Bumps [pillow](https://github.com/python-pillow/Pillow) from 5.4.1 to 6.2.0. - [Release notes](https://github.com/python-pillow/Pillow/releases) - [Changelog](https://github.com/python-pillow/Pillow/blob/master/CHANGES.rst) - [Commits](https://github.com/python-pillow/Pillow/compare/5.4.1...6.2.0) Signed-off-by: dependabot[bot] <support@github.com> |
||
|---|---|---|
| .. | ||
| dllogger | ||
| examples | ||
| images | ||
| model | ||
| utils | ||
| .gitignore | ||
| Dockerfile | ||
| download_dataset.py | ||
| LICENSE | ||
| main.py | ||
| NOTICE | ||
| README.md | ||
| requirements.txt | ||
UNet Medical Image Segmentation for TensorFlow
This repository provides a script and recipe to train U-Net Medical to achieve state of the art accuracy, and is tested and maintained by NVIDIA.
Table of contents
Model overview
The U-Net model is a convolutional neural network for 2D image segmentation. This repository contains a U-Net implementation as described in the paper U-Net: Convolutional Networks for Biomedical Image Segmentation, without any alteration.
This model is trained with mixed precision using tensor cores on NVIDIA Volta GPUs. Therefore, researchers can get results much faster than training without Tensor Cores, while experiencing the benefits of mixed precision training (for example, up to 3.5x performance boost). This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
U-Net was first introduced by Olaf Ronneberger, Philip Fischer, and Thomas Brox in the paper: U-Net: Convolutional Networks for Biomedical Image Segmentation. U-Net allows for seamless segmentation of 2D images, with high accuracy and performance, and can be adapted to solve many different segmentation problems.
The following figure shows the construction of the UNet model and its different components. UNet is composed of a contractive and an expanding path, that aims at building a bottleneck in its centermost part through a combination of convolution and pooling operations. After this bottleneck, the image is reconstructed through a combination of convolutions and upsampling. Skip connections are added with the goal of helping the backward flow of gradients in order to improve the training.
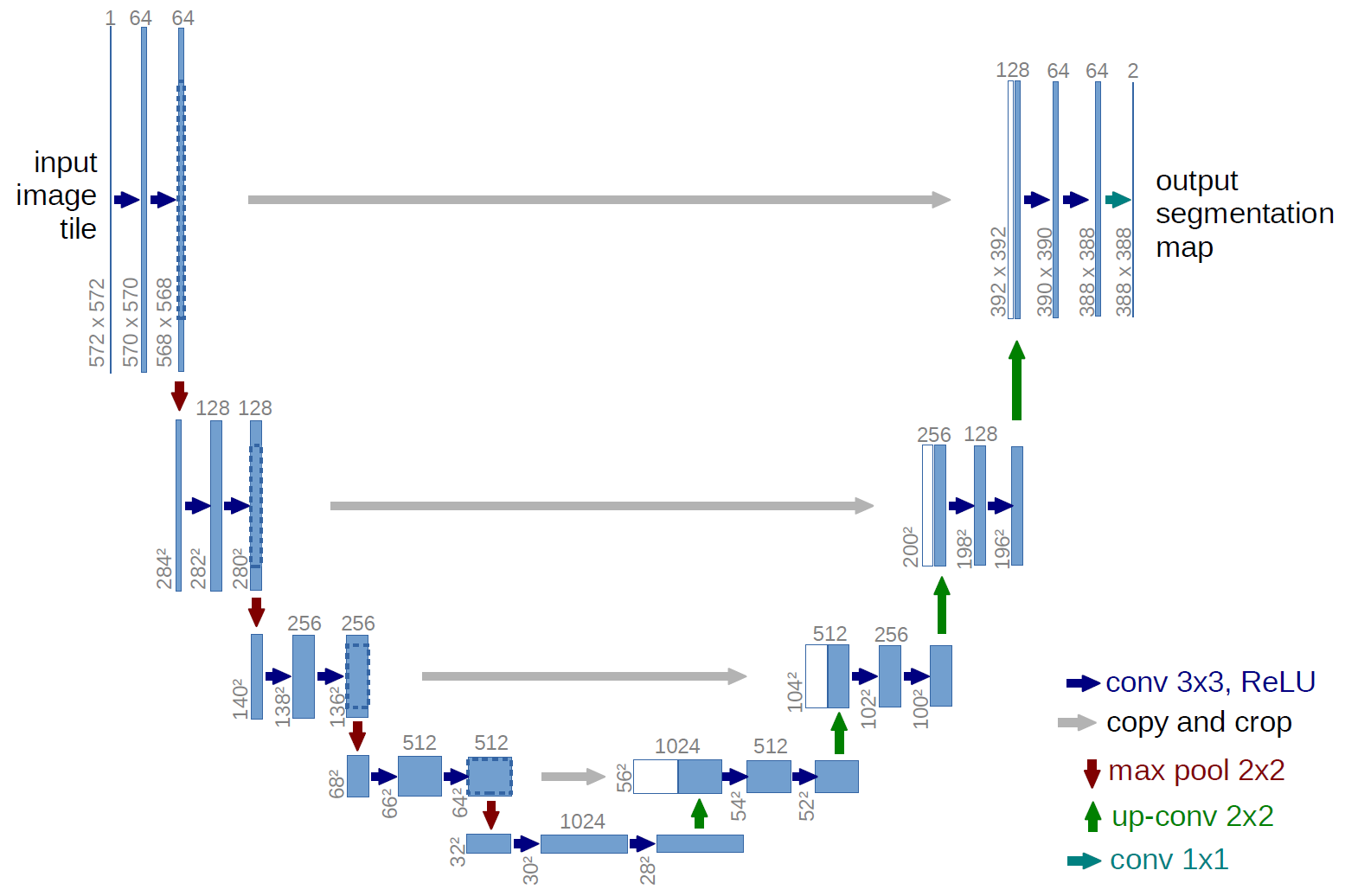
Default configuration
U-Net consists of a contractive (left-side) and expanding (right-side) path. It repeatedly applies unpadded convolutions followed by max pooling for downsampling. Every step in the expanding path consists of an upsampling of the feature maps and a concatenation with the correspondingly cropped feature map from the contractive path.
The following features were implemented in this model:
- Data-parallel multi-GPU training with Horovod.
- Mixed precision support with TensorFlow Automatic Mixed Precision (TF-AMP), which enables mixed precision training without any changes to the code-base by performing automatic graph rewrites and loss scaling controlled by an environmental variable.
- Tensor Core operations to maximize throughput using NVIDIA Volta GPUs.
- Static loss scaling for tensor cores (mixed precision) training.
The following performance optimizations were implemented in this model:
- XLA support (experimental). For TensorFlow, easily adding mixed-precision support is available from NVIDIA’s APEX, a TensorFlow extension that contains utility libraries, such as AMP, which require minimal network code changes to leverage tensor cores performance.
Feature support matrix
The following features are supported by this model.
| Feature | UNet_Medical_TF |
|---|---|
| Horovod Multi-GPU (NCCL) | Yes |
Features
Horovod - Horovod is a distributed training framework for TensorFlow, Keras, PyTorch and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of tensor cores in the Volta and Turing architecture, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
- APEX tools for mixed precision training, see the NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch.
Enabling mixed precision
In order to enable mixed precision training, the following environment variables must be defined with the correct value before the training starts:
TF_ENABLE_AUTO_MIXED_PRECISION=1
Exporting these variables ensures that loss scaling is performed correctly and automatically.
By supplying the --use_amp flag to the main.py script while training in FP32, the following variables are set to their correct value for mixed precision training inside the ./utils/runner.py script:
if params['use_amp']:
LOGGER.log("TF AMP is activated")
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
Setup
The following section lists the requirements in order to start training the U-Net model.
Requirements
This repository contains a Dockerfile which extends the TensorFlow NGC container and encapsulates some additional dependencies. Aside from these dependencies, ensure you have the following components:
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning DGX Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC container registry
- Running Tensorflow
Quick Start Guide
To train your model using mixed precision with tensor cores or using FP32, perform the following steps using the default parameters of the U-Net model on the EM segmentation challenge dataset.
Clone the repository
git clone https://github.com/NVIDIA/DeepLearningExamples
cd DeepLearningExamples/TensorFlow/Segmentation/UNet_Medical
Download and preprocess the dataset
The U-Net script main.py operates on data from the ISBI Challenge, the dataset originally employed in the U-Net paper. Upon registration, the challenge's data is made available through the following links:
The script download_dataset.py is provided for data download. It is possible to select the destination folder when downloading the files by using the --data_dir flag. For example:
python download_dataset.py --data_dir ./dataset
Training and test data are composed of 3 multi-page TIF files, each containing 30 2D-images. The training and test datasets are given as stacks of 30 2D-images provided as a multi-page TIF that can be read using the Pillow library and NumPy (both Python packages are installed by the Dockerfile):
From PIL import Image, ImageSequence
Import numpy as np
im = Image.open(path)
slices = [np.array(i) for i in ImageSequence.Iterator(im)]
Once downloaded the data using the download_dataset.py script, it can be used to run the training and benchmark scripts described below, by pointing main.py to its location using the --data_dir flag.
Note: Masks are only provided for training data.
Build the U-Net TensorFlow container
After Docker is correctly set up, the U-Net TensorFlow container can be built with:
user@~/Documents/unet_medical_tf # docker build -t unet_tf .
Start an interactive session in the NGC container to run training/inference.
Run the previously built Docker container:
user@~/path/to/unet_medical_tf # docker run --runtime=nvidia --rm -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -v /path/to/dataset:/data unet_tf:latest bash
Note: Ensure to mount your dataset using the -v flag to make it available for training inside the NVIDIA Docker container.
Start training
To run training for a default configuration (for example 1/8 GPUs FP32/TF-AMP), run one of the scripts in the ./examples directory, as follows:
bash examples/unet_{FP32, TF-AMP}_{1,8}.sh <path to main.py> <path to dataset> <path to results directory>
For example:
root@8e522945990f:/workspace/unet# bash examples/unet_FP32_1GPU.sh . /data results
Start inference/predictions
To run inference on a checkpointed model, run:
bash examples/unet_INFER_{FP32, TF-AMP}.sh <path to main.py> <path to dataset> <path to results directory>
For example:
root@8e522945990f:/workspace/unet# bash examples/unet_INFER_FP32.sh . /data results
Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
Scripts and sample code
In the root directory, the most important files are:
main.py: Serves as the entry point to the application.Dockerfile: Container with the basic set of dependencies to run UNetrequirements.txt: Set of extra requirements for running UNetdownload_data.py: Automatically downloads the dataset for training
The utils/ folder encapsulates the necessary tools to train and perform inference using UNet. Its main components are:
runner.py: Implements the logic for training and inferencedata_loader.py: Implements the data loading and augmentationhooks/profiler.py: Collects different metrics to be used for benchmarking and testingvar_storage.py: Helper functions for TF-AMP
The model/ folder contains information about the building blocks of UNet and the way they are assembled. Its contents are:
layers.py: Defines the different blocks that are used to assemble UNetunet.py: Defines the model architecture using the blocks from thelayers.pyscript
Other folders included in the root directory are:
dllogger/: Contains the utils for loggingexamples/: Provides examples for training and benchmarking UNetimages/: Contains a model diagram
Parameters
The complete list of the available parameters for the main.py script contains:
--exec_mode: Select the execution mode to run the model (default: train_and_predict)--model_dir: Set the output directory for information related to the model (default: result/)--data_dir: Set the input directory containing the dataset (defaut: None)--batch_size: Size of each minibatch per GPU (default: 1)--max_steps: Maximum number of steps (batches) for training (default: 1000)--seed: Set random seed for reproducibility (default: 0)--weight_decay: Weight decay coefficient (default: 0.0005)--log_every: Log performance every n steps (default: 100)--warmup_steps: Skip logging during the first n steps (default: 200)--learning_rate: Model’s learning rate (default: 0.01)--momentum: Momentum coefficient for model’s optimizer (default: 0.99)--decay_steps: Number of steps before learning rate decay (default: 5000)--decay_rate: Decay rate for polynomial learning rate decay (default 0.95)--augment: Enable data augmentation (default: False)--benchmark: Enable performance benchmarking (default: False)--use_amp: Enable automatic mixed precision (default: False)
Command line options
To see the full list of available options and their descriptions, use the -h or --help command line option, for example:
root@ac1c9afe0a0b:/workspace/unet# python main.py
usage: main.py [-h]
[--exec_mode {train,train_and_predict,predict,benchmark}]
[--model_dir MODEL_DIR]
--data_dir DATA_DIR
[--batch_size BATCH_SIZE]
[--max_steps MAX_STEPS]
[--seed SEED]
[--weight_decay WEIGHT_DECAY]
[--log_every LOG_EVERY]
[--warmup_steps WARMUP_STEPS]
[--learning_rate LEARNING_RATE]
[--momentum MOMENTUM]
[--decay_steps DECAY_STEPS]
[--decay_rate DECAY_RATE]
[--augment]
[--no-augment]
[--benchmark]
[--no-benchmark]
[--use_amp]
Getting the data
The U-Net model was trained in the EM segmentation challenge dataset. Test images provided by the organization were used to produce the resulting masks for submission.
Training and test data is comprised of three 512x512x30 TIF volumes (test-volume.tif, train-volume.tif and train-labels.tif). Files test-volume.tif and train-volume.tif contain grayscale 2D slices to be segmented. Additionally, training masks are provided in train-labels.tif as a 512x512x30 TIF volume, where each pixel has one of two classes:
- 0 indicating the presence of cellular membrane, and
- 1 corresponding to background.
The objective is to produce a set of masks that segment the data as accurately as possible. The results are expected to be submitted as a 32-bit TIF 3D image, which values between 0 (100% membrane certainty) and 1 (100% non-membrane certainty).
Dataset guidelines
The process of loading, normalizing and augmenting the data contained in the dataset can be found in the data_loader.py script.
Initially, data is loaded from a multi-page TIF file and converted to 512x512x30 NumPy arrays with the use of Pillow. These NumPy arrays are fed to the model through tf.data.Dataset.from_tensor_slices(), in order to achieve high performance.
Intensities on the volumes are then normalized to an interval [-1, 1], whereas labels are one-hot encoded for their later use in pixel wise cross entropy loss, becoming 512x512x30x2 tensors.
If augmentation is enabled, the following set of augmentation techniques are applied:
- Random horizontal flipping
- Random vertical flipping
- Elastic deformation through dense_image_warp
- Random rotation
- Crop to a random dimension and resize to input dimension
- Random brightness shifting
At the end, intensities are clipped to the [-1, 1] interval.
Training process
Optimizer
The model trains for 40,000 batches, with the default U-Net setup as specified in the original paper:
- SGD with momentum (0.99)
- Learning rate = 0.01
This default parametrization is employed when running scripts from the ./examples directory and when running main.py without explicitly overriding these fields.
- Augmentation
- During training, we perform the following augmentation techniques:
- Random flip left and right
- Random flip up and down
- Elastic deformation
- Random rotation
- Random crop and resize
- Random brightness changes
To run a pre-parameterized configuration (1 or 8 GPUs, FP32 or AMP), run one of the scripts in the ./examples directory, for example:
./examples/unet_{FP32, TF-AMP}_{1, 8}GPU.sh <path/to/main.py> <path/to/dataset> <path/to/checkpoints> <batch size>
Use -h or --help to obtain a list of available options in the main.py script.
Note: When calling the main.py script manually, data augmentation is disabled. In order to enable data augmentation, use the --augment flag at the end of your invocation.
Use the --model_dir flag to select the location where to store the artifacts of the training.
Inference process
To run inference on a checkpointed model, run the script below, although, it requires a pre-trained model checkpoint and tokenized input.
python main.py --data_dir /data --model_dir <path to checkpoint> --exec_mode predict
This script should produce the prediction results over a set of masks which will be located in <path to checkpoint>/eval.
Performance
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark training, run one of the scripts in ./examples/unet_TRAIN_BENCHMARK_{FP32, TF-AMP}_{1, 8}GPU.sh <path/to/main.py> <path/to/dataset> <path/to/checkpoints> <batch size>.
Each of these scripts will by default run 200 warm-up iterations and benchmark the performance during training in the next 100 iterations. To control warmup and benchmark length, use --warmup_steps, and --max_steps flags.
Inference performance benchmark
To benchmark inference, run one of the scripts in ./examples/unet_INFER_BENCHMARK_{FP32, TF-AMP}.sh <path/to/main.py> <path/to/dataset> <path/to/checkpoints> <batch size>.
Each of these scripts will by default run 200 warmup iterations and benchmark the performance during inference in the next 100 iterations. To control warmup and benchmark length, use --warmup_steps, and --max_steps flags.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
NVIDIA DGX-1 (8x V100 16G)
Our results were obtained by running the ./examples/unet_{FP32, TF-AMP}_{1, 8}GPU.sh scripts in the tensorflow:19.06-py3 NGC container on NVIDIA DGX-1 with 8x V100 16G GPUs.
Metrics employed by the organization are explained in detail here.
The results described below were obtained after the submission of our evaluations to the ISBI Challenge organizers.
| Number og GPUs | FP32 Rand Score Thin | FP32 Information Score Thin | TF-AMP Rand Score Thin | TF-AMP Information Score Thin | Total time to train with FP16 (Hrs) | Total time to train with FP32 (Hrs) |
|---|---|---|---|---|---|---|
| 1 | 0.938508265 | 0.970255682 | 0.939619101 | 0.970120138 | 7.1 | 11.28 |
| 8 | 0.932395087 | 0.9786346 | 0.941360867 | 0.976235311 | 0.9 | 1.41 |
Training performance results
NVIDIA DGX-1 (1x V100 16G)
Our results were obtained by running the ./examples/unet_TRAIN_BENCHMARK_{FP32, TF-AMP}_1GPU.sh scripts in
the tensorflow:19.06-py3 NGC container on NVIDIA DGX-1 with 1x V100 16G GPU while data augmentation is enabled.
| Batch size | FP32 max img/s | TF-AMP max img/s | Speedup factor |
|---|---|---|---|
| 1 | 12.37 | 21.91 | 1.77 |
| 8 | 13.81 | 29.58 | 2.14 |
| 16 | Out of memory | 30.77 | - |
To achieve these same results, follow the Quick start guide outlined above.
NVIDIA DGX-1 (8x V100 16G)
Our results were obtained by running the ./examples/unet_TRAIN_BENCHMARK_{FP32, TF-AMP}_8GPU.sh scripts in
the tensorflow:19.06-py3 NGC container on NVIDIA DGX-1 with 8x V100 16G GPU while data augmentation is enabled.
| Batch size per GPU | FP32 max img/s | TF-AMP max img/s | Speedup factor |
|---|---|---|---|
| 1 | 89.93 | 126.66 | 1.41 |
| 8 | 105.35 | 130.66 | 1.24 |
| 16 | Out of memory | 132.78 | - |
To achieve these same results, follow the Quick start guide outlined above.
Inference performance results
NVIDIA DGX-1 (1x V100 16G)
Our results were obtained by running the ./examples/unet_INFER_BENCHMARK_{FP32, TF-AMP}.sh scripts in
the tensorflow:19.06-py3 NGC container on NVIDIA DGX-1 with 1x V100 16G GPU while data augmentation is enabled.
| Batch size | FP32 img/s | TF-AMP img/s | Speedup factor |
|---|---|---|---|
| 1 | 34.27 | 62.81 | 1.83 |
| 8 | 37.09 | 79.62 | 2.14 |
| 16 | Out of memory | 83.33 | - |
To achieve these same results, follow the Quick start guide outlined above.
Release notes
Changelog
July 2019
- Added inference example scripts
- Added inference benchmark measuring latency
- Added TRT/TF-TRT support
- Updated Pre-trained model on NGC registry
June 2019
- Updated README template
May 2019
- Initial release
Known issues
There are no known issues in this release.