28 KiB
UNet Industrial Defect Segmentation for TensorFlow
This repository provides a script and recipe to train UNet Industrial to achieve state of the art accuracy on the dataset DAGM2007, and is tested and maintained by NVIDIA.
Table of Contents
- Model overview
- Setup
- Quick Start Guide
- Advanced
- Performance
- Release notes
Model overview
This UNet model is adapted from the original version of the UNet model which is a convolutional auto-encoder for 2D image segmentation. UNet was first introduced by Olaf Ronneberger, Philip Fischer, and Thomas Brox in the paper: UNet: Convolutional Networks for Biomedical Image Segmentation.
This work proposes a modified version of UNet, called TinyUNet which performs efficiently and with very high accuracy
on the industrial anomaly dataset DAGM2007.
TinyUNet, like the original UNet is composed of two parts:
- an encoding sub-network (left-side)
- a decoding sub-network (right-side).
It repeatedly applies 3 downsampling blocks composed of two 2D convolutions followed by a 2D max pooling layer in the encoding sub-network. In the decoding sub-network, 3 upsampling blocks are composed of a upsample2D layer followed by a 2D convolution, a concatenation operation with the residual connection and two 2D convolutions.
TinyUNet has been introduced to reduce the model capacity which was leading to a high degree of over-fitting on a
small dataset like DAGM2007. The complete architecture is presented in the figure below:
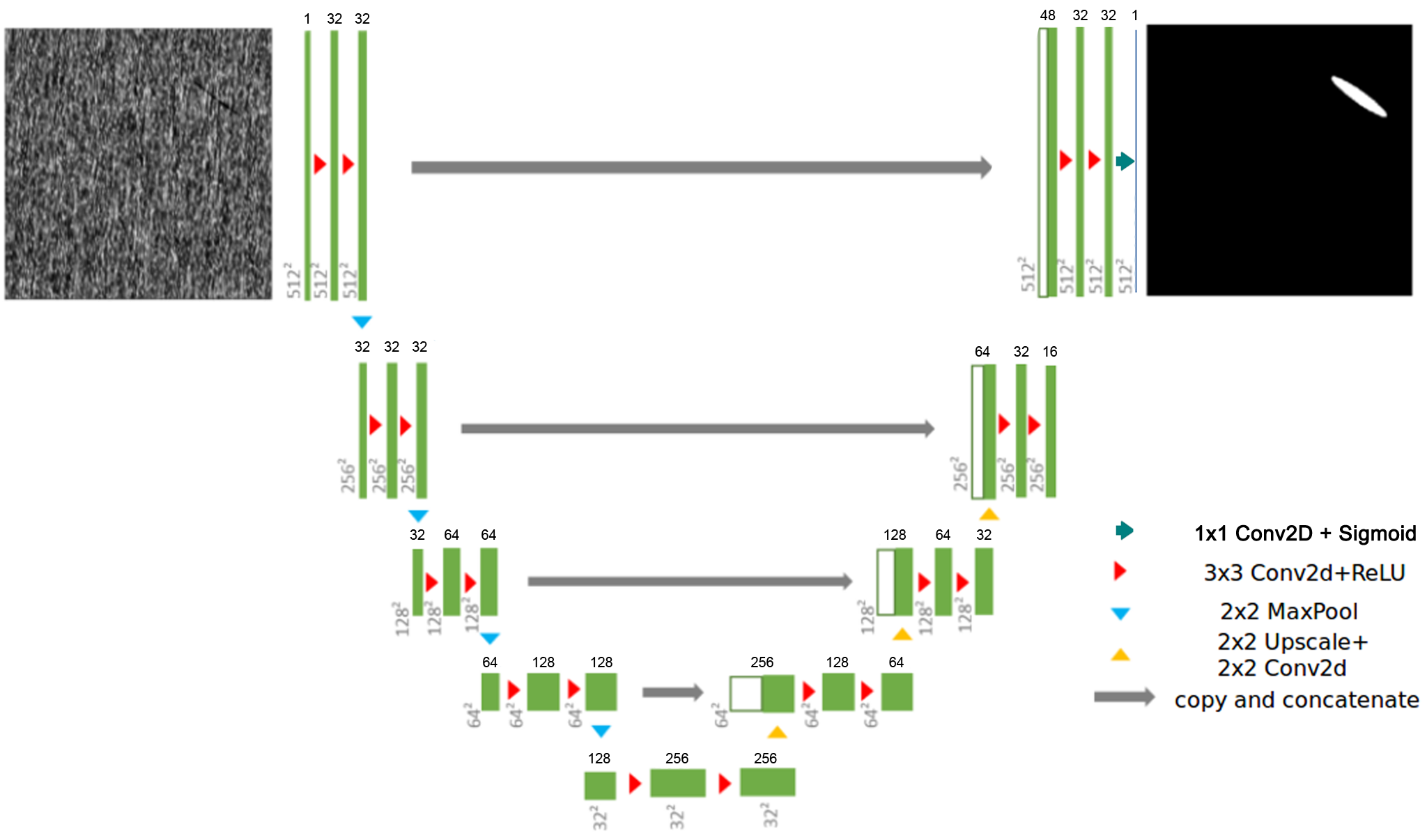
Figure 1. Architecture of the UNet Industrial
Default Configuration
This model trains in 2500 epochs, under the following setup:
-
Global Batch Size: 16
-
Optimizer RMSProp:
- decay: 0.9
- momentum: 0.8
- centered: True
-
Learning Rate Schedule: Exponential Step Decay
- decay: 0.8
- steps: 500
- initial learning rate: 1e-4
-
Weight Initialization: He Uniform Distribution (introduced by Kaiming He et al. in 2015 to address issues related ReLU activations in deep neural networks)
-
Loss Function: Adaptive
- When DICE Loss < 0.3, Loss = Binary Cross Entropy
- Else, Loss = DICE Loss
-
Data Augmentation
- Random Horizontal Flip (50% chance)
- Random Rotation 90°
-
Activation Functions:
- ReLU is used for all layers
- Sigmoid is used at the output to ensure that the ouputs are between [0, 1]
-
Weight decay: 1e-5
Feature support matrix
The following features are supported by this model.
| Feature | UNet Medical |
|---|---|
| Automatic mixed precision (AMP) | Yes |
| Horovod Multi-GPU (NCCL) | Yes |
| Accelerated Linear Algebra (XLA) | Yes |
Features
Automatic Mixed Precision (AMP)
This implementation of UNet uses AMP to implement mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying just a few lines of code.
Horovod
Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Multi-GPU training with Horovod
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial.
XLA support (experimental)
XLA is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes. The results are improvements in speed and memory usage: most internal benchmarks run ~1.1-1.5x faster after XLA is enabled.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta and Turing GPUs automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
This implementation exploits the TensorFlow Automatic Mixed Precision feature. In order to enable mixed precision training, the following environment variables must be defined with the correct value before the training starts:
TF_ENABLE_AUTO_MIXED_PRECISION=1
Exporting these variables ensures that loss scaling is performed correctly and automatically.
By supplying the --amp flag to the main.py script while training in FP32, the following variables are set to their correct value for mixed precision training:
if params.use_amp:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Setup
The following section lists the requirements in order to start training the UNet Medical model.
Requirements
This repository contains Dockerfile which extends the TensorFlow NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
- NVIDIA Docker
- TensorFlow 20.06-tf1-py3 NGC container
- GPU-based architecture:
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC container registry
- Running TensorFlow
For those unable to use the TensorFlow NGC container, to set up the required environment or create your own container, see the versioned NVIDIA Container Support Matrix.
Quick Start Guide
To train your model using mixed precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the UNet model on the EM segmentation challenge dataset. These steps enable you to build the UNet TensorFlow NGC container, train and evaluate your model, and generate predictions on the test data. Furthermore, you can then choose to:
- compare your evaluation accuracy with our Training accuracy results,
- compare your training performance with our Training performance benchmark,
- compare your inference performance with our Inference performance benchmark.
For the specifics concerning training and inference, see the Advanced section.
-
Clone the repository.
git clone https://github.com/NVIDIA/DeepLearningExamples cd DeepLearningExamples/TensorFlow/Segmentation/UNet_Industrial -
Build the UNet TensorFlow NGC container.
# Build the docker container docker build . --rm -t unet_industrial:latest -
Start an interactive session in the NGC container to run preprocessing/training/inference.
# make a directory for the dataset, for example ./dataset mkdir <path/to/dataset/directory> # make a directory for results, for example ./results mkdir <path/to/results/directory> # start the container with nvidia-docker nvidia-docker run -it --rm --gpus all \ --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 \ -v <path/to/dataset/directory>:/data/ \ -v <path/to/result/directory>:/results \ unet_industrial:latest -
Download and preprocess the dataset: DAGM2007
In order to download the dataset. You can execute the following:
./download_and_preprocess_dagm2007.sh /dataImportant Information: Some files of the dataset require an account to be downloaded, the script will invite you to download them manually and put them in the correct directory.
-
Start training.
To run training for a default configuration (as described in Default configuration, for example 1/4/8 GPUs,
FP32/TF-AMP), launch one of the scripts in the ./scripts directory called
./scripts/UNet{_AMP}_{1, 4, 8}GPU.sh
Each of the scripts requires three parameters:
- path to the results directory of the model as the first argument
- path to the dataset as a second argument
- class ID from DAGM used (between 1-10)
For example, for class 1:
cd scripts/
./UNet_1GPU.sh /results /data 1
- Run evaluation
Model evaluation on a checkpoint can be launched by running one of the scripts in the ./scripts directory
called ./scripts/UNet{_AMP}_EVAL.sh.
Each of the scripts requires three parameters:
- path to the results directory of the model as the first argument
- path to the dataset as a second argument
- class ID from DAGM used (between 1-10)
For example, for class 1:
cd scripts/
./UNet_EVAL.sh /results /data 1
Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
Command line options
To see the full list of available options and their descriptions, use the -h or --help command line option, for example:
python main.py --help
The following mandatory flags must be used to tune different aspects of the training:
general
--exec_mode=train_and_evaluate Which execution mode to run the model into.
--iter_unit=batch Will the model be run for X batches or X epochs ?
--num_iter=2500 Number of iterations to run.
--batch_size=16 Size of each minibatch per GPU.
--results_dir=/path/to/results Directory in which to write training logs, summaries and checkpoints.
--data_dir=/path/to/dataset Directory which contains the DAGM2007 dataset.
--dataset_name=DAGM2007 Name of the dataset used in this run (only DAGM2007 is supported atm).
--dataset_classID=1 ClassID to consider to train or evaluate the network (used for DAGM).
model
--amp Enable Automatic Mixed Precision to speedup FP32 computation using tensor cores.
--xla Enable TensorFlow XLA to maximise performance.
--use_auto_loss_scaling Use AutoLossScaling in TF-AMP
Dataset guidelines
The UNet model was trained with the Weakly Supervised Learning for Industrial Optical Inspection (DAGM 2007) dataset.
The competition is inspired by problems from industrial image processing. In order to satisfy their customers' needs, companies have to guarantee the quality of their products, which can often be achieved only by inspection of the finished product. Automatic visual defect detection has the potential to reduce the cost of quality assurance significantly.
The competitors have to design a stand-alone algorithm which is able to detect miscellaneous defects on various background textures.
The particular challenge of this contest is that the algorithm must learn, without human intervention, to discern defects automatically from a weakly labeled (i.e., labels are not exact to the pixel level) training set, the exact characteristics of which are unknown at development time. During the competition, the programs have to be trained on new data without any human guidance.
Source: https://resources.mpi-inf.mpg.de/conference/dagm/2007/prizes.html
The provided data is artificially generated, but similar to real world problems. It consists of multiple data sets, each consisting of 1000 images showing the background texture without defects, and of 150 images with one labeled defect each on the background texture. The images in a single data set are very similar, but each data set is generated by a different texture model and defect model.
Not all deviations from the texture are necessarily defects. The algorithm will need to use the weak labels provided during the training phase to learn the properties that characterize a defect.
Below are two sample images from two data sets. In both examples, the left images are without defects; the right ones contain a scratch-shaped defect which appears as a thin dark line, and a diffuse darker area, respectively. The defects are weakly labeled by a surrounding ellipse, shown in red.

The DAGM2007 challenge comes in propose two different challenges:
- A development set: public and available for download from here. The number of classes and sub-challenges for the development set is 6.
- A competition set: which requires an account to be downloaded from here. The number of classes and sub-challenges for the competition set is 10.
The challenge consists in designing a single model with a set of predefined hyper-parameters which will not change across the 10 different classes or sub-challenges of the competition set.
The performance shall be measured on the competition set which is normalized and more complex that the public dataset while offering the most unbiased evaluation method.
Training Process
Laplace Smoothing
We use this technique in the DICE loss to improve the training efficiency. This technique consists in replacing the epsilon parameter (used to avoid dividing by zero and very small: +/- 1e-7) by 1. You can find more information on: https://en.wikipedia.org/wiki/Additive_smoothing
Adaptive Loss
The DICE Loss is not able to provide a meaningful gradient at initialisation. This leads to a model instability which often push the model to diverge. Nonetheless, once the model starts to converge, DICE loss is able to very efficiently fully train the model. Therefore, we implemented an adaptive loss which is composed of two sub-losses:
- Binary Cross-Entropy (BCE)
- DICE Loss
The model is trained with the BCE loss until the DICE Loss reach a experimentally defined threshold (0.3). Thereafter, DICE loss is used to finish training.
Weak Labelling
This dataset is referred as weakly labelled. That means that the segmentation labels are not given at the pixel level but rather in an approximate fashion.
Performance
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA’s latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
The following sections shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark the inference performance, you can run one of the scripts in the ./scripts/benchmarking/ directory
called ./scripts/benchmarking/UNet_trainbench{_AMP}_{1, 4, 8}GPU.sh.
Each of the scripts requires three parameters:
- path to the dataset as the first argument
- class ID from DAGM used (between 1-10)
For example:
cd scripts/benchmarking/
./UNet_trainbench_1GPU.sh /data 1
Inference performance benchmark
To benchmark the training performance, you can run one of the scripts in the ./scripts/benchmarking/ directory
called ./scripts/benchmarking/UNet_evalbench{_AMP}.sh.
Each of the scripts requires three parameters:
- path to the dataset as the first argument
- class ID from DAGM used (between 1-10)
For example:
cd scripts/benchmarking/
./UNet_evalbench_AMP.sh /data 1
Results
The following sections provide details on the achieved results in training accuracy, performance and inference performance.
Training accuracy results
Training accuracy: NVIDIA DGX A100 (8x A100 40GB)
Our results were obtained by running the ./scripts/UNet{_AMP}_{1, 8}GPU.sh training
script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX A100 (8x A100 40GB) GPUs.
| GPUs | Batch size / GPU | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 [min] | Time to train - mixed precision [min] | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 16 | 0.9717 | 0.9726 | 3.6 | 2.3 | 1.57 |
| 8 | 2 | 0.9733 | 0.9683 | 4.3 | 3.5 | 1.23 |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the ./scripts/UNet{_AMP}_{1, 8}GPU.sh training
script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
| GPUs | Batch size / GPU | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 [min] | Time to train - mixed precision [min] | Time to train speedup (FP32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 16 | 0.9643 | 0.9653 | 10 | 8 | 1.25 |
| 8 | 2 | 0.9637 | 0.9655 | 2.5 | 2.5 | 1.00 |
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 40GB)
Our results were obtained by running the scripts
./scripts/benchmarking/UNet_trainbench{_AMP}_{1, 4, 8}GPU.sh training script in the
TensorFlow 20.06-tf1-py3 NGC container on NVIDIA DGX A100 (8x A100 40GB) GPUs.
| GPUs | Batch size / GPU | Throughput - TF32 [img/s] | Throughput - mixed precision [img/s] | Throughput speedup (TF32 - mixed precision) | Strong scaling - TF32 | Strong scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 16 | 135.95 | 255.26 | 1.88 | - | - |
| 4 | 4 | 420.2 | 691.19 | 1.64 | 3.09 | 2.71 |
| 8 | 2 | 655.05 | 665.66 | 1.02 | 4.82 | 2.61 |
Training performance: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the scripts
./scripts/benchmarking/UNet_trainbench{_AMP}_{1, 4, 8}GPU.sh training script in the
TensorFlow 20.06-tf1-py3 NGC container on an NVIDIA DGX-1 (8 V100 16GB) GPUs.
| GPUs | Batch size / GPU | Throughput - FP32 [img/s] | Throughput - mixed precision [img/s] | Throughput speedup (FP32 - mixed precision) | Strong scaling - FP32 | Strong scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 16 | 86.95 | 168.54 | 1.94 | - | - |
| 4 | 4 | 287.01 | 459.07 | 1.60 | 3.30 | 2.72 |
| 8 | 2 | 474.77 | 444.13 | 0.94 | 5.46 | 2.64 |
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance results
Inference performance results
Inference performance: NVIDIA DGX A100 (1x A100 40GB)
Our results were obtained by running the scripts ./scripts/benchmarking/UNet_evalbench{_AMP}.sh
evaluation script in the 20.06-tf1-py3 NGC container on NVIDIA DGX A100 (1x A100 40GB) GPUs.
FP16
| Batch size | Resolution | Throughput Avg [img/s] |
|---|---|---|
| 1 | 512x512x1 | 247.83 |
| 8 | 512x512x1 | 761.41 |
| 16 | 512x512x1 | 823.46 |
TF32
| Batch size | Resolution | Throughput Avg [img/s] |
|---|---|---|
| 1 | 512x512x1 | 227.97 |
| 8 | 512x512x1 | 419.70 |
| 16 | 512x512x1 | 424.57 |
To achieve these same results, follow the steps in the Quick Start Guide.
Inference performance: NVIDIA DGX-1 (1x V100 16GB)
Our results were obtained by running the scripts ./scripts/benchmarking/UNet_evalbench{_AMP}.sh
evaluation script in the 20.06-tf1-py3 NGC container on NVIDIA DGX-1 (1x V100 16GB) GPUs.
FP16
| Batch size | Resolution | Throughput Avg [img/s] |
|---|---|---|
| 1 | 512x512x1 | 157.91 |
| 8 | 512x512x1 | 438.00 |
| 16 | 512x512x1 | 469.27 |
FP32
| Batch size | Resolution | Throughput Avg [img/s] |
|---|---|---|
| 1 | 512x512x1 | 159.65 |
| 8 | 512x512x1 | 243.99 |
| 16 | 512x512x1 | 250.23 |
To achieve these same results, follow the Quick Start Guide outlined above.
Release notes
Changelog
June 2020
- Updated training and inference accuracy with A100 results
- Updated training and inference performance with A100 results
October 2019
- Jupyter notebooks added
March,2019
- Initial release
Known issues
There are no known issues with this model.