5.7 KiB
Convolutional Network for Image Classification in PyTorch
In this repository you will find implementations of various image classification models.
Detailed information on each model can be found here:
Table Of Contents
Models
The following table provides links to where you can find additional information on each model:
| Model | Link |
|---|---|
| resnet50 | README |
| resnext101-32x4d | README |
| se-resnext101-32x4d | README |
| EfficientNet | README |
Validation accuracy results
Our results were obtained by running the applicable training scripts in the [framework-container-name] NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs. The specific training script that was run is documented in the corresponding model's README.
The following table shows the validation accuracy results of the three classification models side-by-side.
| Model | Mixed Precision Top1 | Mixed Precision Top5 | 32 bit Top1 | 32 bit Top5 |
|---|---|---|---|---|
| efficientnet-b0 | 77.63 | 93.82 | 77.31 | 93.76 |
| efficientnet-b4 | 82.98 | 96.44 | 82.92 | 96.43 |
| efficientnet-widese-b0 | 77.89 | 94.00 | 77.97 | 94.05 |
| efficientnet-widese-b4 | 83.28 | 96.45 | 83.30 | 96.47 |
| resnet50 | 78.60 | 94.19 | 78.69 | 94.16 |
| resnext101-32x4d | 80.43 | 95.06 | 80.40 | 95.04 |
| se-resnext101-32x4d | 81.00 | 95.48 | 81.09 | 95.45 |
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the applicable training scripts in the pytorch-20.12 NGC container on NVIDIA DGX A100 with (8x A100 80GB) GPUs. Performance numbers (in images per second) were averaged over an entire training epoch. The specific training script that was run is documented in the corresponding model's README.
The following table shows the training accuracy results of the three classification models side-by-side.
| Model | Mixed Precision | TF32 | Mixed Precision Speedup |
|---|---|---|---|
| efficientnet-b0 | 14391 img/s | 8225 img/s | 1.74 x |
| efficientnet-b4 | 2341 img/s | 1204 img/s | 1.94 x |
| efficientnet-widese-b0 | 15053 img/s | 8233 img/s | 1.82 x |
| efficientnet-widese-b4 | 2339 img/s | 1202 img/s | 1.94 x |
| resnet50 | 15977 img/s | 7365 img/s | 2.16 x |
| resnext101-32x4d | 7399 img/s | 3193 img/s | 2.31 x |
| se-resnext101-32x4d | 5248 img/s | 2665 img/s | 1.96 x |
Training performance: NVIDIA DGX-1 16G (8x V100 16GB)
Our results were obtained by running the applicable training scripts in the pytorch-20.12 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs. Performance numbers (in images per second) were averaged over an entire training epoch. The specific training script that was run is documented in the corresponding model's README.
The following table shows the training accuracy results of the three classification models side-by-side.
| Model | Mixed Precision | FP32 | Mixed Precision Speedup |
|---|---|---|---|
| efficientnet-b0 | 7664 img/s | 4571 img/s | 1.67 x |
| efficientnet-b4 | 1330 img/s | 598 img/s | 2.22 x |
| efficientnet-widese-b0 | 7694 img/s | 4489 img/s | 1.71 x |
| efficientnet-widese-b4 | 1323 img/s | 590 img/s | 2.24 x |
| resnet50 | 7608 img/s | 2851 img/s | 2.66 x |
| resnext101-32x4d | 3742 img/s | 1117 img/s | 3.34 x |
| se-resnext101-32x4d | 2716 img/s | 994 img/s | 2.73 x |
Model Comparison
Accuracy vs FLOPS
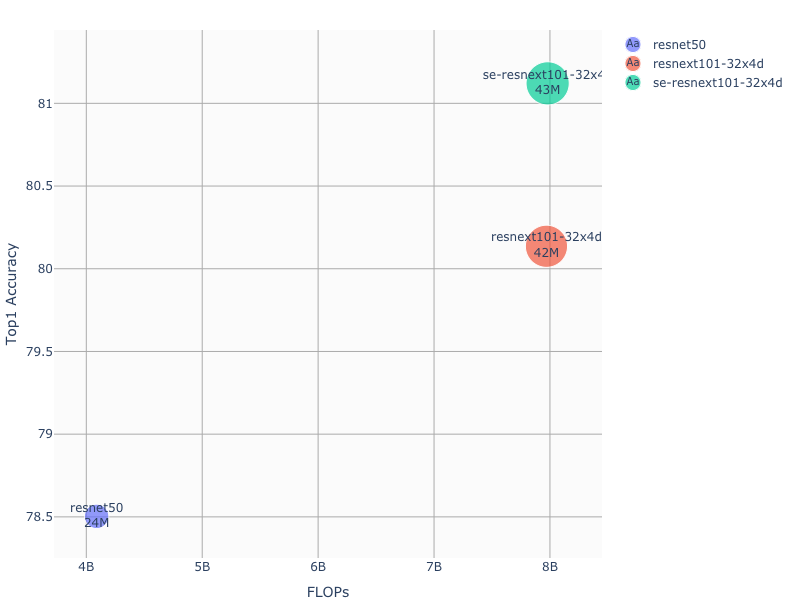
Plot describes relationship between floating point operations needed for computing forward pass on a 224px x 224px image, for the implemented models. Dot size indicates number of trainable parameters.
Latency vs Throughput on different batch sizes
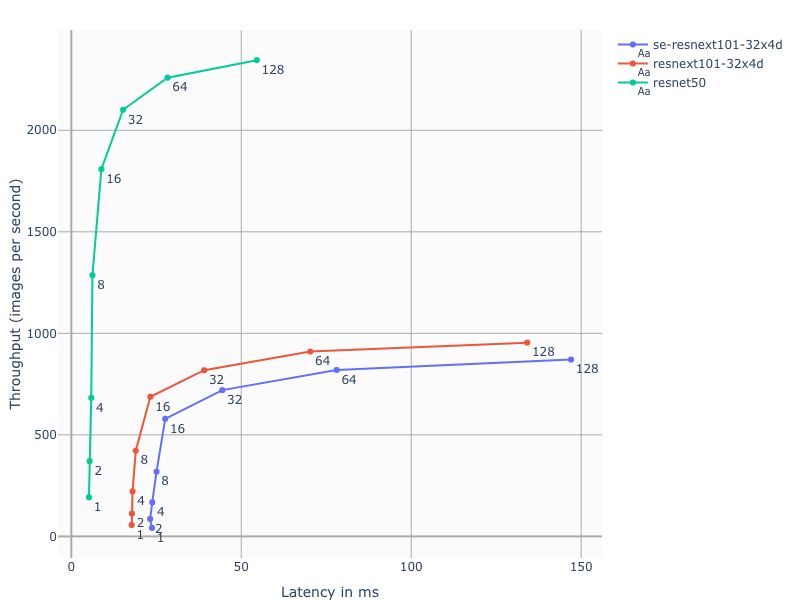
Plot describes relationship between inference latency, throughput and batch size for the implemented models.