| .. | ||
| img | ||
| logger | ||
| convert.py | ||
| Dockerfile | ||
| download_dataset.sh | ||
| fp_optimizers.py | ||
| LICENSE.md | ||
| load.py | ||
| ncf.py | ||
| neumf.py | ||
| prepare_dataset.sh | ||
| README.md | ||
| requirements.txt | ||
| utils.py | ||
| verify_dataset.sh | ||
Neural Collaborative Filtering (NCF)
The model
The NCF model focuses on providing recommendations, also known as collaborative filtering; with implicit feedback. The training data for this model should contain binary information about whether a user interacted with a specific item. NCF was first described by Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu and Tat-Seng Chua in the Neural Collaborative Filtering paper.
The implementation in this repository focuses on the NeuMF instantiation of the NCF architecture. We modified it to use dropout in the FullyConnected layers. This reduces overfitting and increases the final accuracy. Training the other two instantiations of NCF (GMF and MLP) is not supported.

Figure 1. The architecture of a Neural Collaborative Filtering model. Taken from the Neural Collaborative Filtering paper.
Contrary to the original paper, we benchmark the model on the larger ml-20m dataset instead of using the smaller ml-1m dataset as we think this is more realistic of production type environments. However, using the ml-1m dataset is also supported.
Requirements
The easiest way to train the model is to use a Docker container. This would require:
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Frameworks Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running PyTorch
Training using mixed precision with Tensor Cores
Supported hardware
Before you can train using mixed precision with Tensor Cores, ensure that you have an NVIDIA Volta based GPU. Other platforms may work, however, are not officially supported.
Software changes
For detailed information about how to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
Another option for adding mixed-precision support is available from NVIDIA’s APEX, a PyTorch extension, that contains utility libraries, such as AMP, which require minimal network code changes to leverage Tensor Core performance.
This implementation of the NCF model uses a custom FP16 optimizer to implement mixed precision with static loss scaling. The custom FP16 Optimizer was used to take advantage of the performance gains provided by the FusedOptimizer.
Quick start guide
1. Build and launch an NCF PyTorch Docker container
After Docker is correctly set up, you can build the NCF image with:
docker build . -t nvidia_ncf
After that the NVIDIA NCF container can be launched with:
mkdir data
docker run --runtime=nvidia -it --rm --ipc=host -v ${PWD}/data:/data nvidia_ncf bash
This will launch the container and mount the ./data directory as a volume to the /data directory inside the container. Any datasets and experiment results (logs, checkpoints etc.) saved to /data will be accessible in the './data' directory on the host.
2. Data preparation
Preprocessing consists of downloading the data, filtering out users that have less than 20 ratings (by default), sorting the data and dropping the duplicates. The preprocessed train and test data is then saved in PyTorch binary format to be loaded just before training.
No data augmentation techniques are used.
To download and preprocess the ml-20m dataset you can run:
./prepare_dataset.sh
Please note that this command will return immediately without downloading anything if the data is already present in the /data directory.
Other datasets
This implementation is tuned for the ml-20m and ml-1m datasets. Using other datasets might require tuning some hyperparameters (e.g., learning rate, beta1, beta2)
If you'd like to use your custom dataset you can do it by adding support for it in the prepare_dataset.sh and download_dataset.sh scripts. The required format of the data is a CSV file in which the first column contains the userID and the second column contains the itemID.
The performance of the model depends on the dataset size. Generally, the model should scale better for datasets containing more data points. For a smaller dataset the you might experience slower performance.
ml-1m
To download and preprocess the ml-1m dataset run:
./prepare_dataset.sh ml-1m
This will store the preprocessed training and evaluation data in the /data directory so that it can be later used to train the model (by passing the appropriate --data argument to the ncf.py script).
3. Run the training
After the docker container is launched, the training with the default hyperparameters can be started with:
./prepare_dataset.sh
python -m torch.distributed.launch --nproc_per_node=8 ncf.py --data /data/cache/ml-20m
This will result in a checkpoint file being written to /data/checkpoints/model.pth.
4. Test a trained model
The trained model can be evaluated by passing the --mode test flag to the run.sh script:
python -m torch.distributed.launch --nproc_per_node=8 ncf.py --data /data/cache/ml-20m --mode test --checkpoint-path /data/checkpoints/model.pth
5. Hyperparameters and command line arguments
The default hyperparameters used are:
- learning rate: 0.0045
- beta1: 0.25
- beta2: 0.5
- training batch size: 1048576
- epsilon: 1e-8
- loss scale: 8192
- negatives sampled for training: 4
- use mixed precision training: Yes
- number of GPUs used: 8
All these parameters can be controlled by passing command line arguments to the ncf.py script. To get a complete list of all command line arguments with descriptions and default values you can run:
python ncf.py --help
Training accuracy results
The following table lists the best hit rate at 10 for DGX-1 with 8 V100 32G GPUs:
| Number of GPUs | Full precision HR@10 | Mixed precision HR@10 |
|---|---|---|
| 1 | 0.959015 | 0.959485 |
| 4 | 0.959389 | 0.959274 |
| 8 | 0.959015 | 0.96 |
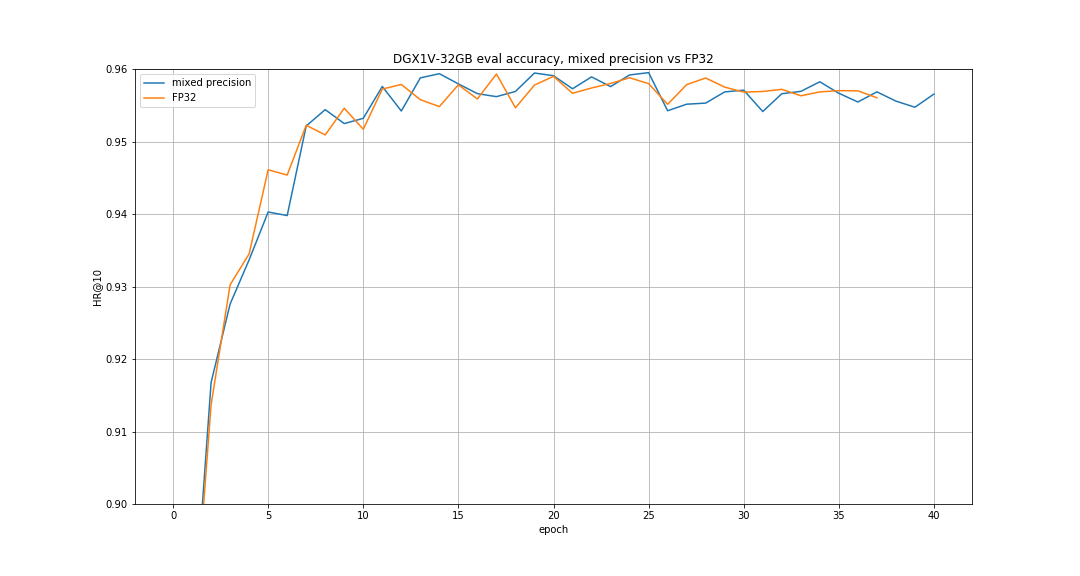
Here's an example validation accuracy curve for mixed precision vs full precision on DGX-1 with 8 V100 32G GPUs:
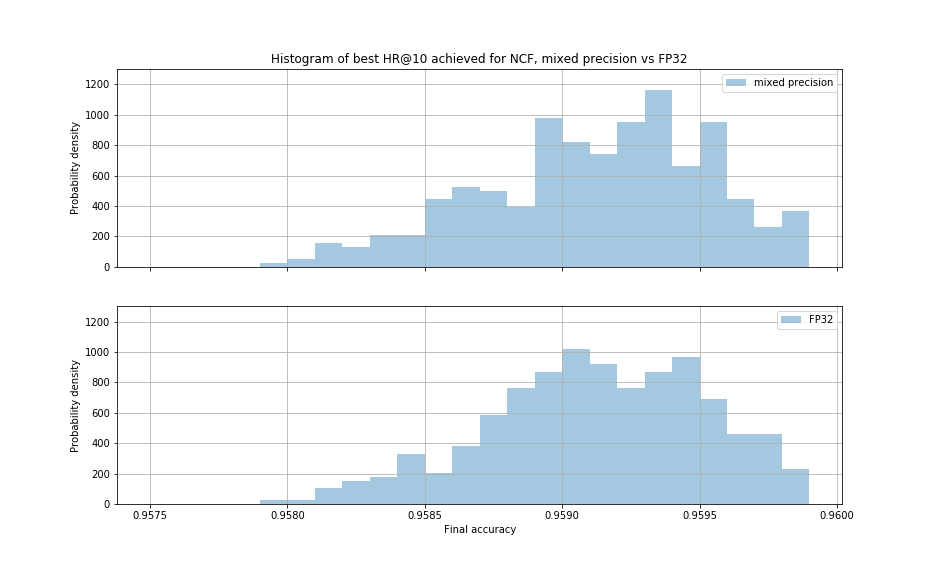
The histogram below shows the best HR@10 achieved
for 400 experiments using mixed precision and 400 experiments using single precision.
Mean HR@10 for mixed precision was equal to 0.95917 and for single precision it was equal to
0.95915.
Training performance results
This example is based on our submission for the MLPerf v0.5 benchmark. Please note that we've introduced some improvements to this version that make time-to-train not directly comparable between it and our MLPerf submission:
- This version uses a more efficient multi-gpu sharding algorithm
- We added dropout operations here to achieve better accuracy
- This version uses 100 negatives by default during the evaluation phase as was done in the original NCF paper. MLPerf version used 999
- We save the model checkpoints in this version. This might make the training a few seconds slower depending on the speed of your storage
NVIDIA DGX-1 with 8 V100 16G GPUs
The following table shows the best training throughput:
| Number of GPUs (samples/sec) | Mixed precision (samples/sec) | Full precision (samples/sec) | Speedup |
|---|---|---|---|
| 1 | 20,027,840 | 9,529,271 | 2.10 |
| 4 | 62,633,260 | 32,719,700 | 1.91 |
| 8 | 99,332,230 | 55,004,590 | 1.81 |
The following table shows mean time to reach HR@10 of 0.9562 across 5 random seeds. The training time was measured excluding data downloading, preprocessing and library initialization times.
| Number of GPUs (samples/sec) | Mixed precision (seconds) | Full precision (seconds) | Speedup |
|---|---|---|---|
| 1 | 78.73 | 153.90 | 1.95 |
| 4 | 25.80 | 49.41 | 1.92 |
| 8 | 20.42 | 32.68 | 1.60 |
NVIDIA DGX-1 with 8 V100 32G GPUs
The following table shows the best training throughput:
| Number of GPUs (samples/sec) | Mixed precision (samples/sec) | Full precision (samples/sec) | Speedup |
|---|---|---|---|
| 1 | 18,871,650 | 9,206,424 | 2.05 |
| 4 | 59,413,640 | 31,898,870 | 1.86 |
| 8 | 94,752,770 | 53,645,640 | 1.77 |
The following table shows mean time to reach HR@10 of 0.9562 across 5 random seeds. The training time was measured excluding data downloading, preprocessing and library initialization times.
| Number of GPUs (samples/sec) | Mixed precision (seconds) | Full precision (seconds) | Speedup |
|---|---|---|---|
| 1 | 79.80 | 147.92 | 1.85 |
| 4 | 27.67 | 47.64 | 1.72 |
| 8 | 22.61 | 31.62 | 1.40 |
Inference performance results
NVIDIA DGX-1 with 8 V100 16G GPUs
The following table shows the best inference throughput:
| Number of GPUs (samples/sec) | Mixed precision (samples/sec) | Full precision (samples/sec) | Speedup |
|---|---|---|---|
| 1 | 58,836,420 | 28,964,964 | 2.03 |
NVIDIA DGX-1 with 8 V100 32G GPUs
The following table shows the best inference throughput:
| Number of GPUs (samples/sec) | Mixed precision (samples/sec) | Full precision (samples/sec) | Speedup |
|---|---|---|---|
| 1 | 55,317,010 | 28,470,920 | 1.94 |
Changelog
- January 22, 2018
- Initial release
Known issues
Scaling beyond 8 GPUs
Neural Collaborative Filtering is a relatively lightweight model that trains quickly with this relatively smaller dataset, ml-20m. Because of that the high ratio of communication to computation makes it difficult to efficiently use more than 8 GPUs. Normally this is not an issue because when using 8 GPUs with fp16 precision the training is sufficiently fast. However, if you’d like to scale the training to 16 GPUs and beyond you might try modifying the model so that the communication-computation ratio facilitates better scaling. This could be done e.g., by finding hyperparameters that enable using a larger batch size or by reducing the number of trainable parameters.
Memory usage
Training on a single GPU with less than 16GB of memory or switching off FP16 mode might result in out-of-memory errors. To reduce memory usage you can use a smaller batch size. However, since we’re using the Adam optimizer, this might require changing the hyperparameters such as learning rate, beta1 and beta2. To circumvent this you can use gradient accumulation to combine multiple gradients computed from smaller batches into a single weight update. This should keep the “effective” batch size the same as original and enable using the default hyperparameters with much lower memory usage:
python -m torch.distributed.launch --nproc_per_node=8 ncf.py --data /data/cache/ml-20m --grads_accumulated 2 --batch-size 524288
In the default settings the additional memory beyond 16G may not be fully utilized. This is because we set the default batch size for ml-20m dataset to 1M, which is too small to completely fill up multiple 32G GPUs. 1M is the batch size for which we experienced the best convergence on the ml-20m dataset. However, on other datasets even faster performance can be possible by finding hyperparameters that work well for larger batches and leverage additional GPU memory.