| .. | ||
| biobert | ||
| data | ||
| notebooks | ||
| results | ||
| scripts | ||
| tensorrt-inference-server@33931a4f88 | ||
| trtis | ||
| utils | ||
| .dockerignore | ||
| .gitignore | ||
| .gitmodules | ||
| __init__.py | ||
| configurations.yml | ||
| CONTRIBUTING.md | ||
| Dockerfile | ||
| extract_features.py | ||
| fp16_utils.py | ||
| fused_layer_norm.py | ||
| gpu_environment.py | ||
| LICENSE | ||
| modeling.py | ||
| modeling_test.py | ||
| multilingual.md | ||
| NOTICE | ||
| optimization.py | ||
| optimization_test.py | ||
| predicting_movie_reviews_with_bert_on_tf_hub.ipynb | ||
| README.md | ||
| requirements.txt | ||
| run.sub | ||
| run_classifier.py | ||
| run_classifier_with_tfhub.py | ||
| run_ner.py | ||
| run_pretraining.py | ||
| run_re.py | ||
| run_squad.py | ||
| sample_text.txt | ||
| tf_metrics.py | ||
| tokenization.py | ||
| tokenization_test.py | ||
BERT For TensorFlow
This repository provides a script and recipe to train the BERT model for TensorFlow to achieve state-of-the-art accuracy, and is tested and maintained by NVIDIA.
Table Of Contents
- Model overview
- Setup
- Quick Start Guide
- Advanced
- Performance
- Benchmarking
- Results
- Training accuracy results
- Training performance results
- Inference performance results
- Release notes
Model overview
BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks. This model is based on the BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper. NVIDIA's BERT is an optimized version of Google's official implementation, leveraging mixed precision arithmetic and Tensor Cores on V100 GPUs for faster training times while maintaining target accuracy.
Other publicly available implementations of BERT include:
This model is trained with mixed precision using Tensor Cores on NVIDIA Volta and Turing GPUs. Therefore, researchers can get results upto 4x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
BERT's model architecture is a multi-layer bidirectional Transformer encoder. Based on the model size, we have the following two default configurations of BERT:
| Model | Hidden layers | Hidden unit size | Attention heads | Feedforward filter size | Max sequence length | Parameters |
|---|---|---|---|---|---|---|
| BERTBASE | 12 encoder | 768 | 12 | 4 x 768 | 512 | 110M |
| BERTLARGE | 24 encoder | 1024 | 16 | 4 x 1024 | 512 | 330M |
BERT training consists of two steps, pre-training the language model in an unsupervised fashion on vast amounts of unannotated datasets, and then using this pre-trained model for fine-tuning for various NLP tasks, such as question and answer, sentence classification, or sentiment analysis. Fine-tuning typically adds an extra layer or two for the specific task and further trains the model using a task-specific annotated dataset, starting from the pre-trained backbone weights. The end-to-end process in depicted in the following image:
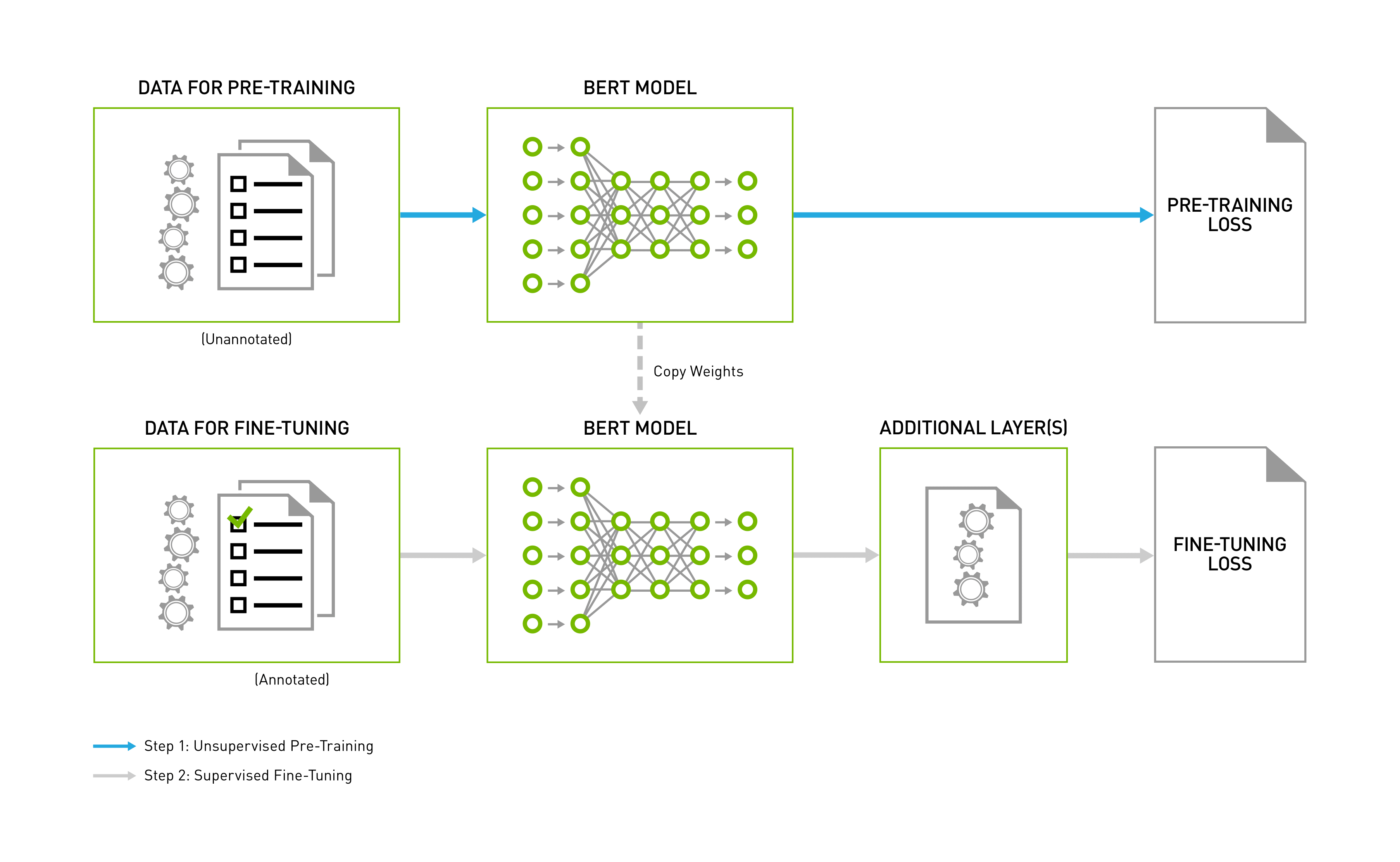
Figure 1: BERT Pipeline
Default configuration
This repository contains scripts to interactively launch data download, training, benchmarking and inference routines in a Docker container for both pre-training and fine tuning for Question Answering. The major differences between the official implementation of the paper and our version of BERT are as follows:
- Mixed precision support with TensorFlow Automatic Mixed Precision (TF-AMP), which enables mixed precision training without any changes to the code-base by performing automatic graph rewrites and loss scaling controlled by an environmental variable.
- Scripts to download dataset for:
- Pre-training - Wikipedia, BookCorpus
- Fine tuning - SQuAD (Stanford Question Answering Dataset)
- Fine tuning - GLUE (The General Language Understanding Evaluation benchmark)
- Pretrained weights from Google
- Custom fused CUDA kernels for faster computations
- Multi-GPU/Multi-node support using Horovod
The following performance optimizations were implemented in this model:
- XLA support (experimental).
These techniques and optimizations improve model performance and reduce training time, allowing you to perform various NLP tasks with no additional effort.
Feature support matrix
The following features are supported by this model.
| Feature | BERT |
|---|---|
| Horovod Multi-GPU | Yes |
| Horovod Multi-Node | Yes |
| Automatic mixed precision (AMP) | Yes |
| LAMB | Yes |
Features
Multi-GPU training with Horovod - Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial
LAMB stands for Layerwise Adaptive Moments based optimizer, is a large batch optimization technique that helps accelerate training of deep neural networks using large minibatches. It allows using a global batch size of 65536 and 32768 on sequence lengths 128 and 512 respectively, compared to a batch size of 256 for Adam. The optimized implementation accumulates 1024 gradients batches in phase 1 and 4096 steps in phase 2 before updating weights once. This results in 27% training speedup on a single DGX2 node. On multi-node systems, LAMB allows scaling up to 1024 GPUs resulting in training speedups of up to 17x in comparison to Adam. Adam has limitations on the learning rate that can be used since it is applied globally on all parameters whereas LAMB follows a layerwise learning rate strategy.
NVLAMB adds necessary tweaks to LAMB version 1, to ensure correct convergence. The algorithm is as follows:

Mixed precision training
Mixed precision is the combined use of different numerical precision in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in the Volta and Turing architecture, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
Automatic Mixed Precision (AMP) for TensorFlow enables the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta and Turing GPUs automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximizes the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
Glossary
Fine-tuning Training an already pretrained model further using a task specific dataset for subject-specific refinements, by adding task-specific layers on top if required.
Language Model Assigns a probability distribution over a sequence of words. Given a sequence of words, it assigns a probability to the whole sequence.
Pre-training Training a model on vast amounts of data on the same (or different) task to build general understandings.
Transformer The paper Attention Is All You Need introduces a novel architecture called Transformer that uses an attention mechanism and transforms one sequence into another.
Setup
The following section lists the requirements in order to start training the BERT model.
Requirements
This repository contains Dockerfile which extends the TensorFlow NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
- NVIDIA Docker
- TensorFlow 19.08-py3+ NGC container
- NVIDIA Volta or Turing based GPU
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running TensorFlow
For those unable to use the TensorFlow NGC container, to set up the required environment or create your own container, see the versioned NVIDIA Container Support Matrix.
For multi-node, the sample provided in this repository requires Enroot and Pyxis set up on a SLURM cluster.
More information on how to set up and launch can be found in the Multi-node Documentation.
Quick Start Guide
To pretrain or fine tune your model for Question Answering using mixed precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the BERT model.
- Clone the repository.
git clone https://github.com/NVIDIA/DeepLearningExamples
cd DeepLearningExamples/TensorFlow/LanguageModeling/BERT
- Build the BERT TensorFlow NGC container.
bash scripts/docker/build.sh
- Download and preprocess the dataset.
This repository provides scripts to download, verify and extract the SQuAD dataset, GLUE dataset and pretrained weights for fine tuning as well as Wikipedia and BookCorpus dataset for pre-training.
To download, verify, and extract the required datasets, run:
bash scripts/data_download.sh
The script launches a Docker container with the current directory mounted and downloads the datasets to a data/ folder on the host.
Note: The dataset is 170GB+ and takes 15+ hours to download. The BookCorpus server could sometimes get overloaded and also contain broken links resulting in HTTP 403 and 503 errors. You can either skip the missing files or retry downloading at a later time. Expired dataset links are ignored during data download.
- Download the pretrained models from NGC.
We have uploaded checkpoints for both fine tuning and pre-training for various configurations on the NGC Model Registry. You can download them directly from the NGC model catalog. Download them to the results/models/ to easily access them in your scripts.
- Start an interactive session in the NGC container to run training/inference.
After you build the container image and download the data, you can start an interactive CLI session as follows:
bash scripts/docker/launch.sh
The launch.sh script assumes that the datasets are in the following locations by default after downloading the data.
- SQuAD v1.1 -
data/download/squad/v1.1 - SQuAD v2.0 -
data/download/squad/v2.0 - GLUE The Corpus of Linguistic Acceptability (CoLA) -
data/download/CoLA - GLUE Microsoft Research Paraphrase Corpus (MRPC) -
data/download/MRPC - GLUE The Multi-Genre NLI Corpus (MNLI) -
data/download/MNLI - BERT Large -
data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16 - BERT Base -
data/download/google_pretrained_weights/uncased_L-12_H-768_A-12 - BERT -
data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16 - Wikipedia + BookCorpus TFRecords -
data/tfrecords<config>/books_wiki_en_corpus
- Start pre-training.
BERT is designed to pre-train deep bidirectional representations for language representations. The following scripts are to replicate pre-training on Wikipedia and BookCorpus from the LAMB paper. These scripts are general and can be used for pre-training language representations on any corpus of choice.
From within the container, you can use the following script to run pre-training using LAMB.
bash scripts/run_pretraining_lamb.sh <train_batch_size_phase1> <train_batch_size_phase2> <eval_batch_size> <learning_rate_phase1> <learning_rate_phase2> <precision> <use_xla> <num_gpus> <warmup_steps_phase1> <warmup_steps_phase2> <train_steps> <save_checkpoint_steps> <num_accumulation_phase1> <num_accumulation_steps_phase2> <bert_model>
For BERT Large FP16 training with XLA using a DGX-1 V100 32G, run:
bash scripts/run_pretraining_lamb.sh 64 8 8 7.5e-4 5e-4 fp16 true 8 2000 200 7820 100 128 512 large
For BERT Large FP32 training without XLA using a DGX-1 V100 32G, run:
bash scripts/run_pretraining_lamb.sh 64 8 8 7.5e-4 5e-4 fp32 false 8 2000 200 7820 100 128 512 large
Alternatively, to run pre-training with Adam as in the original BERT paper from within the container, run:
bash scripts/run_pretraining_adam.sh <train_batch_size_per_gpu> <eval_batch_size> <learning_rate_per_gpu> <precision> <use_xla> <num_gpus> <warmup_steps> <train_steps> <save_checkpoint_steps>
- Start fine tuning.
The above pretrained BERT representations can be fine tuned with just one additional output layer for a state-of-the-art Question Answering system. From within the container, you can use the following script to run fine-training for SQuAD.
bash scripts/run_squad.sh <batch_size_per_gpu> <learning_rate_per_gpu> <precision> <use_xla> <num_gpus> <seq_length> <doc_stride> <bert_model> <squad_version> <checkpoint> <epochs>
For SQuAD 1.1 FP16 training with XLA using a DGX-1 V100 32G, run:
bash scripts/run_squad.sh 10 5e-6 fp16 true 8 384 128 large 1.1 data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/bert_model.ckpt 1.1
For SQuAD 2.0 FP32 training without XLA using a DGX-1 V100 32G, run:
bash scripts/run_squad.sh 5 5e-6 fp32 false 8 384 128 large 1.1 data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/bert_model.ckpt 2.0
Alternatively, to run fine tuning on GLUE benchmark, run:
bash scripts/run_glue.sh <task_name> <batch_size_per_gpu> <learning_rate_per_gpu> <precision> <use_xla> <num_gpus> <seq_length> <doc_stride> <bert_model> <epochs> <warmup_proportion> <checkpoint>
The GLUE tasks supported include CoLA, MRPC and MNLI.
- Start validation/evaluation.
The run_squad_inference.sh script runs inference on a checkpoint fine tuned for SQuAD and evaluates the validity of predictions on the basis of exact match and F1 score.
bash scripts/run_squad_inference.sh <init_checkpoint> <batch_size> <precision> <use_xla> <seq_length> <doc_stride> <bert_model> <squad_version>
For SQuAD 2.0 FP16 inference with XLA using a DGX-1 V100 32G, run:
bash scripts/run_squad_inference.sh /results/model.ckpt 8 fp16 true 384 128 large 2.0
For SQuAD 1.1 FP32 inference without XLA using a DGX-1 V100 32G, run:
bash scripts/run_squad_inference.sh /results/model.ckpt 8 fp32 false 384 128 large 1.1
Alternatively, to run inference on GLUE benchmark, run:
bash scripts/run_glue_inference.sh <task_name> <init_checkpoint> <batch_size_per_gpu> <precision> <use_xla> <seq_length> <doc_stride> <bert_model>
Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
Scripts and sample code
In the root directory, the most important files are:
run_pretraining.py- Serves as entry point for pre-trainingrun_squad.py- Serves as entry point for SQuAD trainingrun_classifier.py- Serves as entry point for GLUE trainingDockerfile- Container with the basic set of dependencies to run BERT
The scripts/ folder encapsulates all the one-click scripts required for running various functionalities supported such as:
run_squad.sh- Runs SQuAD training and inference usingrun_squad.pyfilerun_glue.sh- Runs GLUE training and inference using therun_classifier.pyfilerun_pretraining_adam.sh- Runs pre-training with Adam optimizer using therun_pretraining.pyfilerun_pretraining_lamb.sh- Runs pre-training with LAMB optimizer using therun_pretraining.pyfile in two phases. Phase 1 does 90% of training with sequence length = 128. In phase 2, the remaining 10% of the training is done with sequence length = 512.data_download.sh- Downloads datasets using files in thedata/folderfinetune_train_benchmark.sh- Captures performance metrics of training for multiple configurationsfinetune_inference_benchmark.sh- Captures performance metrics of inference for multiple configurations
Other folders included in the root directory are:
data/- Necessary folders and scripts to download datasets required for fine tuning and pre-training BERT.utils/- Necessary files for preprocessing data before feeding into BERT and hooks for obtaining performance metrics from BERT.
Parameters
Aside from the options to set hyperparameters, the relevant options to control the behaviour of the run_pretraining.py script are:
--bert_config_file: The config json file corresponding to the pre-trained BERT model. This specifies the model architecture.
--init_checkpoint: Initial checkpoint (usually from a pre-trained BERT model).
--[no]do_eval: Whether to run evaluation on the dev set.(default: 'false')
--[no]do_train: Whether to run training.(evaluation: 'false')
--eval_batch_size: Total batch size for eval.(default: '8')(an integer)
--[no]horovod: Whether to use Horovod for multi-gpu runs(default: 'false')
--[no]use_fp16: Whether to enable AMP ops.(default: 'false')
--input_files_dir: Input TF example files (can be a dir or comma separated).
--output_dir: The output directory where the model checkpoints will be written.
--optimizer_type: Optimizer used for training - LAMB or ADAM
--num_accumulation_steps: Number of accumulation steps before gradient update. Global batch size = num_accumulation_steps * train_batch_size
--allreduce_post_accumulation: Whether to all reduce after accumulation of N steps or after each step
Aside from the options to set hyperparameters, some relevant options to control the behaviour of the run_squad.py script are:
--bert_config_file: The config json file corresponding to the pre-trained BERT model. This specifies the model architecture.
--output_dir: The output directory where the model checkpoints will be written.
--[no]do_predict: Whether to run evaluation on the dev set. (default: 'false')
--[no]do_train: Whether to run training. (default: 'false')
--learning_rate: The initial learning rate for Adam.(default: '5e-06')(a number)
--max_answer_length: The maximum length of an answer that can be generated. This is needed because the start and end predictions are not conditioned on one another.(default: '30')(an integer)
--max_query_length: The maximum number of tokens for the question. Questions longer than this will be truncated to this length.(default: '64')(an integer)
--max_seq_length: The maximum total input sequence length after WordPiece tokenization. Sequences longer than this will be truncated, and sequences shorter than this will be padded.(default: '384')(an integer)
--predict_batch_size: Total batch size for predictions.(default: '8')(an integer)
--train_batch_size: Total batch size for training.(default: '8')(an integer)
--[no]use_fp16: Whether to enable AMP ops.(default: 'false')
--[no]use_xla: Whether to enable XLA JIT compilation.(default: 'false')
--[no]version_2_with_negative: If true, the SQuAD examples contain some that do not have an answer.(default: 'false')
Aside from the options to set hyperparameters, some relevant options to control the behaviour of the run_classifier.py script are:
--bert_config_file: The config json file corresponding to the pre-trained BERT model. This specifies the model architecture.
--data_dir: The input data dir. Should contain the .tsv files (or other data files) for the task.
--[no]do_eval: Whether to run eval on the dev set.
(default: 'false')
--[no]do_predict: Whether to run the model in inference mode on the test set.(default: 'false')
--[no]do_train: Whether to run training.(default: 'false')
--[no]horovod: Whether to use Horovod for multi-gpu runs(default: 'false')
--init_checkpoint: Initial checkpoint (usually from a pre-trained BERT model).
--max_seq_length: The maximum total input sequence length after WordPiece tokenization. Sequences longer than this will be truncated, and sequences shorter than this will be padded.(default: '128')(an integer)
--num_train_epochs: Total number of training epochs to perform.(default: '3.0')(a number)
--output_dir: The output directory where the model checkpoints will be written.
--task_name: The name of the task to train.
--train_batch_size: Total batch size for training.(default: '32')(an integer)
--[no]use_fp16: Whether to use fp32 or fp16 arithmetic on GPU.
(default: 'false')
--[no]use_xla: Whether to enable XLA JIT compilation.
(default: 'false')
--vocab_file: The vocabulary file that the BERT model was trained on.
--warmup_proportion: Proportion of training to perform linear learning rate warmup for. E.g., 0.1 = 10% of training.(default: '0.1')(a number)
Note: When initializing from a checkpoint using --init_checkpoint and a corpus of your choice, keep in mind that bert_config_file and vocab_file should remain unchanged.
Command-line options
To see the full list of available options and their descriptions, use the -h or --help command-line option with the Python file, for example:
python run_pretraining.py --help
python run_squad.py --help
python run_classifier.py --help
Getting the data
For pre-training BERT, we use the concatenation of Wikipedia (2500M words) as well as BookCorpus (800M words). For Wikipedia, we extract only the text passages from here and ignore headers list and tables. It is structured as a document level corpus rather than a shuffled sentence level corpus because it is critical to extract long contiguous sentences.
The next step is to run create_pretraining_data.py with the document level corpus as input, which generates input data and labels for the masked language modeling and next sentence prediction tasks. Pre-training can also be performed on any corpus of your choice. The collection of data generation scripts are intended to be modular to allow modifications for additional preprocessing steps or to use additional data. They can hence easily be modified for an arbitrary corpus.
The preparation of an individual pre-training dataset is described in the create_datasets_from_start.sh script found in the data/ folder. The component steps to prepare the datasets are as follows:
- Data download and extract - the dataset is downloaded and extracted.
- Clean and format - document tags, etc. are removed from the dataset. The end result of this step is a
{dataset_name_one_article_per_line}.txtfile that contains the entire corpus. Each line in the text file contains an entire document from the corpus. One file per dataset is created in theformatted_one_article_per_linefolder. - Sharding - the sentence segmented corpus file is split into a number of smaller text documents. The sharding is configured so that a document will not be split between two shards. Sentence segmentation is performed at this time using NLTK.
- TFRecord file creation - each text file shard is processed by the
create_pretraining_data.pyscript to produce a corresponding TFRecord file. The script generates input data and labels for masked language modeling and sentence prediction tasks for the input text shard.
For fine tuning BERT for the task of Question Answering, we use SQuAD and GLUE. SQuAD v1.1 has 100,000+ question-answer pairs on 500+ articles. SQuAD v2.0 combines v1.1 with an additional 50,000 new unanswerable questions and must not only answer questions but also determine when that is not possible. GLUE consists of single-sentence tasks, similarity and paraphrase tasks and inference tasks. We support one of each: CoLA, MNLI and MRPC.
Dataset guidelines
The procedure to prepare a text corpus for pre-training is described in the previous section. This section provides additional insight into how exactly raw text is processed so that it is ready for pre-training.
First, raw text is tokenized using WordPiece tokenization. A [CLS] token is inserted at the start of every sequence, and the two sentences in the sequence are separated by a [SEP] token.
Note: BERT pre-training looks at pairs of sentences at a time. A sentence embedding token [A] is added to the first sentence and token [B] to the next.
BERT pre-training optimizes for two unsupervised classification tasks. The first is Masked Language Modelling (Masked LM). One training instance of Masked LM is a single modified sentence. Each token in the sentence has a 15% chance of being replaced by a [MASK] token. The chosen token is replaced with [MASK] 80% of the time, 10% with another random token and the remaining 10% with the same token. The task is then to predict the original token.
The second task is next sentence prediction. One training instance of BERT pre-training is two sentences (a sentence pair). A sentence pair may be constructed by simply taking two adjacent sentences from a single document, or by pairing up two random sentences with equal probability. The goal of this task is to predict whether or not the second sentence followed the first in the original document.
The create_pretraining_data.py script takes in raw text and creates training instances for both pre-training tasks.
Multi-dataset
We are able to combine multiple datasets into a single dataset for pre-training on a diverse text corpus. Once TFRecords have been created for each component dataset, you can create a combined dataset by adding the directory to SOURCES in run_pretraining_*.sh. This will feed all matching files to the input pipeline in run_pretraining.py. However, in the training process, only one TFRecord file is consumed at a time, therefore, the training instances of any given training batch will all belong to the same source dataset.
Training process
The training process consists of two steps: pre-training and fine tuning.
Pre-training
Pre-training is performed using the run_pretraining.py script along with parameters defined in the scripts/run_pretraining_lamb.sh.
The run_pretraining_lamb.sh script runs a job on a single node that trains the BERT-large model from scratch using the Wikipedia and BookCorpus datasets as training data. By default, the training script:
-
Runs on 8 GPUs.
-
Has FP16 precision enabled.
-
Is XLA enabled.
-
Creates a log file containing all the output.
-
Saves a checkpoint every 100 iterations (keeps only the latest checkpoint) and at the end of training. All checkpoints, evaluation results and training logs are saved to the
/resultsdirectory (in the container which can be mounted to a local directory). -
Evaluates the model at the end of each phase.
-
Phase 1
- Runs 7038 steps with 2000 warmup steps
- Sets Maximum sequence length as 128
- Sets Global Batch size as 64K
-
Phase 2
- Runs 1564 steps with 200 warm-up steps
- Sets Maximum sequence length as 512
- Sets Global Batch size as 32K
- Starts from Phase1's final checkpoint
These parameters train Wikipedia and BookCorpus with reasonable accuracy on a DGX-1 with 32GB V100 cards.
For example:
scripts/run_pretraining_lamb.sh <train_batch_size_phase1> <train_batch_size_phase2> <eval_batch_size> <learning_rate_phase1> <learning_rate_phase2> <precision> <use_xla> <num_gpus> <warmup_steps_phase1> <warmup_steps_phase2> <train_steps> <save_checkpoint_steps> <num_accumulation_phase1> <num_accumulation_steps_phase2> <bert_model>
Where:
-
<training_batch_size_phase*>is per-GPU batch size used for training in the respective phase. Batch size varies with precision, larger batch sizes run more efficiently, but require more memory. -
<eval_batch_size>is per-GPU batch size used for evaluation after training. -
<learning_rate_phase1>is the default rate of 1e-4 is good for global batch size 256. -
<learning_rate_phase2>is the default rate of 1e-4 is good for global batch size 256. -
<precision>is the type of math in your model, can be eitherfp32orfp16. Specifically:fp32is 32-bit IEEE single precision floats.fp16is Automatic rewrite of TensorFlow compute graph to take advantage of 16-bit arithmetic whenever it is safe.
-
<num_gpus>is the number of GPUs to use for training. Must be equal to or smaller than the number of GPUs attached to your node. -
<warmup_steps_phase*>is the number of warm-up steps at the start of training in the respective phase. -
<training_steps>is the total number of training steps in both phases combined. -
<save_checkpoint_steps>controls how often checkpoints are saved. Default is 100 steps. -
<num_accumulation_phase*>is used to mimic higher batch sizes in the respective phase by accumulating gradients N times before weight update. -
<bert_model>is used to indicate whether to pretrain BERT Large or BERT Base model
The following sample code trains BERT-large from scratch on a single DGX-2 using FP16 arithmetic. This will take around 4.5 days.
bert_tf/scripts/run_pretraining_lamb.sh 32 8 8 3.75e-4 2.5e-4 fp16 true 16 2000 200 7820 100 128 512 256 large
Fine tuning
Fine tuning is performed using the run_squad.py script along with parameters defined in scripts/run_squad.sh.
The run_squad.sh script trains a model and performs evaluation on the SQuAD dataset. By default, the training script:
- Trains for SQuAD v1.1 dataset.
- Trains on BERT Large Model.
- Uses 8 GPUs and batch size of 10 on each GPU.
- Has FP16 precision enabled.
- Is XLA enabled.
- Runs for 2 epochs.
- Saves a checkpoint every 1000 iterations (keeps only the latest checkpoint) and at the end of training. All checkpoints, evaluation results and training logs are saved to the
/resultsdirectory (in the container which can be mounted to a local directory). - Evaluation is done at the end of training. To skip evaluation, modify
--do_predicttoFalse.
This script outputs checkpoints to the /results directory, by default, inside the container. Mount point of /results can be changed in the scripts/docker/launch.sh file. The training log contains information about:
- Loss for the final step
- Training and evaluation performance
- F1 and exact match score on the Dev Set of SQuAD after evaluation.
The summary after training is printed in the following format:
I0312 23:10:45.137036 140287431493376 run_squad.py:1332] 0 Total Training Time = 3007.00 Training Time W/O start up overhead = 2855.92 Sentences processed = 175176
I0312 23:10:45.137243 140287431493376 run_squad.py:1333] 0 Training Performance = 61.3378 sentences/sec
I0312 23:14:00.550846 140287431493376 run_squad.py:1396] 0 Total Inference Time = 145.46 Inference Time W/O start up overhead = 131.86 Sentences processed = 10840
I0312 23:14:00.550973 140287431493376 run_squad.py:1397] 0 Inference Performance = 82.2095 sentences/sec
{"exact_match": 83.69914853358561, "f1": 90.8477003317459}
Multi-GPU training is enabled with the Horovod TensorFlow module. The following example runs training on 8 GPUs:
BERT_DIR=data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16
mpi_command="mpirun -np 8 -H localhost:8 \
--allow-run-as-root -bind-to none -map-by slot \
-x NCCL_DEBUG=INFO \
-x LD_LIBRARY_PATH \
-x PATH -mca pml ob1 -mca btl ^openib" \
python run_squad.py --horovod --vocab_file=$BERT_DIR/vocab.txt \
--bert_config_file=$BERT_DIR/bert_config.json \
--output_dir=/results
Multi-node
Multi-node runs can be launched on a pyxis/enroot Slurm cluster (see Requirements) with the run.sub script with the following command for a 4-node DGX1 example for both phase 1 and phase 2:
BATCHSIZE=16 LEARNING_RATE='1.875e-4' NUM_ACCUMULATION_STEPS=128 PHASE=1 sbatch -N4 --ntasks-per-node=8 run.sub
BATCHSIZE=2 LEARNING_RATE='1.25e-4' NUM_ACCUMULATION_STEPS=512 PHASE=1 sbatch -N4 --ntasks-per-node=8 run.sub
Checkpoint after phase 1 will be saved in checkpointdir specified in run.sub. The checkpoint will be automatically picked up to resume training on phase 2. Note that phase 2 should be run after phase 1.
Variables to re-run the Training performance results are available in the configurations.yml file.
The batch variables BATCHSIZE, LEARNING_RATE, NUM_ACCUMULATION_STEPS refer to the Python arguments train_batch_size, learning_rate, num_accumulation_steps respectively.
The variable PHASE refers to phase specific arguments available in run.sub.
Note that the run.sub script is a starting point that has to be adapted depending on the environment. In particular, variables such as datadir handle the location of the files for each phase.
Refer to the files contents to see the full list of variables to adjust for your system.
Inference process
Inference on a fine tuned Question Answering system is performed using the run_squad.py script along with parameters defined in scripts/run_squad_inference.sh. Inference is supported on a single GPU.
The run_squad_inference.sh script trains a model and performs evaluation on the SQuAD dataset. By default, the inferencing script:
- Uses SQuAD v1.1 dataset
- Has FP16 precision enabled
- Is XLA enabled
- Evaluates the latest checkpoint present in
/resultswith a batch size of 8
This script outputs predictions file to /results/predictions.json and computes F1 score and exact match score using SQuAD's evaluate file. Mount point of /results can be changed in the scripts/docker/launch.sh file.
The output log contains information about: Inference performance Inference Accuracy (F1 and exact match scores) on the Dev Set of SQuAD after evaluation.
The summary after inference is printed in the following format:
I0312 23:14:00.550846 140287431493376 run_squad.py:1396] 0 Total Inference Time = 145.46 Inference Time W/O start up overhead = 131.86 Sentences processed = 10840
I0312 23:14:00.550973 140287431493376 run_squad.py:1397] 0 Inference Performance = 82.2095 sentences/sec
{"exact_match": 83.69914853358561, "f1": 90.8477003317459}
Deploying the BERT model using TensorRT Inference Server
The NVIDIA TensorRT Inference Server provides a datacenter and cloud inferencing solution optimized for NVIDIA GPUs. The server provides an inference service via an HTTP or gRPC endpoint, allowing remote clients to request inferencing for any number of GPU or CPU models being managed by the server. More information on how to perform inference using TensorRT Inference Server can be found in the subfolder ./trtis/README.md.
BioBERT
Many works, including BioBERT, SciBERT, NCBI-BERT, ClinicalBERT (MIT), ClinicalBERT (NYU, Princeton), and others at BioNLP’19 workshop, show that pre-training of BERT on large biomedical text corpus such as PubMed results in better performance in biomedical text-mining tasks.
More information on how to download a biomedical corpus and pre-train as well as finetune for biomedical tasks can be found in the subfolder ./biobert/README.md.
Performance
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Both of these benchmarking scripts enable you to run a number of epochs, extract performance numbers, and run the BERT model for fine tuning.
Training performance benchmark
Training benchmarking can be performed by running the script:
scripts/finetune_train_benchmark.sh <bert_model> <use_xla> <num_gpu> squad
This script runs 2 epochs by default on the SQuAD v1.1 dataset and extracts performance numbers for various batch sizes and sequence lengths in both FP16 and FP32. These numbers are saved at /results/squad_train_benchmark_bert_<bert_model>_gpu_<num_gpu>.log.
Inference performance benchmark
Inference benchmarking can be performed by running the script:
scripts/finetune_inference_benchmark.sh <bert_model> squad
This script runs 1024 eval iterations by default on the SQuAD v1.1 dataset and extracts performance and latency numbers for various batch sizes and sequence lengths in both FP16 with XLA and FP32 without XLA. These numbers are saved at /results/squad_inference_benchmark_bert_<bert_model>.log.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference for pre-training using LAMB optimizer as well as fine tuning for Question Answering. All results are on BERT-large model unless otherwise mentioned. All fine tuning results are on SQuAD v1.1 using a sequence length of 384 unless otherwise mentioned.
Training accuracy results
Training accuracy
Pre-training accuracy: single-node
Our results were obtained by running the scripts/run_pretraining_lamb.sh training script in the TensorFlow 19.06-py3 NGC container.
| DGX System | GPUs | Batch size / GPU: Phase1, Phase2 | Accumulation Steps: Phase1, Phase2 | Time to Train - mixed precision (Hrs) | Final Loss - mixed precision |
|---|---|---|---|---|---|
| DGX1 | 8 | 16, 2 | 512, 2048 | 247.51 | 1.43 |
| DGX2 | 16 | 64, 8 | 64, 256 | 108.16 | 1.58 |
Pre-training accuracy: multi-node
Our results were obtained by running the scripts/run_pretraining_lamb.sh training script in the TensorFlow 19.08-py3 NGC container.
| DGX System | Nodes | Precision | Batch Size/GPU: Phase1, Phase2 | Accumulation Steps: Phase1, Phase2 | Time to Train (Hrs) | Final Loss |
|---|---|---|---|---|---|---|
| DGX1 | 4 | FP16 | 16, 4 | 128, 256 | 62.49 | 1.72 |
| DGX1 | 16 | FP16 | 16, 4 | 32, 64 | 16.58 | 1.76 |
| DGX1 | 32 | FP16 | 16, 2 | 16, 64 | 9.85 | 1.71 |
| DGX2H | 1 | FP16 | 32, 8 | 128, 256 | 69.27 | 1.59 |
| DGX2H | 4 | FP16 | 32, 8 | 32, 64 | 22.17 | 1.60 |
| DGX2H | 16 | FP16 | 32, 8 | 8, 16 | 6.25 | 1.56 |
| DGX2H | 32 | FP16 | 32, 8 | 4, 8 | 3.73 | 1.58 |
| DGX2H | 64 | FP16 | 32, 8 | 2, 4 | 2.44 | 1.64 |
| DGX2H | 64 | FP32 | 32, 4 | 2, 8 | 5.76 | 1.66 |
Note: Time to train includes upto 16 minutes of start up time for every restart. Experiments were run on clusters with a maximum wall clock time of 8 hours.
Fine-tuning accuracy for SQuAD: NVIDIA DGX-2 (16x V100 32G)
Our results were obtained by running the scripts/run_squad.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-2 with 16x V100 32G GPUs.
| GPUs | Batch size / GPU | Accuracy - FP32 | Accuracy - mixed precision | Time to Train - FP32 (Hrs) | Time to Train - mixed precision (Hrs) |
|---|---|---|---|---|---|
| 16 | 4 | 90.94 | 90.84 | 0.44 | 0.16 |
Training stability test
Pre-training stability test: NVIDIA DGX-2 (512x V100 32G)
The following tables compare Final Loss scores across 5 different training runs with different seeds, for both FP16. The runs showcase consistent convergence on all 5 seeds with very little deviation.
| FP16, 512x GPUs | seed 1 | seed 2 | seed 3 | seed 4 | seed 5 | mean | std |
|---|---|---|---|---|---|---|---|
| Final Loss | 1.57 | 1.598 | 1.614 | 1.583 | 1.584 | 1.5898 | 0.017 |
Fine-tuning SQuAD stability test: NVIDIA DGX-2 (16x V100 32G)
The following tables compare F1 scores across 5 different training runs with different seeds, for both FP16 and FP32 respectively. The runs showcase consistent convergence on all 5 seeds with very little deviation.
| FP16, 8x GPUs | seed 1 | seed 2 | seed 3 | seed 4 | seed 5 | mean | std |
|---|---|---|---|---|---|---|---|
| F1 | 90.99 | 90.67 | 91.00 | 90.91 | 90.61 | 90.84 | 0.18 |
| Exact match | 84.12 | 83.60 | 84.02 | 84.05 | 83.47 | 83.85 | 0.29 |
| FP32, 8x GPUs | seed 1 | seed 2 | seed 3 | seed 4 | seed 5 | mean | std |
|---|---|---|---|---|---|---|---|
| F1 | 90.74 | 90.82 | 91.09 | 91.16 | 90.89 | 90.94 | 0.18 |
| Exact match | 83.82 | 83.64 | 84.03 | 84.23 | 84.03 | 83.95 | 0.23 |
Training performance results
Training performance: NVIDIA DGX-1 (8x V100 16G)
Pre-training training performance: single-node on 16G
Our results were obtained by running the scripts/run_pretraining_lamb.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 8x V100 16G GPUs. Performance (in sentences per second) is the steady state throughput.
| GPUs | Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 16,8 | 91.30 | 23.90 | 3.82 | 1.00 | 1.00 |
| 4 | 128 | 16,8 | 297.70 | 86.90 | 3.43 | 3.26 | 3.64 |
| 8 | 128 | 16,8 | 578.60 | 167.80 | 3.45 | 6.34 | 7.02 |
| 1 | 512 | 4,1 | 20.00 | 4.00 | 5.00 | 1.00 | 1.00 |
| 4 | 512 | 4,1 | 66.80 | 13.50 | 4.95 | 3.34 | 3.38 |
| 8 | 512 | 4,1 | 129.50 | 26.30 | 4.92 | 6.48 | 6.58 |
Note: The respective values for FP32 runs that use a batch size of 16, 4 in sequence lengths 128 and 512 respectively are not available due to out of memory errors that arise.
Pre-training training performance: multi-node on 16G
Our results were obtained by running the run.sub training script in the TensorFlow 19.08-py3 NGC container using multiple NVIDIA DGX-1 with 8x V100 16G GPUs. Performance (in sentences per second) is the steady state throughput.
| Nodes | Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 16,4 | 571.877 | 109.366 | 5.229019988 | 1.00 | 1.00 |
| 4 | 128 | 16,4 | 2028.85 | 386.23 | 5.252958082 | 3.55 | 3.53 |
| 16 | 128 | 16,4 | 7299.88 | 1350.49 | 5.405356574 | 12.76 | 12.35 |
| 32 | 128 | 16,4 | 13917.37 | 2555.25 | 5.446578613 | 24.34 | 23.36 |
| 1 | 512 | 4,1 | 128.94 | 25.65 | 5.026900585 | 1.00 | 1.00 |
| 4 | 512 | 4,1 | 466 | 92.36 | 5.045474231 | 3.61 | 3.60 |
| 16 | 512 | 4,1 | 1632 | 325.22 | 5.018141566 | 12.66 | 12.68 |
| 32 | 512 | 4,1 | 3076 | 614.18 | 5.008303755 | 23.86 | 23.94 |
Note: The respective values for FP32 runs that use a batch size of 16, 2 in sequence lengths 128 and 512 respectively are not available due to out of memory errors that arise.
Fine-tuning training performance for SQuAD on 16G
Our results were obtained by running the scripts/run_squad.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 8x V100 16G GPUs. Performance (in sentences per second) is the mean throughput from 2 epochs.
| GPUs | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 3,2 | 17.17 | 7.35 | 2.336054422 | 1.00 | 1.00 |
| 4 | 3,2 | 50.68 | 26.38 | 1.921152388 | 3.59 | 2.95 |
| 8 | 3,2 | 89.98 | 50.17 | 1.793502093 | 6.83 | 5.24 |
Note: The respective values for FP32 runs that use a batch size of 3 are not available due to out of memory errors that arise. Batch size of 3 is only available on using FP16.
To achieve these same results, follow the Quick Start Guide outlined above.
Training performance: NVIDIA DGX-1 (8x V100 32G)
Pre-training training performance: single-node on 32G
Our results were obtained by running the scripts/run_pretraining_lamb.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 8x V100 32G GPUs. Performance (in sentences per second) is the steady state throughput.
| GPUs | Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 48,32 | 140.30 | 34.30 | 4.09 | 1.00 | 1.00 |
| 4 | 128 | 48,32 | 504.40 | 131.70 | 3.83 | 3.60 | 3.84 |
| 8 | 128 | 48,32 | 986.80 | 260.10 | 3.79 | 7.03 | 7.58 |
| 1 | 512 | 8,4 | 25.60 | 6.50 | 3.94 | 1.00 | 1.00 |
| 4 | 512 | 8,4 | 89.90 | 24.70 | 3.64 | 3.51 | 3.80 |
| 8 | 512 | 8,4 | 176.70 | 48.60 | 3.64 | 6.90 | 7.48 |
Note: The respective values for FP32 runs that use a batch size of 48, 8 in sequence lengths 128 and 512 respectively are not available due to out of memory errors that arise.
Fine-tuning training performance for SQuAD on 32G
Our results were obtained by running the scripts/run_squad.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 8x V100 32G GPUs. Performance (in sentences per second) is the mean throughput from 2 epochs.
| GPUs | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 10,4 | 33.79 | 9 | 3.754444444 | 1.00 | 1.00 |
| 4 | 10,4 | 103.38 | 32.5 | 3.180923077 | 3.61 | 3.06 |
| 8 | 10,4 | 172.46 | 63.54 | 2.714195782 | 7.06 | 5.10 |
Note: The respective values for FP32 runs that use a batch size of 10 are not available due to out of memory errors that arise. Batch size of 10 is only available on using FP16.
To achieve these same results, follow the Quick Start Guide outlined above.
Training performance: NVIDIA DGX-2 (16x V100 32G)
Pre-training training performance: single-node on DGX-2 32G
Our results were obtained by running the scripts/run_pretraining_lamb.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-2 with 16x V100 32G GPUs. Performance (in sentences per second) is the steady state throughput.
| GPUs | Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 48,32 | 143.20 | 36.30 | 3.94 | 1.00 | 1.00 |
| 4 | 128 | 48,32 | 538.30 | 141.50 | 3.80 | 3.76 | 3.90 |
| 8 | 128 | 48,32 | 1057.30 | 281.30 | 3.76 | 7.38 | 7.75 |
| 16 | 128 | 48,32 | 1990.70 | 516.80 | 3.85 | 13.90 | 14.24 |
| 1 | 512 | 8,4 | 26.90 | 6.90 | 3.90 | 1.00 | 1.00 |
| 4 | 512 | 8,4 | 96.30 | 26.40 | 3.65 | 3.58 | 3.83 |
| 8 | 512 | 8,4 | 189.00 | 52.40 | 3.61 | 7.03 | 7.59 |
| 16 | 512 | 8,4 | 354.30 | 96.50 | 3.67 | 13.17 | 13.99 |
Note: The respective values for FP32 runs that use a batch size of 48, 8 in sequence lengths 128 and 512 respectively are not available due to out of memory errors that arise.
Pre-training training performance: multi-node on DGX-2H 32G
Our results were obtained by running the run.sub training script in the TensorFlow 19.08-py3 NGC container using multiple NVIDIA DGX-2 with 16x V100 32G GPUs. Performance (in sentences per second) is the steady state throughput.
| Nodes | Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 32,32 | 1758.32 | 602.22 | 2.92 | 1.00 | 1.00 |
| 4 | 128 | 32,32 | 6379.94 | 2261.10 | 2.82 | 3.63 | 3.75 |
| 16 | 128 | 32,32 | 23846.92 | 8875.42 | 2.69 | 13.56 | 14.74 |
| 32 | 128 | 32,32 | 46191.78 | 17445.53 | 2.65 | 26.27 | 28.97 |
| 64 | 128 | 32,32 | 89195.63 | 34263.71 | 2.60 | 50.73 | 56.90 |
| 1 | 512 | 8,4 | 383.35 | 109.97 | 3.49 | 1.00 | 1.00 |
| 4 | 512 | 8,4 | 1408.75 | 400.93 | 3.51 | 3.67 | 3.65 |
| 16 | 512 | 8,4 | 5344.10 | 1559.96 | 3.43 | 13.94 | 14.19 |
| 32 | 512 | 8,4 | 10323.75 | 3061.39 | 3.37 | 26.93 | 27.84 |
| 64 | 512 | 8,4 | 19766.57 | 6029.48 | 3.28 | 51.56 | 54.83 |
Fine-tuning training performance for SQuAD on DGX-2 32G
Our results were obtained by running the scripts/run_squad.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-2 with 16x V100 32G GPUs. Performance (in sentences per second) is the mean throughput from 2 epochs.
| GPUs | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 10,4 | 36.30 | 9.59 | 3.785192909 | 1.00 | 1.00 |
| 4 | 10,4 | 115.67 | 35.46 | 3.261985336 | 3.70 | 3.19 |
| 8 | 10,4 | 197.16 | 68.00 | 2.899411765 | 7.09 | 5.43 |
| 16 | 10,4 | 304.72 | 111.62 | 2.729976707 | 11.64 | 8.39 |
Note: The respective values for FP32 runs that use a batch size of 10 are not available due to out of memory errors that arise. Batch size of 10 is only available on using FP16.
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance results
Inference performance: NVIDIA DGX-1 (1x V100 16G)
Pre-training inference performance on 16G
Our results were obtained by running the scripts/run_pretraining_lamb.sh script in the TensorFlow 19.06-py3 NGC container on NVIDIA DGX-1 with 1x V100 16G GPUs.
| Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) |
|---|---|---|---|---|
| 128 | 8, 8 | 349.51 | 104.31 | 3.35 |
Fine-tuning inference performance for SQuAD on 16G
Our results were obtained by running the scripts/finetune_inference_benchmark.sh script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 1x V100 16G GPUs. Performance numbers (throughput in sentences per second and latency in milliseconds) were averaged from 1024 iterations. Latency is computed as the time taken for a batch to process as they are fed in one after another in the model ie no pipelining.
BERT LARGE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 95.87 | 1.433462919 | 10.43 | 10.61 | 10.71 | 11.27 |
| 128 | 2 | 168.02 | 1.871046771 | 11.9 | 12.08 | 12.18 | 12.32 |
| 128 | 4 | 263.08 | 2.617451 | 15.2 | 14.86 | 14.95 | 15.55 |
| 128 | 8 | 379.78 | 3.414366628 | 21.07 | 20.94 | 21.03 | 21.49 |
| 384 | 1 | 67.52 | 2.274932615 | 14.81 | 14.93 | 15.05 | 15.38 |
| 384 | 2 | 93.8 | 2.929419113 | 21.32 | 20.75 | 20.83 | 21.43 |
| 384 | 4 | 118.97 | 3.397201599 | 33.62 | 33.17 | 33.37 | 33.85 |
| 384 | 8 | 138.43 | 3.838879645 | 57.79 | 57 | 57.38 | 58.19 |
BERT LARGE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 66.88 | 14.95 | 14.96 | 15.41 | 18.02 |
| 128 | 2 | 89.8 | 22.27 | 22.46 | 22.53 | 22.84 |
| 128 | 4 | 100.51 | 39.8 | 39.91 | 40.06 | 41.04 |
| 128 | 8 | 111.23 | 71.92 | 72.42 | 72.58 | 73.63 |
| 384 | 1 | 29.68 | 33.7 | 33.85 | 33.91 | 34.62 |
| 384 | 2 | 32.02 | 62.47 | 63.06 | 63.28 | 63.66 |
| 384 | 4 | 35.02 | 114.21 | 114.69 | 114.82 | 115.85 |
| 384 | 8 | 36.06 | 221.86 | 222.7 | 223.03 | 223.53 |
BERT BASE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 204.33 | 1.459187317 | 4.89 | 5.14 | 5.32 | 5.54 |
| 128 | 2 | 375.19 | 1.779501043 | 5.33 | 5.47 | 5.58 | 5.87 |
| 128 | 4 | 606.98 | 2.198645271 | 6.59 | 6.49 | 6.55 | 6.83 |
| 128 | 8 | 902.6 | 2.69023278 | 8.86 | 8.62 | 8.72 | 9.22 |
| 384 | 1 | 154.33 | 1.990070922 | 6.48 | 6.59 | 6.65 | 7.04 |
| 384 | 2 | 225.7 | 2.386087324 | 8.86 | 8.45 | 8.53 | 9.16 |
| 384 | 4 | 317.93 | 3.044431677 | 12.58 | 12.34 | 12.39 | 13.01 |
| 384 | 8 | 393.44 | 3.672547372 | 20.33 | 20.06 | 20.38 | 21.38 |
BERT BASE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 140.03 | 7.14 | 7.6 | 7.78 | 7.97 |
| 128 | 2 | 210.84 | 9.49 | 9.59 | 9.65 | 10.57 |
| 128 | 4 | 276.07 | 14.49 | 14.61 | 14.71 | 15.16 |
| 128 | 8 | 335.51 | 23.84 | 23.79 | 23.89 | 24.94 |
| 384 | 1 | 77.55 | 12.89 | 13.01 | 13.05 | 14.26 |
| 384 | 2 | 94.59 | 21.14 | 21.14 | 21.23 | 21.86 |
| 384 | 4 | 104.43 | 38.3 | 38.38 | 38.45 | 39.15 |
| 384 | 8 | 107.13 | 74.68 | 75.05 | 75.19 | 76.2 |
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance: NVIDIA DGX-1 (1x V100 32G)
Pre-training inference performance on 32G
Our results were obtained by running the scripts/run_pretraining_lamb.sh script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 1x V100 32G GPUs.
| Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) |
|---|---|---|---|---|
| 128 | 8, 8 | 345.50 | 101.84 | 3.39 |
Fine-tuning inference performance for SQuAD on 32G
Our results were obtained by running the scripts/finetune_inference_benchmark.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-1 with 1x V100 32G GPUs. Performance numbers (throughput in sentences per second and latency in milliseconds) were averaged from 1024 iterations. Latency is computed as the time taken for a batch to process as they are fed in one after another in the model ie no pipelining.
BERT LARGE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 87.75 | 1.352913969 | 11.4 | 11.46 | 18.77 | 19.06 |
| 128 | 2 | 159.87 | 1.833161335 | 12.51 | 12.69 | 12.79 | 12.98 |
| 128 | 4 | 254.65 | 2.622014003 | 15.71 | 15.49 | 15.59 | 16.03 |
| 128 | 8 | 365.51 | 3.377783939 | 21.89 | 21.72 | 21.94 | 23.79 |
| 384 | 1 | 63.11 | 2.153924915 | 15.84 | 17.3 | 19.22 | 19.37 |
| 384 | 2 | 89.61 | 2.884132604 | 22.32 | 21.83 | 21.96 | 23.8 |
| 384 | 4 | 114.9 | 3.395390071 | 34.81 | 34.33 | 34.47 | 35.15 |
| 384 | 8 | 132.79 | 3.814708417 | 60.25 | 59.4 | 59.77 | 60.7 |
BERT LARGE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 64.86 | 15.42 | 16.32 | 17.55 | 20.89 |
| 128 | 2 | 87.21 | 22.93 | 23.06 | 24.17 | 31.93 |
| 128 | 4 | 97.12 | 41.19 | 41.38 | 41.5 | 44.13 |
| 128 | 8 | 108.21 | 73.93 | 74.34 | 74.48 | 74.77 |
| 384 | 1 | 29.3 | 34.13 | 34.21 | 34.25 | 34.76 |
| 384 | 2 | 31.07 | 64.38 | 64.83 | 64.95 | 65.42 |
| 384 | 4 | 33.84 | 118.22 | 119.01 | 119.57 | 120.06 |
| 384 | 8 | 34.81 | 229.84 | 230.72 | 231.22 | 232.96 |
BERT BASE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 198.72 | 1.393352966 | 5.03 | 5.3 | 5.47 | 5.69 |
| 128 | 2 | 338.44 | 1.611158717 | 5.91 | 6.04 | 9.77 | 9.94 |
| 128 | 4 | 599.62 | 2.24804109 | 6.67 | 6.6 | 6.66 | 6.83 |
| 128 | 8 | 858.56 | 2.63370042 | 9.32 | 10.01 | 10.04 | 10.39 |
| 384 | 1 | 150.28 | 1.948146228 | 6.65 | 6.76 | 6.82 | 7.21 |
| 384 | 2 | 200.68 | 2.200197347 | 9.97 | 9.88 | 9.94 | 10.08 |
| 384 | 4 | 305.72 | 3.01707293 | 13.08 | 12.86 | 12.97 | 13.71 |
| 384 | 8 | 373.64 | 3.61249154 | 21.41 | 21.98 | 22.03 | 22.61 |
BERT BASE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 142.62 | 7.01 | 7.07 | 7.44 | 9.23 |
| 128 | 2 | 210.06 | 9.52 | 9.63 | 9.69 | 10.22 |
| 128 | 4 | 266.73 | 15 | 15.77 | 15.91 | 16.79 |
| 128 | 8 | 325.99 | 24.54 | 24.52 | 24.6 | 25 |
| 384 | 1 | 77.14 | 12.96 | 13.01 | 13.03 | 13.67 |
| 384 | 2 | 91.21 | 21.93 | 21.93 | 21.99 | 22.31 |
| 384 | 4 | 101.33 | 39.47 | 39.69 | 39.82 | 40.88 |
| 384 | 8 | 103.43 | 77.34 | 77.76 | 77.9 | 78.45 |
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance: NVIDIA DGX-2 (1x V100 32G)
Pre-training inference performance on DGX-2 32G
Our results were obtained by running the scripts/run_pretraining_lamb.sh script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-2 with 1x V100 32G GPUs.
| Sequence Length | Batch size / GPU: mixed precision, FP32 | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 to mixed precision) |
|---|---|---|---|---|
| 128 | 8, 8 | 366.24 | 107.88 | 3.39 |
Fine-tuning inference performance for SQuAD on DGX-2 32G
Our results were obtained by running the scripts/finetune_inference_benchmark.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA DGX-2 with 1x V100 32G GPUs. Performance numbers (throughput in sentences per second and latency in milliseconds) were averaged from 1024 iterations. Latency is computed as the time taken for a batch to process as they are fed in one after another in the model ie no pipelining.
BERT LARGE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 96.22 | 1.371045882 | 10.39 | 10.78 | 10.9 | 11.43 |
| 128 | 2 | 171.66 | 1.835935829 | 11.65 | 11.86 | 12.04 | 12.45 |
| 128 | 4 | 262.89 | 2.566032211 | 15.22 | 15.13 | 15.24 | 15.91 |
| 128 | 8 | 394.23 | 3.441253492 | 20.29 | 20.22 | 20.6 | 22.19 |
| 384 | 1 | 69.69 | 2.278195489 | 14.35 | 14.39 | 14.58 | 15.68 |
| 384 | 2 | 96.35 | 2.909118357 | 20.76 | 20.25 | 20.32 | 21.54 |
| 384 | 4 | 124.06 | 3.42612538 | 32.24 | 31.87 | 32.14 | 33.02 |
| 384 | 8 | 144.28 | 3.876410532 | 55.45 | 54.77 | 55.16 | 55.93 |
BERT LARGE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 70.18 | 14.25 | 14.7 | 14.88 | 15.35 |
| 128 | 2 | 93.5 | 21.39 | 21.83 | 22.04 | 22.85 |
| 128 | 4 | 102.45 | 39.04 | 39.28 | 39.42 | 40.5 |
| 128 | 8 | 114.56 | 69.83 | 70.5 | 70.74 | 72.78 |
| 384 | 1 | 30.59 | 32.69 | 33.14 | 33.32 | 33.86 |
| 384 | 2 | 33.12 | 60.38 | 60.91 | 61.12 | 61.67 |
| 384 | 4 | 36.21 | 110.46 | 111.1 | 111.26 | 112.15 |
| 384 | 8 | 37.22 | 214.95 | 215.69 | 216.13 | 217.96 |
BERT BASE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 207.01 | 1.455050257 | 4.83 | 5.23 | 5.38 | 5.59 |
| 128 | 2 | 405.92 | 1.808429119 | 4.93 | 4.99 | 5.04 | 5.2 |
| 128 | 4 | 646.8 | 2.258695349 | 6.18 | 6.06 | 6.14 | 6.55 |
| 128 | 8 | 909.41 | 2.616781285 | 8.8 | 8.86 | 8.96 | 9.52 |
| 384 | 1 | 153.97 | 1.959653812 | 6.49 | 6.88 | 7.01 | 7.2 |
| 384 | 2 | 229.46 | 2.366298855 | 8.72 | 8.57 | 8.67 | 8.97 |
| 384 | 4 | 333.2 | 3.078913325 | 12 | 11.74 | 11.85 | 12.86 |
| 384 | 8 | 403.02 | 3.646579805 | 19.85 | 19.83 | 20 | 21.11 |
BERT BASE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 142.27 | 7.03 | 7.39 | 7.45 | 11.7 |
| 128 | 2 | 224.46 | 8.91 | 9 | 9.08 | 9.66 |
| 128 | 4 | 286.36 | 13.97 | 14.46 | 14.52 | 14.82 |
| 128 | 8 | 347.53 | 23.02 | 23.23 | 23.4 | 24.12 |
| 384 | 1 | 78.57 | 12.73 | 13.01 | 13.1 | 14.06 |
| 384 | 2 | 96.97 | 20.62 | 21 | 21.15 | 21.82 |
| 384 | 4 | 108.22 | 36.96 | 37.05 | 37.18 | 38.12 |
| 384 | 8 | 110.52 | 72.38 | 73.06 | 73.32 | 74.64 |
Inference performance: NVIDIA Tesla T4 (1x T4 16G)
Fine-tuning inference performance for SQuAD on Tesla T4 16G
Our results were obtained by running the scripts/finetune_inference_benchmark.sh training script in the TensorFlow 19.08-py3 NGC container on NVIDIA Tesla T4 with 1x T4 16G GPUs. Performance numbers (throughput in sentences per second and latency in milliseconds) were averaged from 1024 iterations. Latency is computed as the time taken for a batch to process as they are fed in one after another in the model ie no pipelining.
BERT LARGE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 54.53 | 1.552234557 | 18.34 | 19.09 | 19.28 | 21.74 |
| 128 | 2 | 95.59 | 2.521498285 | 20.92 | 21.86 | 22.61 | 23.33 |
| 128 | 4 | 133.2 | 3.434760186 | 30.03 | 30.32 | 30.43 | 31.06 |
| 128 | 8 | 168.85 | 4.352926012 | 47.38 | 48.21 | 48.56 | 49.25 |
| 384 | 1 | 33.58 | 2.87008547 | 29.78 | 30.3 | 30.46 | 31.69 |
| 384 | 2 | 41.31 | 3.576623377 | 48.41 | 49.03 | 49.26 | 50.04 |
| 384 | 4 | 47.08 | 3.94635373 | 84.96 | 86.88 | 87.38 | 88.3 |
| 384 | 8 | 50.08 | 4.254885302 | 159.76 | 162.37 | 163.23 | 165.79 |
BERT LARGE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 35.13 | 28.46 | 29.89 | 30.12 | 30.6 |
| 128 | 2 | 37.91 | 52.76 | 54.01 | 54.29 | 54.84 |
| 128 | 4 | 38.78 | 103.14 | 105.39 | 106.05 | 107.4 |
| 128 | 8 | 38.79 | 206.22 | 209.63 | 210.2 | 211.5 |
| 384 | 1 | 11.7 | 85.5 | 87.18 | 87.43 | 88 |
| 384 | 2 | 11.55 | 173.19 | 176.13 | 177.02 | 178.4 |
| 384 | 4 | 11.93 | 335.41 | 340.26 | 341.76 | 343.54 |
| 384 | 8 | 11.77 | 679.77 | 686.01 | 686.79 | 689.24 |
BERT BASE FP16
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Throughput speedup (FP32 to mixed precision) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|---|
| 128 | 1 | 13.22 | 1.552234557 | 18.34 | 19.09 | 19.28 | 21.74 |
| 128 | 2 | 12.97 | 2.521498285 | 20.92 | 21.86 | 22.61 | 23.33 |
| 128 | 4 | 13.21 | 3.434760186 | 30.03 | 30.32 | 30.43 | 31.06 |
| 128 | 8 | 18.82 | 4.352926012 | 47.38 | 48.21 | 48.56 | 49.25 |
| 384 | 1 | 15.44 | 2.87008547 | 29.78 | 30.3 | 30.46 | 31.69 |
| 384 | 2 | 19.38 | 3.576623377 | 48.41 | 49.03 | 49.26 | 50.04 |
| 384 | 4 | 30.84 | 3.94635373 | 84.96 | 86.88 | 87.38 | 88.3 |
| 384 | 8 | 56.31 | 4.254885302 | 159.76 | 162.37 | 163.23 | 165.79 |
BERT BASE FP32
| Sequence Length | Batch Size | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-90%(ms) | Latency-95%(ms) | Latency-99%(ms) |
|---|---|---|---|---|---|---|
| 128 | 1 | 64.15 | 15.59 | 19.77 | 21.03 | 21.82 |
| 128 | 2 | 110.69 | 18.07 | 18.92 | 20.77 | 21.6 |
| 128 | 4 | 125.8 | 31.8 | 32.82 | 33.11 | 33.93 |
| 128 | 8 | 127.55 | 62.72 | 63.9 | 64.28 | 65.25 |
| 384 | 1 | 35.46 | 28.2 | 28.83 | 28.95 | 29.43 |
| 384 | 2 | 37.15 | 53.83 | 54.75 | 55.08 | 56.01 |
| 384 | 4 | 36.86 | 108.53 | 110.57 | 111.16 | 112.48 |
| 384 | 8 | 36.1 | 221.61 | 225.94 | 226.94 | 228.58 |
To achieve these same results, follow the Quick Start Guide outlined above.
Release notes
Changelog
November 2019
- Pre-training and Finetuning on BioMedical tasks and corpus
October 2019
- Disabling Grappler Optimizations for improved performance
September 2019
- Pre-training using LAMB
- Multi Node support
- Fine Tuning support for GLUE (CoLA, MNLI, MRPC)
July 2019
- Results obtained using 19.06
- Inference Studies using TensorRT Inference Server
March 2019
- Initial release
Known issues
- There is a known performance regression with the 19.08 release on Tesla V100 boards with 16 GB memory, smaller batch sizes may be a better choice for this model on these GPUs with the 19.08 release. 32 GB GPUs are not affected.