20 KiB
Vendored
go-json
![]()

![]()
Fast JSON encoder/decoder compatible with encoding/json for Go

Roadmap
* version ( expected release date )
* v0.7.0
|
| while maintaining compatibility with encoding/json, we will add convenient APIs
|
v
* v1.0.0
We are accepting requests for features that will be implemented between v0.7.0 and v.1.0.0.
If you have the API you need, please submit your issue here.
For example, I'm thinking of supporting context.Context of json.Marshaler and decoding using JSON Path.
Features
- Drop-in replacement of
encoding/json - Fast ( See Benchmark section )
- Flexible customization with options
- Coloring the encoded string
- Can propagate context.Context to
MarshalJSONorUnmarshalJSON
Installation
go get github.com/goccy/go-json
How to use
Replace import statement from encoding/json to github.com/goccy/go-json
-import "encoding/json"
+import "github.com/goccy/go-json"
JSON library comparison
| name | encoder | decoder | compatible with encoding/json |
|---|---|---|---|
| encoding/json | yes | yes | N/A |
| json-iterator/go | yes | yes | partial |
| easyjson | yes | yes | no |
| gojay | yes | yes | no |
| segmentio/encoding/json | yes | yes | partial |
| jettison | yes | no | no |
| simdjson-go | no | yes | no |
| goccy/go-json | yes | yes | yes |
json-iterator/goisn't compatible withencoding/jsonin many ways (e.g. https://github.com/json-iterator/go/issues/229 ), but it hasn't been supported for a long time.segmentio/encoding/jsonis well supported for encoders, but some are not supported for decoder APIs such asToken( streaming decode )
Other libraries
I tried the benchmark but it didn't work. Also, it seems to panic when it receives an unexpected value because there is no error handling...
Benchmarking gave very slow results. It seems that it is assumed that the user will use the buffer pool properly. Also, development seems to have already stopped
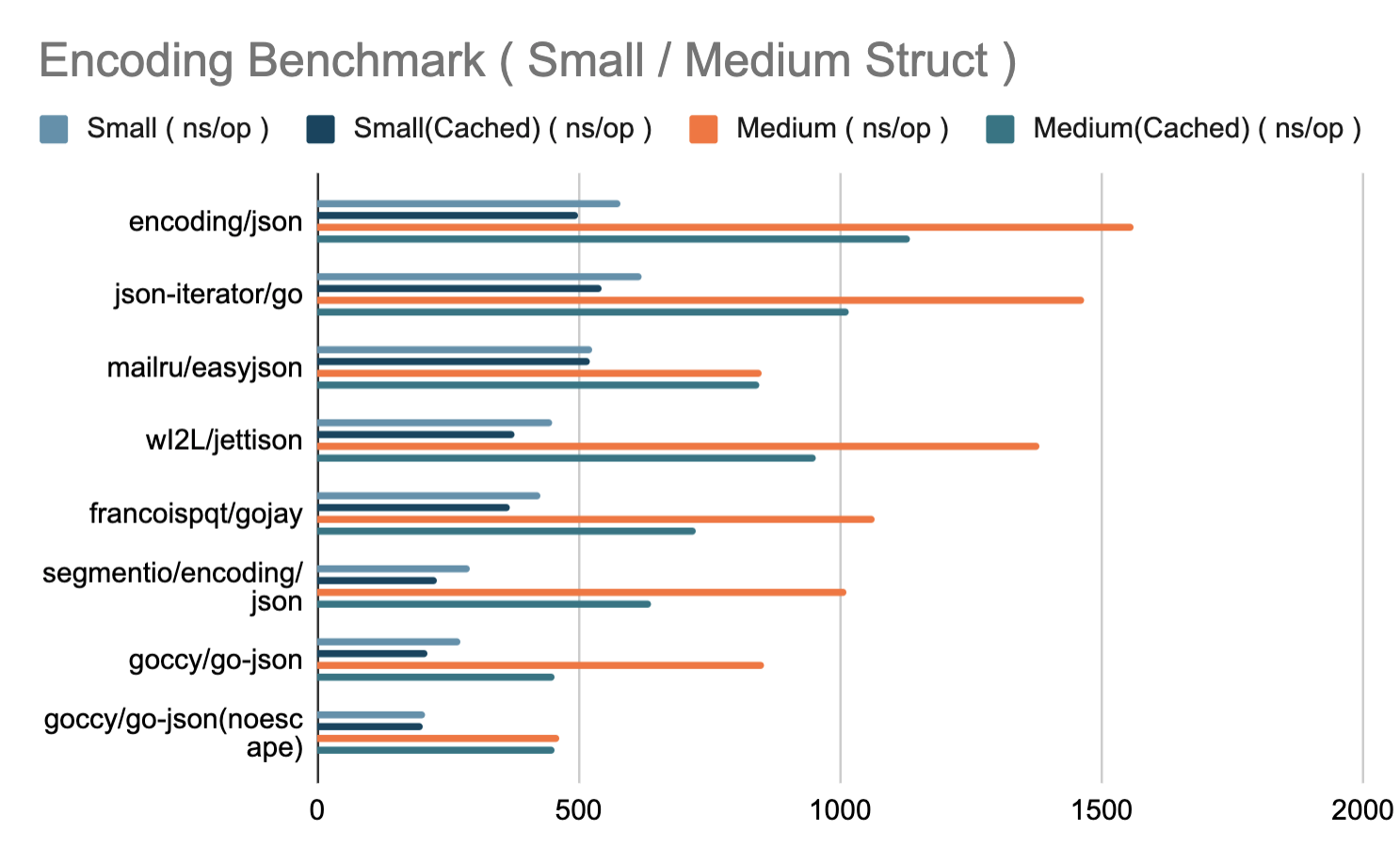
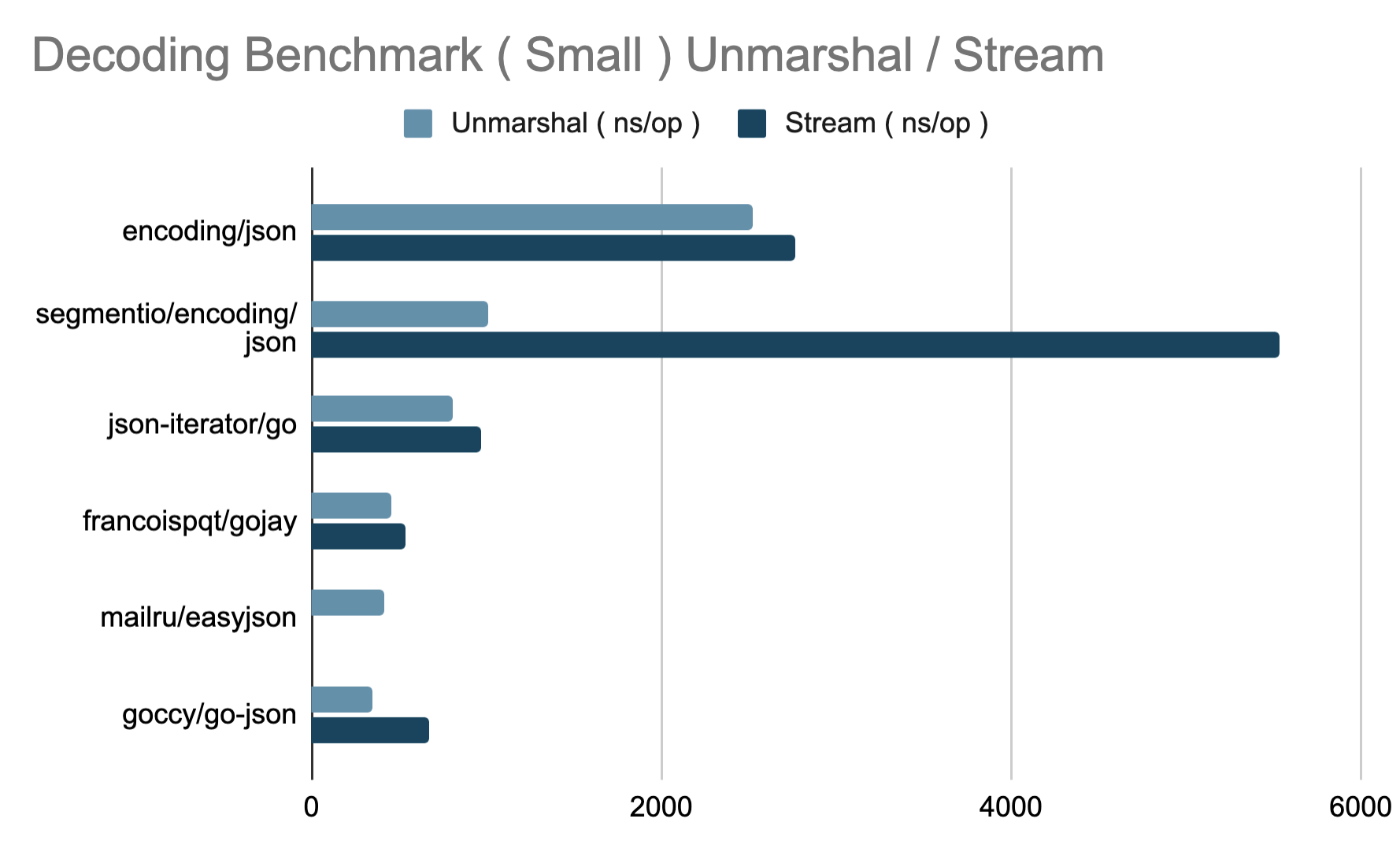
Benchmarks
$ cd benchmarks
$ go test -bench .
Encode

Decode


Fuzzing
go-json-fuzz is the repository for fuzzing tests. If you run the test in this repository and find a bug, please commit to corpus to go-json-fuzz and report the issue to go-json.
How it works
go-json is very fast in both encoding and decoding compared to other libraries.
It's easier to implement by using automatic code generation for performance or by using a dedicated interface, but go-json dares to stick to compatibility with encoding/json and is the simple interface. Despite this, we are developing with the aim of being the fastest library.
Here, we explain the various speed-up techniques implemented by go-json.
Basic technique
The techniques listed here are the ones used by most of the libraries listed above.
Buffer reuse
Since the only value required for the result of json.Marshal(interface{}) ([]byte, error) is []byte, the only value that must be allocated during encoding is the return value []byte .
Also, as the number of allocations increases, the performance will be affected, so the number of allocations should be kept as low as possible when creating []byte.
Therefore, there is a technique to reduce the number of times a new buffer must be allocated by reusing the buffer used for the previous encoding by using sync.Pool.
Finally, you allocate a buffer that is as long as the resulting buffer and copy the contents into it, you only need to allocate the buffer once in theory.
type buffer struct {
data []byte
}
var bufPool = sync.Pool{
New: func() interface{} {
return &buffer{data: make([]byte, 0, 1024)}
},
}
buf := bufPool.Get().(*buffer)
data := encode(buf.data) // reuse buf.data
newBuf := make([]byte, len(data))
copy(newBuf, buf)
buf.data = data
bufPool.Put(buf)
Elimination of reflection
As you know, the reflection operation is very slow.
Therefore, using the fact that the address position where the type information is stored is fixed for each binary ( we call this typeptr ),
we can use the address in the type information to call a pre-built optimized process.
For example, you can get the address to the type information from interface{} as follows and you can use that information to call a process that does not have reflection.
To process without reflection, pass a pointer (unsafe.Pointer) to the value is stored.
type emptyInterface struct {
typ unsafe.Pointer
ptr unsafe.Pointer
}
var typeToEncoder = map[uintptr]func(unsafe.Pointer)([]byte, error){}
func Marshal(v interface{}) ([]byte, error) {
iface := (*emptyInterface)(unsafe.Pointer(&v)
typeptr := uintptr(iface.typ)
if enc, exists := typeToEncoder[typeptr]; exists {
return enc(iface.ptr)
}
...
}
※ In reality, typeToEncoder can be referenced by multiple goroutines, so exclusive control is required.
Unique speed-up technique
Encoder
Do not escape arguments of Marshal
json.Marshal and json.Unmarshal receive interface{} value and they perform type determination dynamically to process.
In normal case, you need to use the reflect library to determine the type dynamically, but since reflect.Type is defined as interface, when you call the method of reflect.Type, The reflect's argument is escaped.
Therefore, the arguments for Marshal and Unmarshal are always escape to the heap.
However, go-json can use the feature of reflect.Type while avoiding escaping.
reflect.Type is defined as interface, but in reality reflect.Type is implemented only by the structure rtype defined in the reflect package.
For this reason, to date reflect.Type is the same as *reflect.rtype.
Therefore, by directly handling *reflect.rtype, which is an implementation of reflect.Type, it is possible to avoid escaping because it changes from interface to using struct.
The technique for working with *reflect.rtype directly from go-json is implemented at rtype.go
Also, the same technique is cut out as a library ( https://github.com/goccy/go-reflect )
Initially this feature was the default behavior of go-json.
But after careful testing, I found that I passed a large value to json.Marshal() and if the argument could not be assigned to the stack, it could not be properly escaped to the heap (a bug in the Go compiler).
Therefore, this feature will be provided as an optional until this issue is resolved.
To use it, add NoEscape like MarshalNoEscape()
Encoding using opcode sequence
I explained that you can use typeptr to call a pre-built process from type information.
In other libraries, this dedicated process is processed by making it an function calling like anonymous function, but function calls are inherently slow processes and should be avoided as much as possible.
Therefore, go-json adopted the Instruction-based execution processing system, which is also used to implement virtual machines for programming language.
If it is the first type to encode, create the opcode ( instruction ) sequence required for encoding.
From the second time onward, use typeptr to get the cached pre-built opcode sequence and encode it based on it. An example of the opcode sequence is shown below.
json.Marshal(struct{
X int `json:"x"`
Y string `json:"y"`
}{X: 1, Y: "hello"})
When encoding a structure like the one above, create a sequence of opcodes like this:
- opStructFieldHead ( `{` )
- opStructFieldInt ( `"x": 1,` )
- opStructFieldString ( `"y": "hello"` )
- opStructEnd ( `}` )
- opEnd
※ When processing each operation, write the letters on the right.
In addition, each opcode is managed by the following structure ( Pseudo code ).
type opType int
const (
opStructFieldHead opType = iota
opStructFieldInt
opStructFieldStirng
opStructEnd
opEnd
)
type opcode struct {
op opType
key []byte
next *opcode
}
The process of encoding using the opcode sequence is roughly implemented as follows.
func encode(code *opcode, b []byte, p unsafe.Pointer) ([]byte, error) {
for {
switch code.op {
case opStructFieldHead:
b = append(b, '{')
code = code.next
case opStructFieldInt:
b = append(b, code.key...)
b = appendInt((*int)(unsafe.Pointer(uintptr(p)+code.offset)))
code = code.next
case opStructFieldString:
b = append(b, code.key...)
b = appendString((*string)(unsafe.Pointer(uintptr(p)+code.offset)))
code = code.next
case opStructEnd:
b = append(b, '}')
code = code.next
case opEnd:
goto END
}
}
END:
return b, nil
}
In this way, the huge switch-case is used to encode by manipulating the linked list opcodes to avoid unnecessary function calls.
Opcode sequence optimization
One of the advantages of encoding using the opcode sequence is the ease of optimization. The opcode sequence mentioned above is actually converted into the following optimized operations and used.
- opStructFieldHeadInt ( `{"x": 1,` )
- opStructEndString ( `"y": "hello"}` )
- opEnd
It has been reduced from 5 opcodes to 3 opcodes !
Reducing the number of opcodees means reducing the number of branches with switch-case.
In other words, the closer the number of operations is to 1, the faster the processing can be performed.
In go-json, optimization to reduce the number of opcodes itself like the above and it speeds up by preparing opcodes with optimized paths.
Change recursive call from CALL to JMP
Recursive processing is required during encoding if the type is defined recursively as follows:
type T struct {
X int
U *U
}
type U struct {
T *T
}
b, err := json.Marshal(&T{
X: 1,
U: &U{
T: &T{
X: 2,
},
},
})
fmt.Println(string(b)) // {"X":1,"U":{"T":{"X":2,"U":null}}}
In go-json, recursive processing is processed by the operation type of opStructFieldRecursive.
In this operation, after acquiring the opcode sequence used for recursive processing, the function is not called recursively as it is, but the necessary values are saved by itself and implemented by moving to the next operation.
The technique of implementing recursive processing with the JMP operation while avoiding the CALL operation is a famous technique for implementing a high-speed virtual machine.
For more details, please refer to the article ( but Japanese only ).
Dispatch by typeptr from map to slice
When retrieving the data cached from the type information by typeptr, we usually use map.
Map requires exclusive control, so use sync.Map for a naive implementation.
However, this is slow, so it's a good idea to use the atomic package for exclusive control as implemented by segmentio/encoding/json ( https://github.com/segmentio/encoding/blob/master/json/codec.go#L41-L55 ).
This implementation slows down the set instead of speeding up the get, but it works well because of the nature of the library, it encodes much more for the same type.
However, as a result of profiling, I noticed that runtime.mapaccess2 accounts for a significant percentage of the execution time. So I thought if I could change the lookup from map to slice.
There is an API named typelinks defined in the runtime package that the reflect package uses internally.
This allows you to get all the type information defined in the binary at runtime.
The fact that all type information can be acquired means that by constructing slices in advance with the acquired total number of type information, it is possible to look up with the value of typeptr without worrying about out-of-range access.
However, if there is too much type information, it will use a lot of memory, so by default we will only use this optimization if the slice size fits within 2Mib .
If this approach is not available, it will fall back to the atomic based process described above.
If you want to know more, please refer to the implementation here
Decoder
Dispatch by typeptr from map to slice
Like the encoder, the decoder also uses typeptr to call the dedicated process.
Faster termination character inspection using NUL character
In order to decode, you have to traverse the input buffer character by position. At that time, if you check whether the buffer has reached the end, it will be very slow.
buf : []byte type variable. holds the string passed to the decoder
cursor : int64 type variable. holds the current read position
buflen := len(buf)
for ; cursor < buflen; cursor++ { // compare cursor and buflen at all times, it is so slow.
switch buf[cursor] {
case ' ', '\n', '\r', '\t':
}
}
Therefore, by adding the NUL (\000) character to the end of the read buffer as shown below, it is possible to check the termination character at the same time as other characters.
for {
switch buf[cursor] {
case ' ', '\n', '\r', '\t':
case '\000':
return nil
}
cursor++
}
Use Boundary Check Elimination
Due to the NUL character optimization, the Go compiler does a boundary check every time, even though buf[cursor] does not cause out-of-range access.
Therefore, go-json eliminates boundary check by fetching characters for hotspot by pointer operation. For example, the following code.
func char(ptr unsafe.Pointer, offset int64) byte {
return *(*byte)(unsafe.Pointer(uintptr(ptr) + uintptr(offset)))
}
p := (*sliceHeader)(&unsafe.Pointer(buf)).data
for {
switch char(p, cursor) {
case ' ', '\n', '\r', '\t':
case '\000':
return nil
}
cursor++
}
Checking the existence of fields of struct using Bitmaps
I found by the profiling result, in the struct decode, lookup process for field was taking a long time.
For example, consider decoding a string like {"a":1,"b":2,"c":3} into the following structure:
type T struct {
A int `json:"a"`
B int `json:"b"`
C int `json:"c"`
}
At this time, it was found that it takes a lot of time to acquire the decoding process corresponding to the field from the field name as shown below during the decoding process.
fieldName := decodeKey(buf, cursor) // "a" or "b" or "c"
decoder, exists := fieldToDecoderMap[fieldName] // so slow
if exists {
decoder(buf, cursor)
} else {
skipValue(buf, cursor)
}
To improve this process, json-iterator/go is optimized so that it can be branched by switch-case when the number of fields in the structure is 10 or less (switch-case is faster than map). However, there is a risk of hash collision because the value hashed by the FNV algorithm is used for conditional branching. Also, gojay processes this part at high speed by letting the library user yourself write switch-case.
go-json considers and implements a new approach that is different from these. I call this bitmap field optimization.
The range of values per character can be represented by [256]byte. Also, if the number of fields in the structure is 8 or less, int8 type can represent the state of each field.
In other words, it has the following structure.
- Base ( 8bit ):
00000000 - Key "a":
00000001( assign key "a" to the first bit ) - Key "b":
00000010( assign key "b" to the second bit ) - Key "c":
00000100( assign key "c" to the third bit )
Bitmap structure is the following
| key index(0) |
------------------------
0 | 00000000 |
1 | 00000000 |
~~ | |
97 (a) | 00000001 |
98 (b) | 00000010 |
99 (c) | 00000100 |
~~ | |
255 | 00000000 |
You can think of this as a Bitmap with a height of 256 and a width of the maximum string length in the field name.
In other words, it can be represented by the following type .
[maxFieldKeyLength][256]int8
When decoding a field character, check whether the corresponding character exists by referring to the pre-built bitmap like the following.
var curBit int8 = math.MaxInt8 // 11111111
c := char(buf, cursor)
bit := bitmap[keyIdx][c]
curBit &= bit
if curBit == 0 {
// not found field
}
If curBit is not 0 until the end of the field string, then the string is
You may have hit one of the fields.
But the possibility is that if the decoded string is shorter than the field string, you will get a false hit.
- input:
{"a":1}
type T struct {
X int `json:"abc"`
}
※ Since a is shorter than abc, it can decode to the end of the field character without curBit being 0.
Rest assured. In this case, it doesn't matter because you can tell if you hit by comparing the string length of a with the string length of abc.
Finally, calculate the position of the bit where 1 is set and get the corresponding value, and you're done.
Using this technique, field lookups are possible with only bitwise operations and access to slices.
go-json uses a similar technique for fields with 9 or more and 16 or less fields. At this time, Bitmap is constructed as [maxKeyLen][256]int16 type.
Currently, this optimization is not performed when the maximum length of the field name is long (specifically, 64 bytes or more) in addition to the limitation of the number of fields from the viewpoint of saving memory usage.
Others
I have done a lot of other optimizations. I will find time to write about them. If you have any questions about what's written here or other optimizations, please visit the #go-json channel on gophers.slack.com .
Reference
Regarding the story of go-json, there are the following articles in Japanese only.
- https://speakerdeck.com/goccy/zui-su-falsejsonraiburariwoqiu-mete
- https://engineering.mercari.com/blog/entry/1599563768-081104c850/
Looking for Sponsors
I'm looking for sponsors this library. This library is being developed as a personal project in my spare time. If you want a quick response or problem resolution when using this library in your project, please register as a sponsor. I will cooperate as much as possible. Of course, this library is developed as an MIT license, so you can use it freely for free.
License
MIT