Volta-based GPU.
Software changes
For information about how to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
For PyTorch, easily adding mixed-precision support is available from NVIDIA’s APEX, a PyTorch extension, that contains utility libraries, such as AMP, which require minimal network code changes to leverage Tensor Core performance.
DALI
For DGX2 configurations we use NVIDIA DALI, which speeds up data loading when CPU becomes a bottleneck.
Run training with --data-backends dali-gpu to enable DALI.
Quick start guide
Geting the data
The ResNet50 v1.5 script operates on ImageNet 1k, a widely popular image classification dataset from ILSVRC challenge.
PyTorch can work directly on JPEGs, therefore, preprocessing/augmentation is not needed.
-
Download the images from http://image-net.org/download-images
-
Extract the training data:
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train
tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar
find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
cd ..
- Extract the validation data and move the images to subfolders:
mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash
The directory in which the train/ and val/ directories are placed, is referred to as <path to imagenet> in this document.
Running training
To run training for a standard configuration (DGX1V/DGX2V, FP16/FP32, 50/90/250 Epochs),
run one of the scripts in the ./resnet50v1.5/training directory
called ./resnet50v1.5/training/{DGX1, DGX2}_RN50_{FP16, FP32}_{50,90,250}E.sh.
Ensure imagenet is mounted in the /data/imagenet directory.
To run a non standard configuration use:
-
For 1 GPU
- FP32
python ./main.py --arch resnet50 -c fanin --label-smoothing 0.1 <path to imagenet> - FP16
python ./main.py --arch resnet50 -c fanin --label-smoothing 0.1 --fp16 --static-loss-scale 256 <path to imagenet>
- FP32
-
For multiple GPUs
- FP32
python ./multiproc.py --nproc_per_node 8 ./main.py --arch resnet50 -c fanin --label-smoothing 0.1 <path to imagenet> - FP16
python ./multiproc.py --nproc_per_node 8 ./main.py --arch resnet50 -c fanin --label-smoothing 0.1 --fp16 --static-loss-scale 256 <path to imagenet>
- FP32
Use python ./main.py -h to obtain the list of available options in the main.py script.
Running inference
To run inference on a checkpointed model run:
python ./main.py --arch resnet50 --evaluate --resume <path to checkpoint> -b <batch size> <path to imagenet>
Benchmarking
Training performance
To benchmark training, run:
- For 1 GPU
- FP32
python ./main.py --arch resnet50 --training-only -p 1 --raport-file benchmark.json --epochs 1 --prof 100 <path to imagenet> - FP16
python ./main.py --arch resnet50 --training-only -p 1 --raport-file benchmark.json --epochs 1 --prof 100 --fp16 --static-loss-scale 256 <path to imagenet>
- FP32
- For multiple GPUs
- FP32
python ./multiproc.py --nproc_per_node 8 ./main.py --arch resnet50 --training-only -p 1 --raport-file benchmark.json --epochs 1 --prof 100 <path to imagenet> - FP16
python ./multiproc.py --nproc_per_node 8 ./main.py --arch resnet50 --training-only -p 1 --raport-file benchmark.json --fp16 --static-loss-scale 256 --epochs 1 --prof 100 <path to imagenet>
- FP32
Each of this scripts will run 100 iterations and save results in benchmark.json file
Inference performance
To benchmark inference, run:
- FP32
python ./main.py --arch resnet50 -p 1 --raport-file benchmark.json --epochs 1 --prof 100 --evaluate <path to imagenet>
- FP16
python ./main.py --arch resnet50 -p 1 --raport-file benchmark.json --epochs 1 --prof 100 --evaluate --fp16 <path to imagenet>
Each of this scripts will run 100 iterations and save results in benchmark.json file
Training Accuracy Results
NVIDIA DGX1V (8x V100 16G)
Accuracy
| # of epochs | mixed precision top1 | FP32 top1 |
|---|---|---|
| 50 | 76.25 +/- 0.04 | 76.26 +/- 0.07 |
| 90 | 77.23 +/- 0.04 | 77.08 +/- 0.07 |
| 250 | 78.42 +/- 0.04 | 78.30 +/- 0.16 |
Training time for 90 epochs
| number of GPUs | mixed precision training time | FP32 training time |
|---|---|---|
| 1 | ~46h | ~90h |
| 4 | ~14h | ~26h |
| 8 | ~8h | ~14h |
NVIDIA DGX2V (16x V100 32G)
Accuracy
| # of epochs | mixed precision top1 | FP32 top1 |
|---|---|---|
| 50 | 75.80 +/- 0.08 | 76.04 +/- 0.05 |
| 90 | 77.10 +/- 0.06 | 77.23 +/- 0.04 |
| 250 | 78.59 +/- 0.13 | 78.46 +/- 0.03 |
Training time for 90 epochs
| number of GPUs | mixed precision training time | FP32 training time |
|---|---|---|
| 2 | ~24h | ~45h |
| 8 | ~8h | ~13h |
| 16 | ~4h | ~7h |
Example plots (250 Epochs configuration on DGX2)
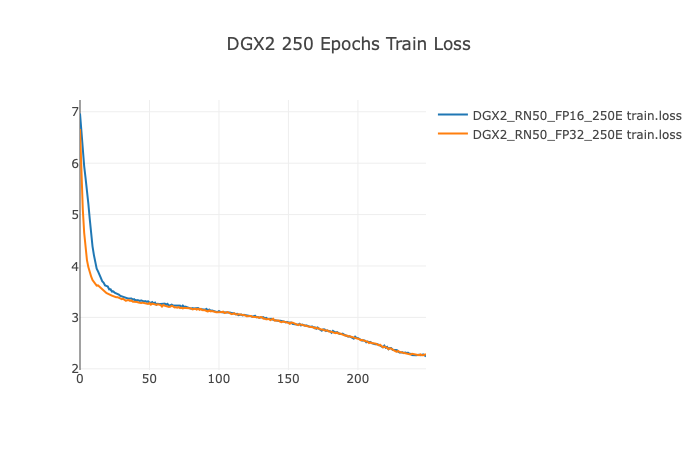
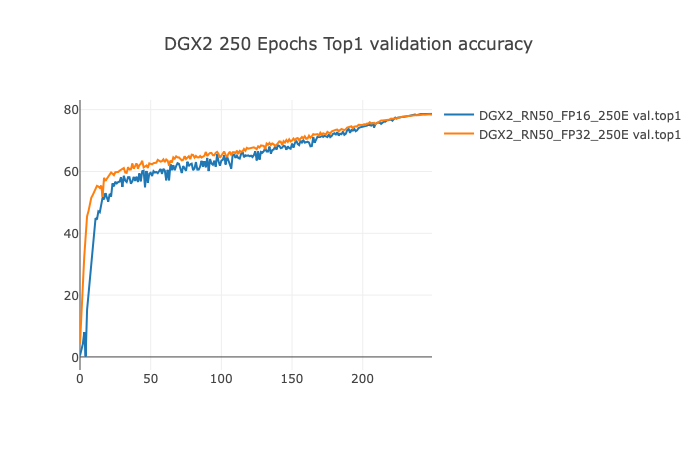
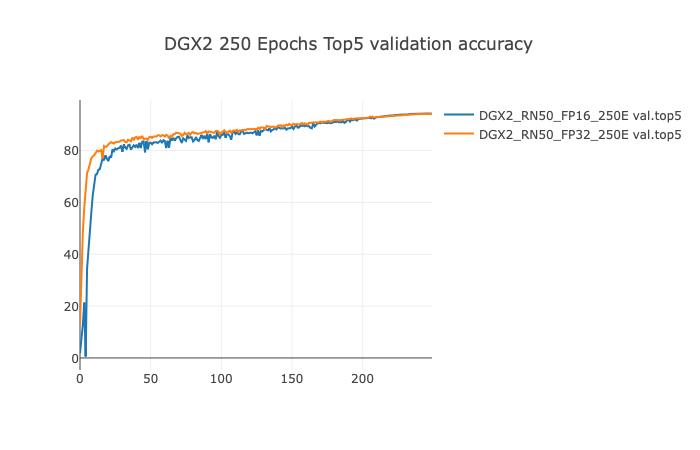
Training Performance Results
NVIDIA DGX1V (8x V100 16G)
| number of GPUs | mixed precision img/s | FP32 img/s | mixed precision speedup | mixed precision weak scaling | FP32 weak scaling |
|---|---|---|---|---|---|
| 1 | 747.3 | 363.1 | 2.06 | 1.00 | 1.00 |
| 4 | 2886.9 | 1375.5 | 2.1 | 3.86 | 3.79 |
| 8 | 5815.8 | 2857.9 | 2.03 | 7.78 | 7.87 |
NVIDIA DGX2V (16x V100 32G)
| number of GPUs | mixed precision img/s | FP32 img/s | mixed precision speedup |
|---|---|---|---|
| 16 | 12086.1 | 5578.2 | 2.16 |
Inference Performance Results
NVIDIA VOLTA V100 16G on DGX1V
| batch size | mixed precision img/s | FP32 img/s |
|---|---|---|
| 1 | 131.8 | 134.9 |
| 2 | 248.7 | 260.6 |
| 4 | 486.4 | 425.5 |
| 8 | 908.5 | 783.6 |
| 16 | 1370.6 | 998.9 |
| 32 | 2287.5 | 1092.3 |
| 64 | 2476.2 | 1166.6 |
| 128 | 2615.6 | 1215.6 |
| 256 | 2696.7 | N/A |
Changelog
- September 2018
- Initial release
- January 2019
- Added options Label Smoothing, fan-in initialization, skipping weight decay on batch norm gamma and bias.
- May 2019
- Cosine LR schedule
- MixUp regularization
- DALI support
- DGX2 configurations
- gradients accumulation
Known issues
There are no known issues with this model.