|
|
||
|---|---|---|
| .. | ||
| scripts | ||
| README.md | ||
| run_squad_trtis_client.py | ||
Deploying the BERT model using TensorRT Inference Server
The NVIDIA TensorRT Inference Server provides a datacenter and cloud inferencing solution optimized for NVIDIA GPUs. The server provides an inference service via an HTTP or gRPC endpoint, allowing remote clients to request inferencing for any number of GPU or CPU models being managed by the server. This folder contains detailed performance analysis as well as scripts to run SQuAD fine-tuning on BERT model using TensorRT Inference Server.
Table Of Contents
- TensorRT Inference Server Overview
- Performance analysis for TensorRT Inference Server
- Running the TensorRT Inference Server and client
TensorRT Inference Server Overview
A typical TensorRT Inference Server pipeline can be broken down into the following 8 steps:
- Client serializes the inference request into a message and sends it to the server (Client Send)
- Message travels over the network from the client to the server (Network)
- Message arrives at server, and is deserialized (Server Receive)
- Request is placed on the queue (Server Queue)
- Request is removed from the queue and computed (Server Compute)
- Completed request is serialized in a message and sent back to the client (Server Send)
- Completed message travels over network from the server to the client (Network)
- Completed message is deserialized by the client and processed as a completed inference request (Client Receive)
Generally, for local clients, steps 1-4 and 6-8 will only occupy a small fraction of time, compared to steps 5-6. As backend deep learning systems like BERT are rarely exposed directly to end users, but instead only interfacing with local front-end servers, for the sake of BERT, we can consider that all clients are local. In this section, we will go over how to launch TensorRT Inference Server and client and get the best performant solution that fits your specific application needs.
Note: The following instructions are run from outside the container and call docker run commands as required.
Performance analysis for TensorRT Inference Server
Based on the figures 1 and 2 below, we recommend using the Dynamic Batcher with max_batch_size = 8, max_queue_delay_microseconds as large as possible to fit within your latency window (the values used below are extremely large to exaggerate their effect), and only 1 instance of the engine. The largest improvements to both throughput and latency come from increasing the batch size due to efficiency gains in the GPU with larger batches. The Dynamic Batcher combines the best of both worlds by efficiently batching together a large number of simultaneous requests, while also keeping latency down for infrequent requests. We recommend only 1 instance of the engine due to the negligible improvement to throughput at the cost of significant increases in latency. Many models can benefit from multiple engine instances but as the figures below show, that is not the case for this model.

Figure 1: Latency vs Throughput for BERT Base, FP16, Sequence Length = 128 using various configurations available in TensorRT Inference Server
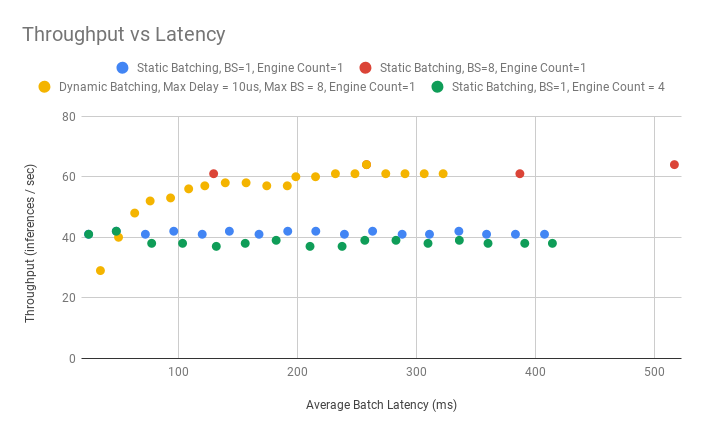
Figure 2: Latency vs Throughput for BERT Large, FP16, Sequence Length = 384 using various configurations available in TensorRT Inference Server
Advanced Details
This section digs deeper into the performance numbers and configurations corresponding to running TensorRT Inference Server for BERT fine tuning for Question Answering. It explains the tradeoffs in selecting maximum batch sizes, batching techniques and number of inference engines on the same GPU to understand how we arrived at the optimal configuration specified previously.
Results can be reproduced by running generate_figures.sh. It exports the TensorFlow BERT model as a tensorflow_savedmodel that TensorRT Inference Server accepts, builds a matching TensorRT Inference Server model config, starts the server on localhost in a detached state and runs perf_client for various configurations.
bash trtis/scripts/generate_figures.sh <bert_model> <seq_length> <precision> <init_checkpoint>
All results below are obtained on a single DGX-1 V100 32GB GPU for BERT Base, Sequence Length = 128 and FP16 precision running on a local server. Latencies are indicated by bar plots using the left axis. Throughput is indicated by the blue line plot using the right axis. X-axis indicates the concurrency - the maximum number of inference requests that can be in the pipeline at any given time. For example, when the concurrency is set to 1, the client waits for an inference request to be completed (Step 8) before it sends another to the server (Step 1). A high number of concurrent requests can reduce the impact of network latency on overall throughput.
Maximum batch size
As we can see in Figure 3, the throughput at BS=1, Client Concurrent Requests = 64 is 119 and in Figure 4, the throughput at BS=8, Client Concurrent Requests = 8 is 517, respectively giving a speedup of ~4.3x
Note: We compare BS=1, Client Concurrent Requests = 64 to BS=8, Client Concurrent Requests = 8 to keep the Total Number of Outstanding Requests equal between the two different modes. Where Total Number of Outstanding Requests = Batch Size * Client Concurrent Requests. This is also why there are 8 times as many bars on the BS=1 chart than the BS=8 chart.
Increasing the batch size from 1 to 8 results in an increase in compute time by 1.8x (8.38ms to 15.46ms) showing that computation is more efficient at higher batch sizes. Hence, an optimal batch size would be the maximum batch size that can both fit in memory and is within the preferred latency threshold.

Figure 3: Latency & Throughput vs Concurrency at Batch size = 1

Figure 4: Latency & Throughput vs Concurrency at Batch size = 8
Batching techniques
Static batching is a feature of the inference server that allows inference requests to be served as they are received. It is preferred in scenarios where low latency is desired at the cost of throughput when the GPU is under utilized.
Dynamic batching is a feature of the inference server that allows inference requests to be combined by the server, so that a batch is created dynamically, resulting in an increased throughput. It is preferred in scenarios where we would like to maximize throughput and GPU utilization at the cost of higher latencies. You can set the Dynamic Batcher parameters max_queue_delay_microseconds to indicate the maximum amount of time you are willing to wait and ‘preferred_batchsize’ to indicate your optimal batch sizes in the TensorRT Inference Server model config.
Figures 5 and 6 emphasize the increase in overall throughput with dynamic batching. At low numbers of concurrent requests, the increased throughput comes at the cost of increasing latency as the requests are queued up to max_queue_delay_microseconds. The effect of preferred_batchsize for dynamic batching is visually depicted by the dip in Server Queue time at integer multiples of the preferred batch sizes. At higher numbers of concurrent requests, observe that the throughput approach a maximum limit as we saturate the GPU utilization.

Figure 5: Latency & Throughput vs Concurrency using Static Batching at Batch size = 1
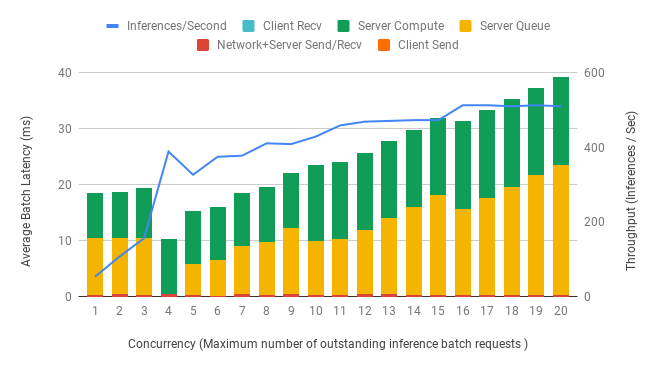
Figure 6: Latency & Throughput vs Concurrency using Dynamic Batching at Batch size = 1, preferred_batchsize = [4, 8] and max_queue_delay_microseconds = 5000
Model execution instance count
TensorRT Inference Server enables us to launch multiple engines in separate CUDA streams by setting the instance_group_count parameter to improve both latency and throughput. Multiple engines are useful when the model doesn’t saturate the GPU allowing the GPU to run multiple instances of the model in parallel.
Figures 7 and 8 show a drop in queue time as more models are available to serve an inference request. However, this is countered by an increase in compute time as multiple models compete for resources. Since BERT is a large model which utilizes the majority of the GPU, the benefit to running multiple engines is not seen.

Figure 7: Latency & Throughput vs Concurrency at Batch size = 1, Engine Count = 1 (One copy of the model loaded in GPU memory)

Figure 8: Latency & Throughput vs Concurrency at Batch size = 1, Engine count = 4 (Four copies the model loaded in GPU memory)
Running the TensorRT Inference Server and client
The run_trtis.sh script exports the TensorFlow BERT model as a tensorflow_savedmodel that TensorRT Inference Server accepts, builds a matching TensorRT Inference Server model config, starts the server on local host in a detached state, runs client and then evaluates the validity of predictions on the basis of exact match and F1 score all in one step.
bash trtis/scripts/run_trtis.sh <init_checkpoint> <batch_size> <precision> <use_xla> <seq_length> <doc_stride> <bert_model> <squad_version> <trtis_version_name> <trtis_model_name> <trtis_export_model> <trtis_dyn_batching_delay> <trtis_engine_count> <trtis_model_overwrite>