| .. | ||
| cutlass@ed2ed4d667 | ||
| examples | ||
| fairseq | ||
| scripts | ||
| tests | ||
| .gitmodules | ||
| BLEU.png | ||
| CONTRIBUTING.md | ||
| distributed_train.py | ||
| Dockerfile | ||
| eval_lm.py | ||
| fairseq.gif | ||
| generate.py | ||
| interactive.py | ||
| LICENSE | ||
| multiprocessing_train.py | ||
| NOTICE | ||
| PATENTS | ||
| preprocess.py | ||
| README.md | ||
| requirements.txt | ||
| run_preprocessing.sh | ||
| score.py | ||
| setup.py | ||
| train.py | ||
{kind=link}
{kind=link}
Transformer
This implementation of the Transformer model architecture is based on the optimized implementation in Facebook's Fairseq NLP toolkit, built on top of PyTorch. The original version in the Fairseq project was developed using Tensor Cores, which provides significant training speedup. Our implementation improves the performance of a training and is tested on a DGX-1V 16GB.
Requirements and installation
This repository contains a Dockerfile which extends the PyTorch NGC container and encapsulates all dependencies. Ensure you have the following software:
If you use multiprocessing for multi-threaded data loaders, the default shared memory segment size that the container runs with may not be enough. Therefore, we recommend you to increase the shared memory size by issuing either:
--ipc=host
Or
--shm-size=<requested memory size>
in the command line to nvidia-docker run. For more information,see Setting The Shared Memory Flag in the NVIDIA Container User Guide.
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning DGX Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running PyTorch
Training using mixed precision with Tensor Cores
The training script provided in this project takes advantage of Tensor Cores to speedup the time it takes to train the Transformer model (for a translation task in this example). Tensor Cores accelerate matrix multiplication math and are available on NVIDIA Volta and Turing based GPUs. For more information about how to use Tensor Cores, see the Training With Mixed Precision Guide to Mixed Precision Training on NVIDIA GPUs.
An additional resource for mixed precision training is NVIDIA’s Apex, a PyTorch extension, that contains utility libraries, such as AMP, which stands for Automatic Mixed Precision and enables the use of Tensor Cores with minimal code changes to existing PyTorch training scripts.
Hyper parameters setting
To reach the BLEU score reported in Scaling Neural Machine Translation reaserch paper, we used mixed precision training with a batch size of 5120 per GPU and learning rate of 6e-4 on a DGX-1V system with 8 Tesla V100s 16G. If you use a different setup, we recommend you scale your hyperparameters by applying the following rules:
- To use FP32, reduce the batch size to 2560 and set the
--update-freq 2and--warmup-updates 8000options. - To train on a fewer GPUs, multiply
--update-freqand--warmup-updatesby the reciprocal of scaling factor.
For example, when training in FP32 mode on 4 GPUs, use the --update-freq=4 and --warmup-updates 16000 options.
Quick start guide
Perform the following steps to train using provided default parameters of the Transformer model on the WMT14 English-German dataset.
Build and launch Transformer Docker container
docker build . -t your.repository:transformer
nvidia-docker run -it --rm --ipc=host -v /path/to/your/dataset:/container/dataset/path your.repository:transformer bash
Downloading and preprocessing dataset
Download and preprocess the WMT14 English-German dataset.
./run_preprocessing.sh
Run training
The following command runs the training script that is distributed between 8 workers.
python -m torch.distributed.launch --nproc_per_node 8 /workspace/translation/train.py /workspace/data-bin/wmt14_en_de_joined_dict \
--arch transformer_wmt_en_de_big_t2t \
--share-all-embeddings \
--optimizer adam \
--adam-betas '(0.9, 0.997)' \
--adam-eps "1e-9" \
--clip-norm 0.0 \
--lr-scheduler inverse_sqrt \
--warmup-init-lr 0.0 \
--warmup-updates 4000 \
--lr 0.0006 \
--min-lr 0.0 \
--dropout 0.1 \
--weight-decay 0.0 \
--criterion label_smoothed_cross_entropy \
--label-smoothing 0.1 \
--max-tokens 5120 \
--seed 1 \
--target-bleu 28.3 \
--ignore-case \
--fp16 \
--save-dir /workspace/checkpoints \
--distributed-init-method env://
WARNING: If you don't have access to sufficient disk space, use the --save-interval $N option. The checkpoints are ~2.5GB large. For example it takes the Transformer model 16 epochs to reach the BLEU score of 28 points. Default option is to save the latest checkpoint, the best checkpoint and a checkpoint for every epoch, which means (16+1+1)*2.5GB = 45GB of a disk space used. Specifying --save-interval 5 you can reduce this to (16/5+1+1)*2.5GB = 12.5GB.
Details
Getting the data
The Transformer model was trained on the WMT14 English-German dataset. Concatenation of the commoncrawl, europarl and news-commentary is used as train and vaidation dataset and newstest2014 is used as test dataset.
This repository contains run_preprocessing.sh script which will automatically download and preprocess the training and test datasets. By default data will be stored in /data/wmt14_en_de_joined_dict directory.
Our download script utilizes Moses decoder to perform tokenization of the dataset and subword-nmt to segment text into subword units (BPE). By default, script builds shared vocabulary of 33708 tokens, which is constistent withbuilds shared vocabulary of 33708 tokens, which is constistent with Scaling Neural Machine Translation.
Running training
The default training configuration can be launched ny running the train.py training script. By default, the script saves one checkpoint evety epoch in addition to the latest and the best ones. The best chckpoint is considered the one with the lowest value of loss, not the one with the highest BLEU score. To override this behavior use the --save-interval $N option to save epoch checkpoints every N epoch or --no-epoch-checkpoints to disable them entirely (with this option latest and the best checkpoints still will be saved). Specify save directory with --save-dir option.
In order to run multi-GPU training launch the training script with python -m torch.distributed.launch --nproc_per_node $N prepended, where N is the number of GPUs.
We have tested reliance on up to 16 GPUs on a single node.
After each training epoch, the script runs a loss validation on the validation split of the dataset and outputs validation loss. By default the evaluation after each epoch is disabled. To enable it use --online-eval option or to use BLEU score value as training stopping condition use --target-bleu $TGT option. In order to compute case insensitive BLEU score use flag --ignore-case along with previous ones. BLEU is computed by the internal fairseq algorithm which implementation can be found in fairseq/bleu.py script.
By default, the train.py script will launch fp32 training without Tensor Cores. To use mixed precision with Tensor Cores use --fp16 option.
To view all available options for training, run python train.py --help.
Running inference
Inference on a raw input can be performed by launching interactive.py inference script. It requires pre-trained model checkpoint,BPE codes file and dictionary file (both are produced by run_preprocessing.sh script and can be found in the dataset directory).
To enhance speed of the inference on large input files it is recommended to preprocess them the same way as the dataset and run inference on a binarized input with the generate.py script.
Both scripts run inference with a default beam size of 4 and give tokenized output. To remove BPE codes use --remove-bpe option.
To view all available options for training, run python interactive.py --help.
Testing
Computing BLEU score is contained inside the training script and can be used to determine when the script should stop the training. To disable this feature replace --target-bleu $BLEU$ and --ignore-case options with --max-epoch $N, where N is number of training epochs. By default, evaluation of the Transformer model is then performed on the binarized test split of the dataset by default. To evaluate the model, issue:
python generate.py /path/to/dataset/wmt14_en_de_joined_dict \
--path /path/to/your/checkpoint.pt \
--beam 4 --remove-bpe
In order to use SacreBLEU for evaluation, run:
sacrebleu -t wmt14/full -l en-de --echo src > wmt14-en-de.src
python interactive.py --buffer-size 1 --fp16 --path /path/to/your/checkpoint.pt --max-tokens 128 \
--fuse-dropout-add --remove-bpe --bpe-codes /path/to/code/file \
/path/to/dataset/wmt14_en_de_joined_dict/ < wmt14-en-de.src > wmt14.detok
grep ^H wmt14.detok | cut -f3- > wmt14.translated
cat wmt14.translated | sacrebleu -t wmt14 -lc -l en-de
Sacrebleu test set is a subset of test set used during a course of training thus score obtained with sacreBLEU can slightly differ from the one computed during training.
Training Accuracy Results
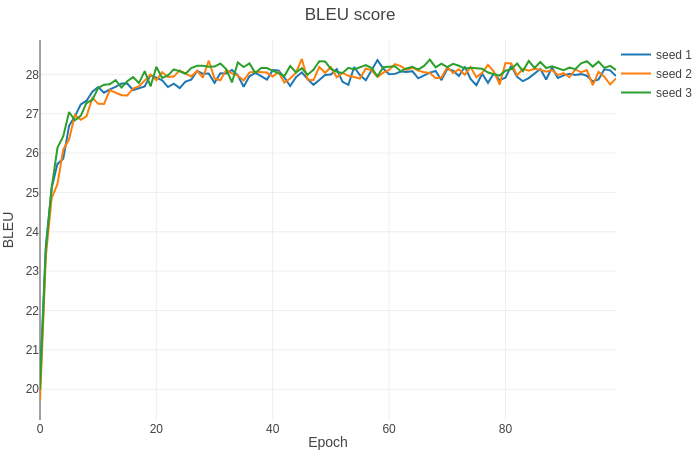
In order to test accuracy of our implementation we have run experiments with different seeds for 100 epochs with batch size 5120 per GPU and learining rate 6e-4 in the pytorch-19.03-py3 Docker container. Plot below shows BLEU score changes.
Training Performance Results
Running this code with the provided hyperparameters will allow you to achieve the following results. Our setup is a DGX-1 with 8x Tesla V100 16GB. We've verified our results after training 32 epochs to obtain multi-GPU and mixed precision scaling results.
| GPU count | Mixed precision BLEU | fp32 BLEU | Mixed precision training time | fp32 training time |
|---|---|---|---|---|
| 8 | 28.69 | 28.43 | 446 min | 1896 min |
| 4 | 28.35 | 28.31 | 834 min | 3733 min |
In some cases we can train further with the same setup to achieve slightly better results.
| GPU count | Precision | BLEU score | Epochs to train | Training time |
|---|---|---|---|---|
| 4 | fp16 | 28.67 | 74 | 1925 min |
| 4 | fp32 | 28.40 | 47 | 5478 min |
Results here are the best we achieved. We've observed a large variance in BLEU, while using random seed. Nearly all setups reach 28.4 BLEU, although the time it takes also varies between setups. We also observed a good rate of week scaling. We measured performance in tokens (words) per second.
| GPU count | Mixed precision | FP32 | FP32/Mixed speedup | Mixed precision week scaling | FP32 week scaling |
|---|---|---|---|---|---|
| 1 | 37650 | 8630 | 4.36 | 1.0 | 1.0 |
| 4 | 132700 | 30500 | 4.35 | 3.52 | 3.53 |
| 8 | 260000 | 61000 | 4.26 | 6.91 | 7.07 |
Inference performance results
All results were obtained by generate.py inference script in the pytorch-19.01-py3 Docker container. Inference was run on a single GPU.
| GPU | Mixed precision | FP32 | FP16/Mixed speedup |
|---|---|---|---|
| Tesla V100 | 5129.34 | 3396.09 | 1.51 |
Changelog
- initial commit, forked from fairseq
- adding mid-training SacreBLEU evaluation. Better handling of OOMs.
Known issues
- Course of a training heavily depends on a random seed. There is high variance in a time required to reach a certain BLEU score. Also the highest BLEU score value observed vary between runs with different seeds.