| .. | ||
| img | ||
| scripts | ||
| utils | ||
| variable_mgr | ||
| .dockerignore | ||
| .gitignore | ||
| attention_wrapper.py | ||
| beam_search_decoder.py | ||
| benchmark_hooks.py | ||
| block_lstm.py | ||
| Dockerfile | ||
| estimator.py | ||
| gnmt_model.py | ||
| model.py | ||
| model_helper.py | ||
| nmt.py | ||
| NOTICE | ||
| README.md | ||
| requirements.txt | ||
GNMT v2 For TensorFlow
This repository provides a script and recipe to train GNMT v2 to achieve state of the art accuracy, and is tested and maintained by NVIDIA.
Table Of Contents
The model
The GNMT v2 model is similar to the one discussed in the Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation paper.
The most important difference between the two models is in the attention mechanism. In our model, the output from the first LSTM layer of the decoder goes into the attention module, then the re-weighted context is concatenated with inputs to all subsequent LSTM layers in the decoder at the current timestep.
The same attention mechanism is also implemented in the default GNMT-like models from TensorFlow Neural Machine Translation Tutorial and NVIDIA OpenSeq2Seq Toolkit.
Default configuration
The following features were implemented in this model:
- general:
- encoder and decoder are using shared embeddings
- data-parallel multi-gpu training
- dynamic loss scaling with backoff for Tensor Cores (mixed precision) training
- trained with label smoothing loss (smoothing factor 0.1)
- encoder:
- 4-layer LSTM, hidden size 1024, first layer is bidirectional, the rest are unidirectional
- with residual connections starting from 3rd layer
- dropout is applied on input to all LSTM layers, probability of dropout is set to 0.2
- hidden state of LSTM layers is initialized with zeros
- weights and bias of LSTM layers is initialized with uniform(-0.1, 0.1) distribution
- decoder:
- 4-layer unidirectional LSTM with hidden size 1024 and fully-connected classifier
- with residual connections starting from 3rd layer
- dropout is applied on input to all LSTM layers, probability of dropout is set to 0.2
- hidden state of LSTM layers is initialized with the last hidden state from encoder
- weights and bias of LSTM layers is initialized with uniform(-0.1, 0.1) distribution
- weights and bias of fully-connected classifier is initialized with uniform(-0.1, 0.1) distribution
- attention:
- normalized Bahdanau attention
- output from first LSTM layer of decoder goes into attention, then re-weighted context is concatenated with the input to all subsequent LSTM layers of the decoder at the current timestep
- linear transform of keys and queries is initialized with uniform(-0.1, 0.1), normalization scalar is initialized with 1.0 / sqrt(1024), normalization bias is initialized with zero
- inference:
- beam search with default beam size of 5
- with coverage penalty and length normalization, coverage penalty factor is set to 0.1, length normalization factor is set to 0.6 and length normalization constant is set to 5.0
- de-tokenized BLEU computed by SacreBLEU
- motivation for choosing SacreBLEU
When comparing the BLEU score, there are various tokenization approaches and BLEU calculation methodologies; therefore, ensure you align similar metrics.
Code from this repository can be used to train a larger, 8-layer GNMT v2 model.
Our experiments show that a 4-layer model is significantly faster to train and
yields comparable accuracy on the public
WMT16 English-German
dataset. The number of LSTM layers is controlled by the --num_layers parameter
in the nmt.py script.
Setup
The following section list the requirements in order to start training the GNMT v2 model.
Requirements
This repository contains Dockerfile which extends the TensorFlow NGC container
and encapsulates some dependencies. Aside from these dependencies, ensure you
have the following components:
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning DGX Documentation:
- Getting Started Using NVIDIA GPU Cloud,
- Accessing And Pulling From The NGC container registry,
- Running TensorFlow.
Quick Start Guide
To train your model using mixed precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the GNMT v2 model on the WMT16 English German dataset.
1. Clone the repository.
git clone https://github.com/NVIDIA/DeepLearningExamples
cd DeepLearningExamples/TensorFlow/Translation/GNMT
2. Build the GNMT v2 container.
bash scripts/docker/build.sh
3. Start an interactive session in the container to run training/inference.
bash scripts/docker/interactive.sh
4. Download and preprocess the dataset.
Data will be downloaded to the data directory (on the host). The data
directory is mounted to the /workspace/gnmt/data location in the Docker
container.
bash scripts/wmt16_en_de.sh
5. Start training.
All results and logs are saved to the results directory (on the host) or to
the /workspace/gnmt/results directory (in the container). The training script
saves checkpoint after every training epoch and after every 2000 training steps
within each epoch. You can modify the results directory using --output_dir
argument.
To launch mixed precision training on 1 GPU, run:
python nmt.py --output_dir=results --batch_size=192 --learning_rate=8e-4
To launch mixed precision training on 8 GPUs, run:
python nmt.py --output_dir=results --batch_size=1536 --num_gpus=8 --learning_rate=2e-3
To launch FP32 training on 1 GPU, run:
python nmt.py --output_dir=results --batch_size=128 --learning_rate=5e-4 --use_amp=false
To launch FP32 training on 8 GPUs, run:
python nmt.py --output_dir=results --batch_size=1024 --num_gpus=8 --learning_rate=2e-3 --use_amp=false
6. Start evaluation.
The training process automatically runs evaluation and outputs the BLEU score after each training epoch. Additionally, after the training is done, you can manually run inference on test dataset with the checkpoint saved during the training.
To launch mixed precision inference on 1 GPU, run:
python nmt.py --output_dir=results --infer_batch_size=128 --mode=infer
To launch FP32 inference on 1 GPU, run:
python nmt.py --output_dir=results --infer_batch_size=128 --use_amp=false --mode=infer
Details
The following sections provide greater details of the dataset, running training and inference, and the training results.
Command line arguments
To see the full list of available options and their descriptions, use the -h
or --help command line option, for example:
python nmt.py --help
To summarize, the most useful arguments are as follows:
--learning_rate LEARNING_RATE
Learning rate.
--max_train_epochs MAX_TRAIN_EPOCHS
Max number of epochs.
--data_dir DATA_DIR Training/eval data directory.
--output_dir OUTPUT_DIR
Store log/model files.
--batch_size BATCH_SIZE
Total batch size.
--log_step_count_steps LOG_STEP_COUNT_STEPS
The frequency, in number of global steps, that the
global step and the loss will be logged during training
--num_gpus NUM_GPUS Number of gpus in each worker.
--random_seed RANDOM_SEED
Random seed (>0, set a specific seed).
--ckpt CKPT Checkpoint file to load a model for inference.
(defaults to newest checkpoint)
--infer_batch_size INFER_BATCH_SIZE
Batch size for inference mode.
--beam_width BEAM_WIDTH
beam width when using beam search decoder. If 0,
use standard decoder with greedy helper.
--use_amp USE_AMP use_amp for training and inference
--mode {train_and_eval,infer}
Getting the data
The GNMT v2 model was trained on the WMT16 English-German dataset and newstest2014 is used as a testing dataset.
This repository contains the scripts/wmt16_en_de.sh download script which
automatically downloads and preprocesses the training and test datasets. By
default, data is downloaded to the data directory.
Our download script is very similar to the wmt16_en_de.sh script from the
tensorflow/nmt
repository. Our download script contains an extra preprocessing step, which
discards all pairs of sentences which can't be decoded by latin-1 encoder.
The scripts/wmt16_en_de.sh script uses the
subword-nmt
package to segment text into subword units (Byte Pair Encodings - BPE). By default, the script builds
the shared vocabulary of 32,000 tokens.
In order to test with other datasets, scripts need to be customized accordingly.
Training process
The training configuration can be launched by running the nmt.py script.
By default, the training script saves the checkpoint after every training epoch
and after every 2000 training steps within each epoch.
Results are stored in the results directory.
The training script launches data-parallel training on multiple GPUs. We have tested reliance on up to 8 GPUs on a single node.
After each training epoch, the script runs an evaluation and outputs a BLEU
score on the test dataset (newstest2014). BLEU is computed by the
SacreBLEU
package. Logs from the training and evaluation are saved to the results
directory.
The training script automatically runs testing after each training epoch. The results from the testing are printed to the standard output and saved to the log files.
The summary after each training epoch is printed in the following format:
training time for epoch 1: 29.37 mins (2918.36 sent/sec, 139640.48 tokens/sec)
[...]
bleu is 20.50000
eval time for epoch 1: 1.57 mins (78.48 sent/sec, 4283.88 tokens/sec)
The BLEU score is computed on the test dataset. Performance is reported in total sentences per second and in total tokens per second. The performance result is averaged over an entire training epoch and summed over all GPUs participating in the training.
To view all available options for training, run python nmt.py --help.
Enabling mixed precision
Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of tensor cores in the Volta and Turing architectures, significant training speedups are experienced by switching to mixed precision - up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Manually adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta and Turing GPUs automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as
necessary and maximize the use of FP16, and the loss scaling is automatically
applied inside of supported optimizers. AMP can be configured to work with the
existing tf.contrib loss scaling manager by disabling the AMP scaling with a
single environment variable to perform only the automatic mixed-precision
optimization. It accomplishes this by automatically rewriting all computation
graphs with the necessary operations to enable mixed precision training and
automatic loss scaling.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
Inference process
Inference can be run by launching the nmt.py script, although, it requires a
pre-trained model checkpoint and tokenized input.
The script, nmt.py, supports batched inference (--mode=infer flag). By
default, it launches beam search with beam size of 5, coverage penalty term and
length normalization term. Greedy decoding can be enabled by setting the
--beam_width=1 flag for the nmt.py inference script. To control the
batch size use the --infer_batch_size flag.
To view all available options for inference, run python nmt.py --help.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Our results were obtained by running the nmt.py script in the
tensorflow-19.03-py3 NGC container on NVIDIA DGX-1 with 8x V100 16G GPUs.
Commands to launch the training:
for 1 GPUs in mixed precision:
python nmt.py --output_dir=results --batch_size=192 --learning_rate=8e-4
for 8 GPUs in mixed precision:
python nmt.py --output_dir=results --batch_size=1536 --num_gpus=8 --learning_rate=2e-3
for 1 GPUs in FP32:
python nmt.py --output_dir=results --batch_size=128 --learning_rate=5e-4 --use_amp=false
for 8 GPUs in FP32:
python nmt.py --output_dir=results --batch_size=1024 --num_gpus=8 --learning_rate=2e-3 --use_amp=false
| Number of GPUs | Mixed precision batch size/GPU | FP32 batch size/GPU | Mixed precision BLEU | FP32 BLEU | Mixed precision training time | FP32 training time |
|---|---|---|---|---|---|---|
| 1 | 192 | 128 | 24.58 | 24.64 | 789 min | 1375 min |
| 8 | 192 | 128 | 24.46 | 24.51 | 184 min | 262 min |
In the following plot, the BLEU scores after each training epoch for different configurations are displayed.
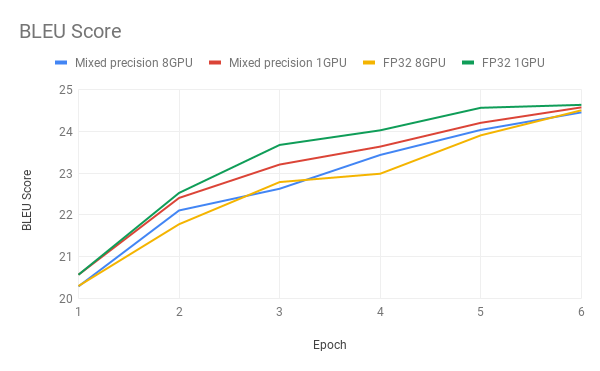
Training stability test
The GNMT v2 model was trained for 6 epochs, starting from 6 different initial random seeds. After each training epoch, the model was evaluated on the test dataset and the BLEU score was recorded. The training was performed in the tensorflow-19.03-py3 NGC container on NVIDIA DGX-1 with 8 Tesla V100 16G GPUs.
In the following table, the BLEU scores after each training epoch for different initial random seeds are displayed.
| Epoch | Average | Standard deviation | Minimum | Maximum | Median |
|---|---|---|---|---|---|
| 1 | 19.943 | 0.240 | 19.670 | 20.290 | 19.855 |
| 2 | 21.750 | 0.197 | 21.550 | 22.110 | 21.690 |
| 3 | 22.408 | 0.150 | 22.160 | 22.630 | 22.430 |
| 4 | 23.057 | 0.219 | 22.770 | 23.440 | 22.985 |
| 5 | 23.897 | 0.142 | 23.700 | 24.080 | 23.915 |
| 6 | 24.243 | 0.174 | 24.030 | 24.460 | 24.235 |
Training performance results
Our results were obtained by running the nmt.py script in the
tensorflow-19.03-py3 NGC container on NVIDIA DGX-1 with 8x V100 16G GPUs.
Performance numbers (in tokens per second) were averaged over an entire
training epoch.
| Number of GPUs | Mixed precision batch size/GPU | FP32 batch size/GPU | Mixed precision tokens/s | FP32 tokens/s | Mixed precision speedup | Mixed precision multi-gpu weak scaling | FP32 multi-gpu weak scaling |
|---|---|---|---|---|---|---|---|
| 1 | 192 | 128 | 22 297 | 12 767 | 1.74 | 1.00 | 1.00 |
| 8 | 192 | 128 | 133 992 | 83 337 | 1.61 | 6.01 | 6.53 |
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance results
Our results were obtained by running the scripts/translate.py script in the
tensorflow-19.03-py3 NGC container on NVIDIA DGX-1 with a single V100 16G GPUs.
The benchmark requires a checkpoint from a fully trained model.
To launch the inference benchmark in mixed precision on 1 GPU, run:
python scripts/inference_benchmark.py --output_dir=/path/to/trained/model --beam_width 1,2,5,10 --infer_batch_size 32,128,512
To launch the inference benchmark in FP32 on 1 GPU, run:
python scripts/inference_benchmark.py --output_dir=/path/to/trained/model --beam_width 1,2,5,10 --infer_batch_size 32,128,512 --use_amp=false
| Batch size | Beam size | Mixed precision BLEU | FP32 BLEU | Mixed precision tokens/s | FP32 tokens/s |
|---|---|---|---|---|---|
| 32 | 1 | 23.43 | 23.47 | 8180 | 7555 |
| 32 | 2 | 24.14 | 24.13 | 6870 | 6359 |
| 32 | 5 | 24.43 | 24.47 | 4729 | 3991 |
| 32 | 10 | 24.29 | 24.29 | 2344 | 2495 |
| 128 | 1 | 23.43 | 23.47 | 19343 | 14810 |
| 128 | 2 | 24.15 | 24.13 | 10267 | 9956 |
| 128 | 5 | 24.45 | 24.47 | 7009 | 5224 |
| 128 | 10 | 24.30 | 24.29 | 3873 | 2855 |
| 512 | 1 | 23.45 | 23.47 | 32325 | 20782 |
| 512 | 2 | 24.17 | 24.13 | 18917 | 13702 |
| 512 | 5 | 24.46 | 24.47 | 8789 | 6036 |
| 512 | 10 | 24.29 | 24.29 | 4684 | 3149 |
To achieve these same results, follow the Quick Start Guide outlined above.
Changelog
- Mar 18, 2019
- Initial release
Known issues
There are no known issues in this release.