* Removed text keywords from filters in SDE (to support as values) Signed-off-by: Vitaly Lavrukhin <vlavrukhin@nvidia.com> * Added signal metrics to SDE Added SDE histograms for all numeric attributes Improved SDE UI Signed-off-by: Vitaly Lavrukhin <vlavrukhin@nvidia.com> * Updated code style Signed-off-by: Vitaly Lavrukhin <vlavrukhin@nvidia.com> * Updated SDE requirements Signed-off-by: Vitaly Lavrukhin <vlavrukhin@nvidia.com> * Updated docs (SDE + minor fixes) Signed-off-by: Vitaly Lavrukhin <vlavrukhin@nvidia.com> * Updated docs Signed-off-by: Vitaly Lavrukhin <vlavrukhin@nvidia.com> |
||
|---|---|---|
| .. | ||
| data_explorer.py | ||
| README.md | ||
| requirements.txt | ||
| screenshot.png | ||
{kind=link}
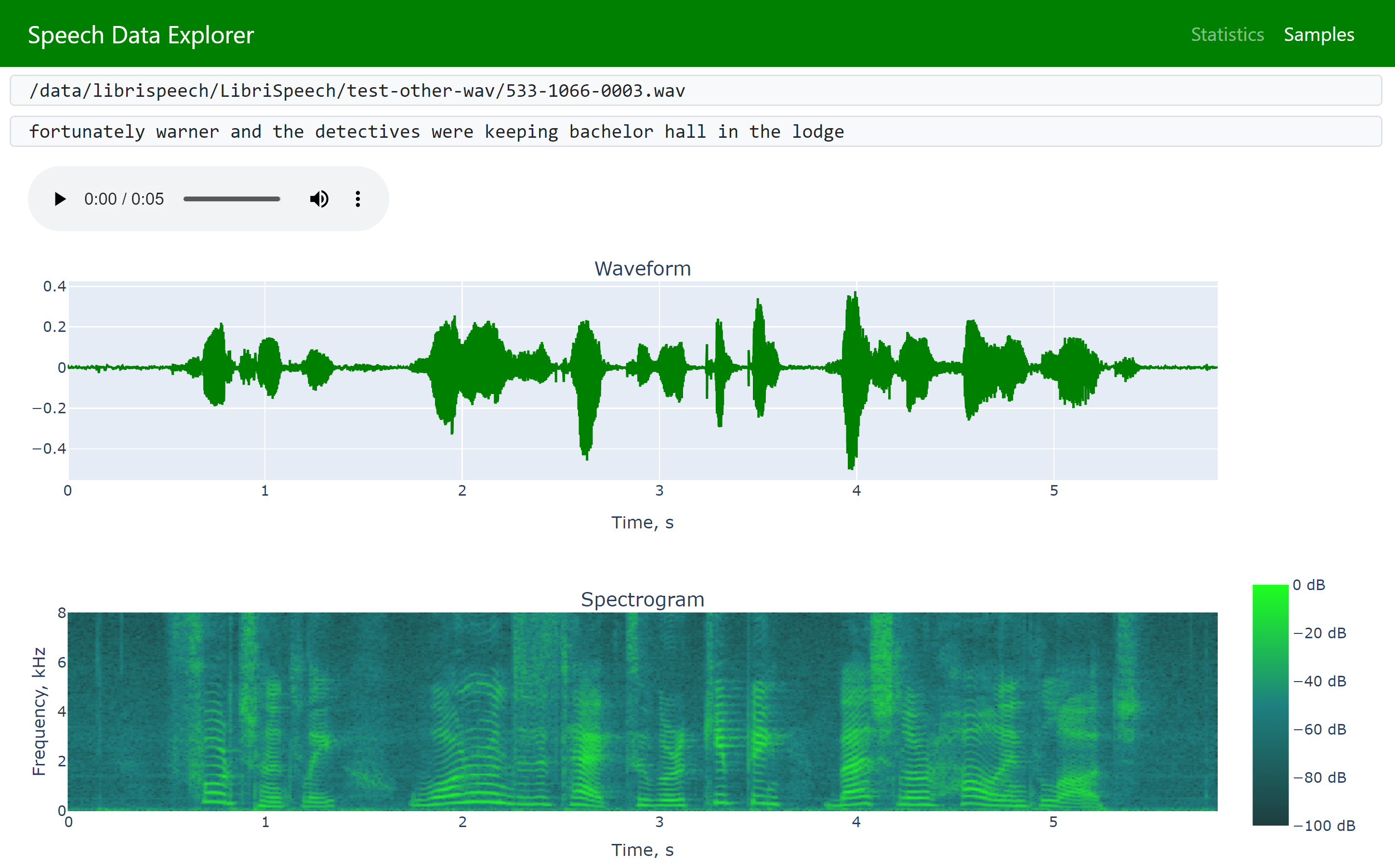
Speech Data Explorer
Dash-based tool for interactive exploration of ASR/TTS datasets.
Features:
- dataset's statistics (alphabet, vocabulary, duration-based histograms)
- navigation across dataset (sorting, filtering)
- inspection of individual utterances (waveform, spectrogram, audio player)
- errors' analysis (Word Error Rate, Character Error Rate, Word Match Rate, Mean Word Accuracy, diff)
Please make sure that requirements are installed. Then run:
python data_explorer.py path_to_manifest.json
JSON manifest file should contain the following fields:
- "audio_filepath" (path to audio file)
- "duration" (duration of the audio file in seconds)
- "text" (reference transcript)
Errors' analysis requires "pred_text" (ASR transcript) for all utterances.
Any additional field will be parsed and displayed in 'Samples' tab.