26 KiB
Variational Autoencoder for Collaborative Filtering for TensorFlow
This repository provides a script and recipe to train the Variational Autoencoder model for TensorFlow to achieve state-of-the-art accuracy on a Collaborative Filtering task and is tested and maintained by NVIDIA.
Table Of Contents
- Model overview
- Setup
- Quick Start Guide
- Advanced
- Performance
- Release notes
Model overview
The Variational Autoencoder (VAE) shown here is an optimized implementation of the architecture first described in Variational Autoencoders for Collaborative Filtering and can be used for recommendation tasks. The main differences between this model and the original one are the performance optimizations, such as using sparse matrices, mixed precision, larger mini-batches and multiple GPUs. These changes enabled us to achieve a significantly higher speed while maintaining the same accuracy. Because of our fast implementation, we've also been able to carry out an extensive hyperparameter search to slightly improve the accuracy metrics.
When using Variational Autoencoder for Collaborative Filtering (VAE-CF), you can quickly train a recommendation model for the collaborative filtering task. The required input data consists of pairs of user-item IDs for each interaction between a user and an item. With a trained model, you can run inference to predict what items is a new user most likely to interact with.
This model is trained with mixed precision using Tensor Cores on NVIDIA Volta, Turing and Ampere GPUs. Therefore, researchers can get results 1.9x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
This implementation has been initially developed as an educational project at the University of Warsaw by Albert Cieślak, Michał Filipiuk, Frederic Grabowski and Radosław Rowicki.
Model architecture
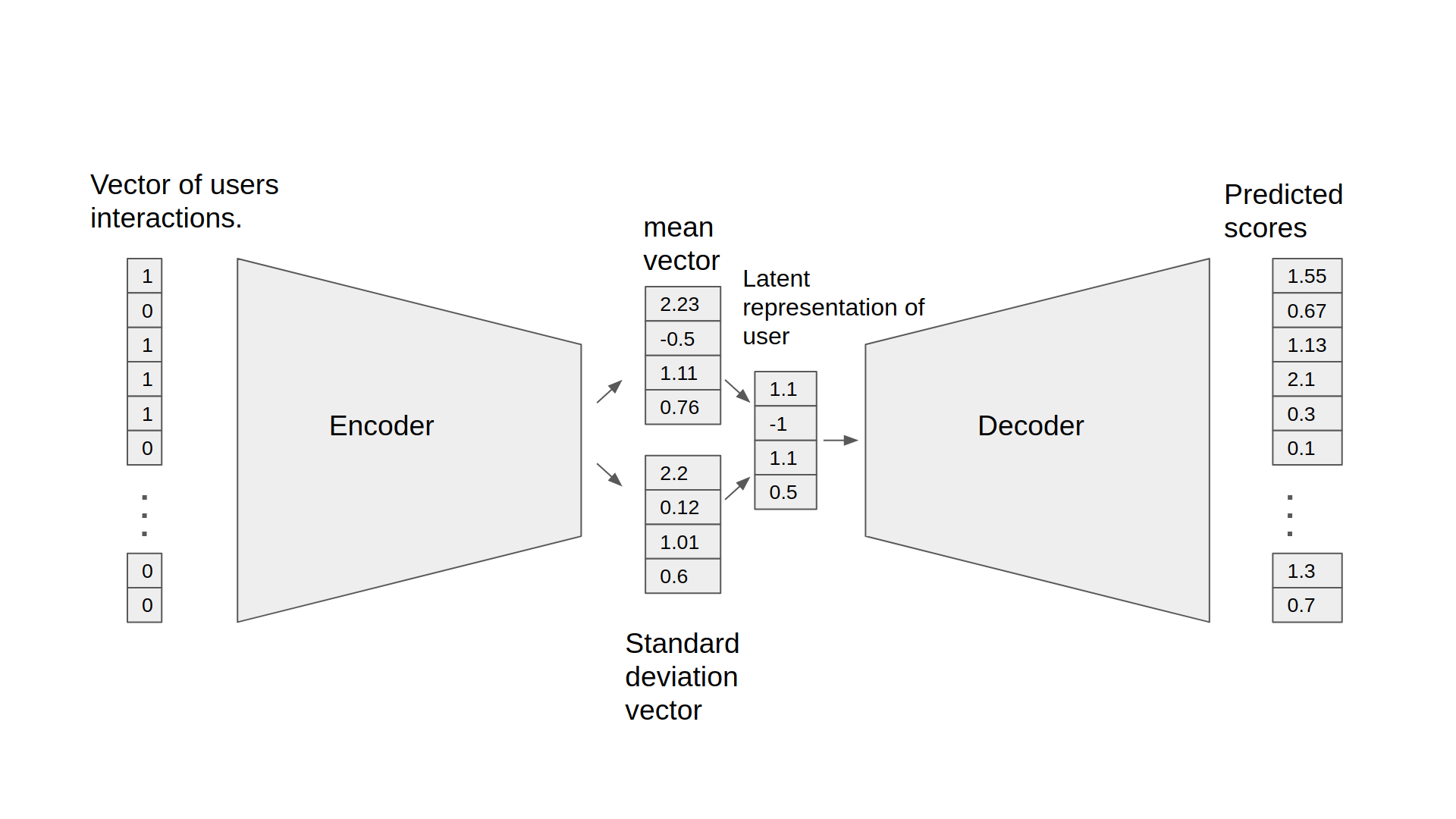
Figure 1. The architecture of the VAE-CF model
The Variational Autoencoder is a neural network that provides collaborative filtering based on implicit feedback. Specifically, it provides product recommendations based on user and item interactions. The training data for this model should contain a sequence of (user ID, item ID) pairs indicating that the specified user has interacted with the specified item.
The model consists of two parts: the encoder and the decoder. The encoder transforms the vector, which contains the interactions for a specific user, into a n-dimensional variational distribution. We can then use this variational distribution to obtain a latent representation of a user. This latent representation is then fed into the decoder. The result is a vector of item interaction probabilities for a particular user.
Default configuration
The following features were implemented in this model:
- Sparse matrix support
- Data-parallel multi-GPU training
- Dynamic loss scaling with backoff for tensor cores (mixed precision) training
Feature support matrix
The following features are supported by this model:
| Feature | VAE-CF |
|---|---|
| Horovod Multi-GPU (NCCL) | Yes |
| Automatic mixed precision (AMP) | Yes |
Features
Horovod:
Horovod is a distributed training framework for TensorFlow, Keras, PyTorch and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Multi-GPU training with Horovod:
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta, Turing, and NVIDIA Ampere GPU architectures automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
Mixed precision is enabled in TensorFlow by using the Automatic Mixed Precision (TF-AMP) extension which casts variables to half-precision upon retrieval, while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In TensorFlow, loss scaling can be applied statically by using simple multiplication of loss by a constant value or automatically, by TF-AMP. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
To enable mixed precision, you can simply add the values to the environmental variables inside your training script:
- Enable TF-AMP graph rewrite:
os.environ["TF_ENABLE_AUTO_MIXED_PRECISION_GRAPH_REWRITE"] = '1'
- Enable Automated Mixed Precision:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
To enable mixed precision in VAE-CF, run the main.py script with the --amp flag.
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Setup
The following section lists the requirements that you need to meet in order to start training the VAE-CF model.
Requirements
This repository contains Dockerfile which extends the Tensorflow NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
- NVIDIA Docker
- TensorFlow-1 20.06+ NGC container
- Supported GPUs:
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running TensorFlow
For those unable to use the TensorFlow NGC container, to set up the required environment or create your own container, see the versioned NVIDIA Container Support Matrix.
Quick Start Guide
To train your model using mixed or TF32 precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the VAE-CF model on the MovieLens 20m dataset. For the specifics concerning training and inference, see the Advanced section.
-
Clone the repository. git clone https://github.com/NVIDIA/DeepLearningExamples cd DeepLearningExamples/Tensorflow/Recommendation/VAE_CF
-
Build the VAE TensorFlow NGC container.
docker build . -t vae -
Launch the VAE-CF TensorFlow Docker container.
docker run -it --rm --runtime=nvidia -v /data/vae-cf:/data vae /bin/bash -
Downloading the dataset: Here we use the MovieLens 20m dataset.
-
If you do not have the dataset downloaded: Run the commands below to download and extract the MovieLens dataset to the
/data/ml-20m/extracted/folder.cd /data mkdir ml-20m cd ml-20m mkdir extracted cd extracted wget http://files.grouplens.org/datasets/movielens/ml-20m.zip unzip ml-20m.zip -
If you already have the dataset downloaded and unzipped elsewhere: Run the below commands to first exit the current VAE-CF Docker container and then Restart the VAE-CF Docker Container (like in Step 3 above) by mounting the MovieLens dataset location
exit docker run -it --rm --runtime=nvidia -v /data/vae-cf:/data -v <ml-20m folder path>:/data/ml-20m/extracted/ml-20m vae /bin/bashwhere, the unzipped MovieLens dataset is at
<ml-20m folder path>
-
-
Prepare the dataset.
python prepare_dataset.py -
Start training on 8 GPUs.
mpirun --bind-to numa --allow-run-as-root -np 8 -H localhost:8 python main.py --train --amp --checkpoint_dir ./checkpoints -
Start validation/evaluation.
The model is exported to the default
model_dirand can be loaded and tested using:python main.py --test --amp --checkpoint_dir ./checkpoints
Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
Scripts and sample code
The main.py script provides an entry point to all the provided functionalities. This includes running training, testing and inference. The behavior of the script is controlled by command-line arguments listed below in the Parameters section. The prepare_dataset.py script can be used to preprocess the MovieLens 20m dataset.
Most of the deep learning logic is implemented in the vae/models subdirectory. The vae/load subdirectory contains the code for preprocessing the dataset. The vae/metrics subdirectory provides functions for computing the validation metrics such as recall and NDCG.
Parameters
The most important command-line parameters include:
--data_dirwhich specifies the directory inside the docker container where the data will be stored, overriding the default location/data--checkpoint_dirwhich controls if and where the checkpoints will be stored--ampfor enabling mixed precision training
There are also multiple parameters controlling the various hyperparameters of the training process, such as the learning rate, batch size etc.
Command-line options
To see the full list of available options and their descriptions, use the -h or --help command-line option, for example:
python main.py --help
usage: main.py [-h] [--train] [--test] [--inference_benchmark]
[--amp] [--epochs EPOCHS]
[--batch_size_train BATCH_SIZE_TRAIN]
[--batch_size_validation BATCH_SIZE_VALIDATION]
[--validation_step VALIDATION_STEP]
[--warm_up_epochs WARM_UP_EPOCHS]
[--total_anneal_steps TOTAL_ANNEAL_STEPS]
[--anneal_cap ANNEAL_CAP] [--lam LAM] [--lr LR] [--beta1 BETA1]
[--beta2 BETA2] [--top_results TOP_RESULTS] [--xla] [--trace]
[--activation ACTIVATION] [--log_path LOG_PATH] [--seed SEED]
[--data_dir DATA_DIR] [--checkpoint_dir CHECKPOINT_DIR]
Train a Variational Autoencoder for Collaborative Filtering in TensorFlow
optional arguments:
-h, --help show this help message and exit
--train Run training of VAE
--test Run validation of VAE
--inference_benchmark
Benchmark the inference throughput and latency
--amp Enable Automatic Mixed Precision
--epochs EPOCHS Number of epochs to train
--batch_size_train BATCH_SIZE_TRAIN
Global batch size for training
--batch_size_validation BATCH_SIZE_VALIDATION
Used both for validation and testing
--validation_step VALIDATION_STEP
Train epochs for one validation
--warm_up_epochs WARM_UP_EPOCHS
Number of epochs to omit during benchmark
--total_anneal_steps TOTAL_ANNEAL_STEPS
Number of annealing steps
--anneal_cap ANNEAL_CAP
Annealing cap
--lam LAM Regularization parameter
--lr LR Learning rate
--beta1 BETA1 Adam beta1
--beta2 BETA2 Adam beta2
--top_results TOP_RESULTS
Number of results to be recommended
--xla Enable XLA
--trace Save profiling traces
--activation ACTIVATION
Activation function
--log_path LOG_PATH Path to the detailed JSON log from to be created
--seed SEED Random seed for TensorFlow and numpy
--data_dir DATA_DIR Directory for storing the training data
--checkpoint_dir CHECKPOINT_DIR
Path for saving a checkpoint after the training
Getting the data
The VA-CF model was trained on the MovieLens 20M dataset. The dataset can be preprocessed simply by running: python prepare_dataset.py in the Docker container. By default, the dataset will be stored in the /data directory. If you want to store the data in a different location, you can pass the desired location to the --data_dir argument.
Dataset guidelines
As a Collaborative Filtering model, VAE-CF only uses information about which user interacted with which item. For the MovieLens dataset, this means that a particular user has positively reviewed a particular movie. VAE-CF can be adapted to any other collaborative filtering task. The input to the model is generally a list of all interactions between users and items. One column of the CSV should contain user IDs, while the other should contain item IDs. Preprocessing for the MovieLens 20M dataset is provided in the vae/load/preprocessing.py file.
Training process
The training can be started by running the main.py script with the train argument. The resulting checkpoints containing the trained model weights are then stored in the directory specified by the --checkpoint_dir directory (by default no checkpoints are saved).
Additionally, a command-line argument called --results_dir (by default None) specifies where to save the following statistics in a JSON format:
- a complete list of command-line arguments saved as
<results_dir>/args.json, and - a dictionary of validation metrics and performance metrics recorded during training.
The main validation metric used is NDCG@100. Following the original VAE-CF paper we also report numbers for Recall@20 and Recall@50.
Multi-GPU training uses horovod.
Mixed precision support is controlled by the --amp command-line flag. It enables TensorFlow’s Automatic Mixed Precision mode.
Inference process
Inference on a trained model can be run by passing the --inference_benchmark argument to the main.py script
python main.py --inference_benchmark [--amp] --checkpoint_dir ./checkpoints
This will generate a user with a collection of random items that they interacted with and run inference for that user multiple times to measure latency and throughput.
Performance
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA’s latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark the training performance, run:
mpirun --bind-to numa --allow-run-as-root -np 8 -H localhost:8 python main.py --train [--amp]
Inference performance benchmark
To benchmark the inference performance, run:
python main.py --inference_benchmark [--amp]
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
All training performance results were obtained by running:
mpirun --bind-to numa --allow-run-as-root -np <gpus> -H localhost:8 python main.py --train [--amp]
in the TensorFlow 20.06 NGC container.
Training accuracy: NVIDIA DGX A100 (8x A100 40GB)
| GPUs | Batch size / GPU | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 [s] | Time to train - mixed precision [s] | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 24,576 | 0.430298 | 0.430398 | 112.8 | 109.4 | 1.03 |
| 8 | 3,072 | 0.430897 | 0.430353 | 25.9 | 30.4 | 0.85 |
Training accuracy: NVIDIA DGX-1 (8x V100 32GB)
| GPUs | Batch size / GPU | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 [s] | Time to train - mixed precision [s] | Time to train speedup (FP32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 24,576 | 0.430592 | 0.430525 | 346.5 | 186.5 | 1.86 |
| 8 | 3,072 | 0.430753 | 0.431202 | 59.1 | 42.2 | 1.40 |
Training performance results
Performance numbers below show throughput in users processed per second. They were averaged over an entire training run.
Training performance: NVIDIA DGX A100 (8x A100 40GB)
| GPUs | Batch size / GPU | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Strong scaling - TF32 | Strong scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 24,576 | 354,032 | 365,474 | 1.03 | 1 | 1 |
| 8 | 3,072 | 1,660,700 | 1,409,770 | 0.85 | 4.69 | 3.86 |
Training performance: NVIDIA DGX-1 (8x V100 32GB)
| GPUs | Batch size / GPU | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Strong scaling - FP32 | Strong scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 24,576 | 114,125 | 213,283 | 1.87 | 1 | 1 |
| 8 | 3,072 | 697,628 | 1,001,210 | 1.44 | 6.11 | 4.69 |
Inference performance results
Our results were obtained by running:
python main.py --inference_benchmark [--amp]
in the TensorFlow 20.06 NGC container.
We use users processed per second as a throughput metric for measuring inference performance. All latency numbers are in seconds.
Inference performance: NVIDIA DGX A100 (1x A100 40GB)
TF32
| Batch size | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| 1 | 1181 | 0.000847 | 0.000863 | 0.000871 | 0.000901 |
FP16
| Batch size | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| 1 | 1215 | 0.000823 | 0.000858 | 0.000864 | 0.000877 |
Inference performance: NVIDIA DGX-1 (1x V100 16GB)
FP32
| Batch size | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| 1 | 718 | 0.001392 | 0.001443 | 0.001458 | 0.001499 |
FP16
| Batch size | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| 1 | 707 | 0.001413 | 0.001511 | 0.001543 | 0.001622 |
Release notes
Changelog
July 2020
- Updated with Ampere convergence and performance results
November 2019
- Initial release
Known issues
AMP speedup for Ampere
In this model the TF32 precision can in some cases be as fast as the FP16 precision on Ampere GPUs. This is because TF32 also uses Tensor Cores and doesn't need any additional logic such as maintaining FP32 master weights and casts. However, please note that VAE-CF is, by modern recommender standards, a very small model. Larger models should still see significant benefits of using FP16 math.
Multi-GPU scaling
We benchmark this implementation on the ML-20m dataset so that our results are comparable to the original VAE-CF paper. We also use the same neural network architecture. As a consequence, the ratio of communication to computation is relatively large. This means that although using multiple GPUs speeds up the training substantially, the scaling efficiency is worse from what one would expect if using a larger model and a more realistic dataset.