Update hadoop docs to indicate new committers (#8060)
This commit is contained in:
parent
f45977d371
commit
20b907d8fb
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
|
||||
|
||||
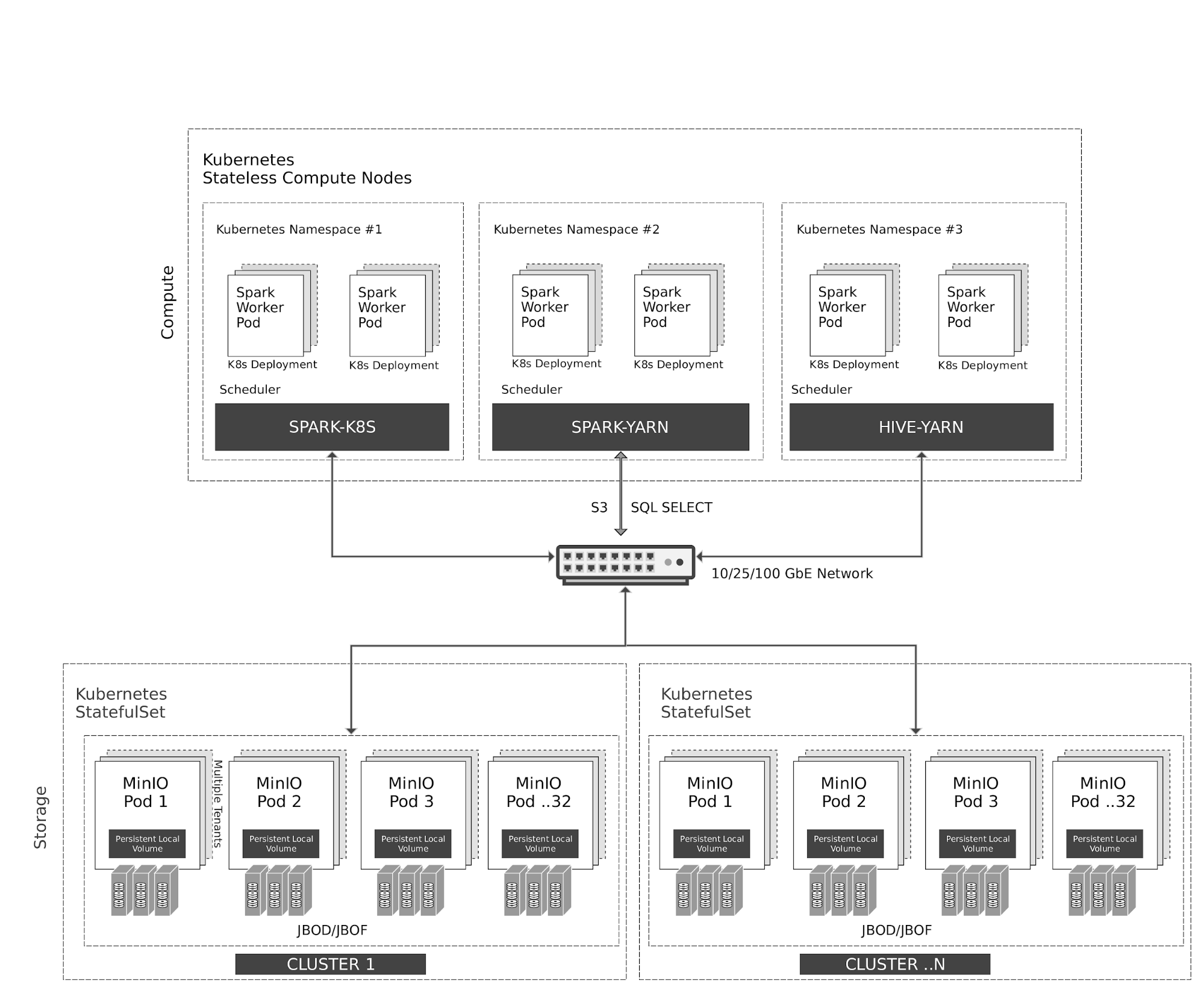
Kubernetes manages stateless Spark and Hive containers elastically on the compute nodes. Spark has native scheduler integration with Kubernetes. Hive, for legacy reasons, uses YARN scheduler on top of Kubernetes.
|
||||
Kubernetes manages stateless Spark and Hive containers elastically on the compute nodes. Spark has native scheduler integration with Kubernetes. Hive, for legacy reasons, uses YARN scheduler on top of Kubernetes.
|
||||
|
||||
All access to MinIO object storage is via S3/SQL SELECT API. In addition to the compute nodes, MinIO containers are also managed by Kubernetes as stateful containers with local storage (JBOD/JBOF) mapped as persistent local volumes. This architecture enables multi-tenant MinIO, allowing isolation of data between customers.
|
||||
|
||||
|
|
@ -35,27 +35,63 @@ Navigate to **Custom core-site** to configure MinIO parameters for `_s3a_` conne
|
|||
|
||||

|
||||
|
||||
Add the following optimal entries for _core-site.xml_ to configure _s3a_ with **MinIO**. Most important options here are
|
||||
```
|
||||
sudo pip install yq
|
||||
alias kv-pairify='xq ".configuration[]" | jq ".[]" | jq -r ".name + \"=\" + .value"'
|
||||
```
|
||||
|
||||
* _fs.s3a.access.key=minio_ (Access Key to access MinIO instance, this is obtained after the deployment on k8s)
|
||||
* _fs.s3a.secret.key=minio123_ (Secret Key to access MinIO instance, this is obtained after the deployment on k8s)
|
||||
* _fs.s3a.endpoint=`http://minio-address/`_
|
||||
* _fs.s3a.multipart.size=128M_
|
||||
* _fs.s3a.fast.upload=true_
|
||||
* _fs.s3a.fast.upload.buffer=bytebuffer_
|
||||
* _fs.s3a.path.style.access=true_
|
||||
* _fs.s3a.block.size=256M_
|
||||
* _fs.s3a.commiter.name=magic_
|
||||
* _fs.s3a.committer.magic.enabled=true_
|
||||
* _fs.s3a.committer.threads=16_
|
||||
* _fs.s3a.connection.maximum=32_
|
||||
* _fs.s3a.fast.upload.active.blocks=8_
|
||||
* _fs.s3a.max.total.tasks=16_
|
||||
* _fs.s3a.threads.core=32_
|
||||
* _fs.s3a.threads.max=32_
|
||||
* _mapreduce.outputcommitter.factory.scheme.s3a=org.apache.hadoop.fs.s3a.commit.S3ACommitterFactory_
|
||||
Let's take for example a set of 12 compute nodes with an aggregate memory of *1.2TiB*, we need to do following settings for optimal results. Add the following optimal entries for _core-site.xml_ to configure _s3a_ with **MinIO**. Most important options here are
|
||||
|
||||

|
||||
```
|
||||
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "mapred"
|
||||
|
||||
mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs
|
||||
mapred.maxthreads.partition.closer=0 # Asynchronous map flushers
|
||||
mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version
|
||||
mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce
|
||||
mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM
|
||||
mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM
|
||||
mapreduce.reduce.speculative=false # Disable speculation for reducing
|
||||
mapreduce.task.io.sort.factor=999 # Threshold before writing to disk
|
||||
mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to disk
|
||||
```
|
||||
|
||||
S3A is the connector to use S3 and other S3-compatible object stores such as MinIO. MapReduce workloads typically interact with object stores in the same way they do with HDFS. These workloads rely on HDFS atomic rename functionality to complete writing data to the datastore. Object storage operations are atomic by nature and they do not require/implement rename API. The default S3A committer emulates renames through copy and delete APIs. This interaction pattern causes significant loss of performance because of the write amplification. *Netflix*, for example, developed two new staging committers - the Directory staging committer and the Partitioned staging committer - to take full advantage of native object storage operations. These committers do not require rename operation. The two staging committers were evaluated, along with another new addition called the Magic committer for benchmarking.
|
||||
|
||||
It was found that the directory staging committer was the fastest among the three, S3A connector should be configured with the following parameters for optimal results:
|
||||
|
||||
```
|
||||
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "s3a"
|
||||
|
||||
fs.s3a.access.key=minio
|
||||
fs.s3a.secret.key=minio123
|
||||
fs.s3a.path.style.access=true
|
||||
fs.s3a.block.size=512M
|
||||
fs.s3a.buffer.dir=${hadoop.tmp.dir}/s3a
|
||||
fs.s3a.committer.magic.enabled=false
|
||||
fs.s3a.committer.name=directory
|
||||
fs.s3a.committer.staging.abort.pending.uploads=true
|
||||
fs.s3a.committer.staging.conflict-mode=append
|
||||
fs.s3a.committer.staging.tmp.path=/tmp/staging
|
||||
fs.s3a.committer.staging.unique-filenames=true
|
||||
fs.s3a.connection.establish.timeout=5000
|
||||
fs.s3a.connection.ssl.enabled=false
|
||||
fs.s3a.connection.timeout=200000
|
||||
fs.s3a.endpoint=http://minio:9000
|
||||
fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
|
||||
|
||||
fs.s3a.committer.threads=2048 # Number of threads writing to MinIO
|
||||
fs.s3a.connection.maximum=8192 # Maximum number of concurrent conns
|
||||
fs.s3a.fast.upload.active.blocks=2048 # Number of parallel uploads
|
||||
fs.s3a.fast.upload.buffer=disk # Use disk as the buffer for uploads
|
||||
fs.s3a.fast.upload=true # Turn on fast upload mode
|
||||
fs.s3a.max.total.tasks=2048 # Maximum number of parallel tasks
|
||||
fs.s3a.multipart.size=512M # Size of each multipart chunk
|
||||
fs.s3a.multipart.threshold=512M # Size before using multipart uploads
|
||||
fs.s3a.socket.recv.buffer=65536 # Read socket buffer hint
|
||||
fs.s3a.socket.send.buffer=65536 # Write socket buffer hint
|
||||
fs.s3a.threads.max=2048 # Maximum number of threads for S3A
|
||||
```
|
||||
|
||||
The rest of the other optimization options are discussed in the links below
|
||||
|
||||
|
|
@ -78,13 +114,35 @@ Navigate to “**Custom spark-defaults**” to configure MinIO parameters for `_
|
|||
|
||||
Add the following optimal entries for _spark-defaults.conf_ to configure Spark with **MinIO**.
|
||||
|
||||
* _spark.hadoop.fs.s3a.committer.magic.enabled=true_
|
||||
* _spark.hadoop.fs.s3a.committer.name=magic_
|
||||
* _spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem_
|
||||
* _spark.hadoop.fs.s3a.path.style.access=true_
|
||||
* _spark.hadoop.mapreduce.outputcommitter.factory.scheme.s3a=org.apache.hadoop.fs.s3a.commit.S3ACommitterFactory_
|
||||
|
||||

|
||||
```
|
||||
spark.hadoop.fs.s3a.access.key minio
|
||||
spark.hadoop.fs.s3a.secret.key minio123
|
||||
spark.hadoop.fs.s3a.path.style.access true
|
||||
spark.hadoop.fs.s3a.block.size 512M
|
||||
spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a
|
||||
spark.hadoop.fs.s3a.committer.magic.enabled false
|
||||
spark.hadoop.fs.s3a.committer.name directory
|
||||
spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true
|
||||
spark.hadoop.fs.s3a.committer.staging.conflict-mode append
|
||||
spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging
|
||||
spark.hadoop.fs.s3a.committer.staging.unique-filenames true
|
||||
spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO
|
||||
spark.hadoop.fs.s3a.connection.establish.timeout 5000
|
||||
spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns
|
||||
spark.hadoop.fs.s3a.connection.ssl.enabled false
|
||||
spark.hadoop.fs.s3a.connection.timeout 200000
|
||||
spark.hadoop.fs.s3a.endpoint http://minio:9000
|
||||
spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads
|
||||
spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads
|
||||
spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode
|
||||
spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem
|
||||
spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks
|
||||
spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk
|
||||
spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads
|
||||
spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint
|
||||
spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint
|
||||
spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A
|
||||
```
|
||||
|
||||
Once the config changes are applied, proceed to restart **Spark** services.
|
||||
|
||||
|
|
@ -102,12 +160,14 @@ Navigate to “**Custom hive-site**” to configure MinIO parameters for `_s3a_`
|
|||
|
||||
Add the following optimal entries for `hive-site.xml` to configure Hive with **MinIO**.
|
||||
|
||||
* _hive.blobstore.use.blobstore.as.scratchdir=true_
|
||||
* _hive.exec.input.listing.max.threads=50_
|
||||
* _hive.load.dynamic.partitions.thread=25_
|
||||
* _hive.metastore.fshandler.threads=50_
|
||||
* _hive.mv.files.threads=40_
|
||||
* _mapreduce.input.fileinputformat.list-status.num-threads=50_
|
||||
```
|
||||
hive.blobstore.use.blobstore.as.scratchdir=true
|
||||
hive.exec.input.listing.max.threads=50
|
||||
hive.load.dynamic.partitions.thread=25
|
||||
hive.metastore.fshandler.threads=50
|
||||
hive.mv.files.threads=40
|
||||
mapreduce.input.fileinputformat.list-status.num-threads=50
|
||||
```
|
||||
|
||||
For more information about these options please visit [https://www.cloudera.com/documentation/enterprise/5-11-x/topics/admin_hive_on_s3_tuning.html](https://www.cloudera.com/documentation/enterprise/5-11-x/topics/admin_hive_on_s3_tuning.html)
|
||||
|
||||
|
|
|
|||
Loading…
Reference in a new issue